基于 Docker 安装 Kubernetes(v1.25)
- 操作系统是 CentOS 7.9 。
- 使用到的资源在这里附件.zip 。
第一章:前置知识
1.1 Kubernetes 的组件
1.1.1 简介
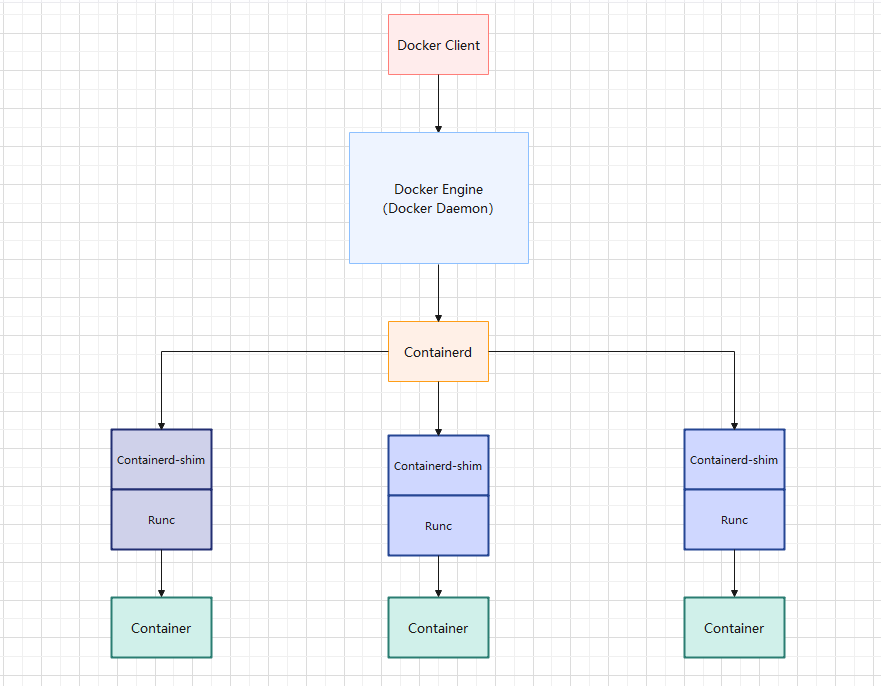
- Docker 的运行机制:

- Kubernetes 的组件:

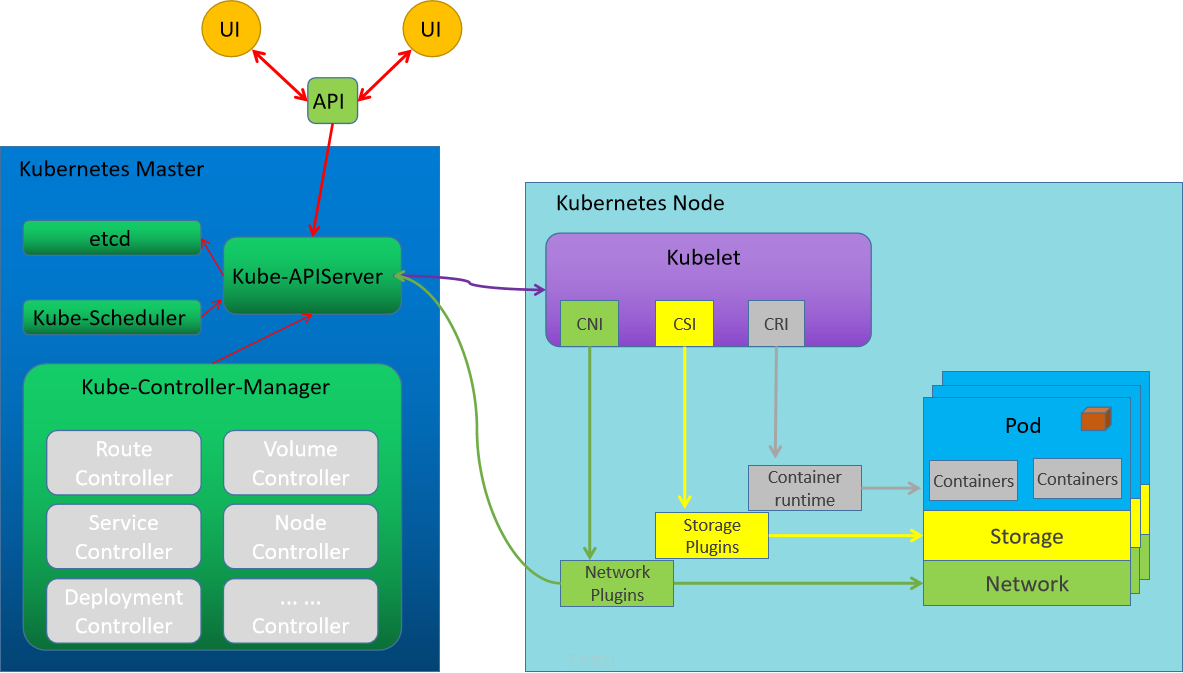
- Kubernetes 提供了三个特定功能的接口,Kubernetes 通过调用这几个接口,来完成相应的功能:
- CRI(Container Runtime Interface):容器运行时接口,Kubernetes 对于容器的解决方案就是预留了容器接口,只要符合 CRI 标准的解决方案即可。
- CNI(Container Network Interface):容器网络接口,Kubernetes 对于网络的解决方案就是预留了网络接口,只要符合 CNI 标准的解决方案即可。
- CSI(Container Storage Interface):容器存储接口,Kubernetes 对于网络的解决方案就是预留了存储接口,只要符合 CSI标准的解决方案即可。
1.1.2 容器运行时接口(CRI)
- CRI 是 Kubernetes 定义的一组 gRPC 服务。Kubelet 作为客户端,基于 gRPC 协议通过 Socket 和容器运行时通信。
- CRI 是一个插件接口,它使 kubelet 能够使用各种容器运行时,无需重新编译集群组件。
- Kubernetes 集群中需要在每个节点上都有一个可以正常工作的容器运行时, 这样 kubelet 能启动 Pod 及其容器。
- 容器运行时接口(CRI)是 kubelet 和容器运行时之间通信的主要协议。
- CRI 包括两类服务:镜像服务(Image Service)和运行时服务(Runtime Service)。
- 镜像服务:提供下载、检查和删除镜像的远程程序调用。
- 运行时服务:包含用于管理容器生命周期,以及与容器交互的调用的远程程序调用。
- OCI(Open Container Initiative,开放容器计划)定义了创建容器的格式和运行时的开源行业标准,包 括镜像规范(Image Specification)和运行时规范(Runtime Specification)。
- 对于容器运行时主要有两个级别:Low Level(使用接近内核层)和 High Level(使用接近用户层)。目前,市面上常用的容器引擎有很多,主要有下图的那几种。

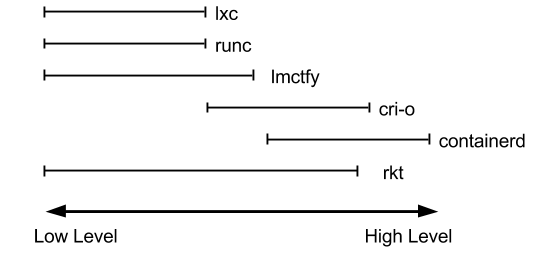
- dockershim, containerd 和cri-o 都是遵循 CRI 的容器运行时,我们称它们为高层级运行时(High-level Runtime)。
- 其他的容器运营厂商最底层的 runc 仍然是 Docker 在维护。
- Google、CoreOS、RedHat 都推出自已的运行时(lmctfy、rkt、cri-o),但到目前 Docker 仍然是最主流的容器引擎技术。

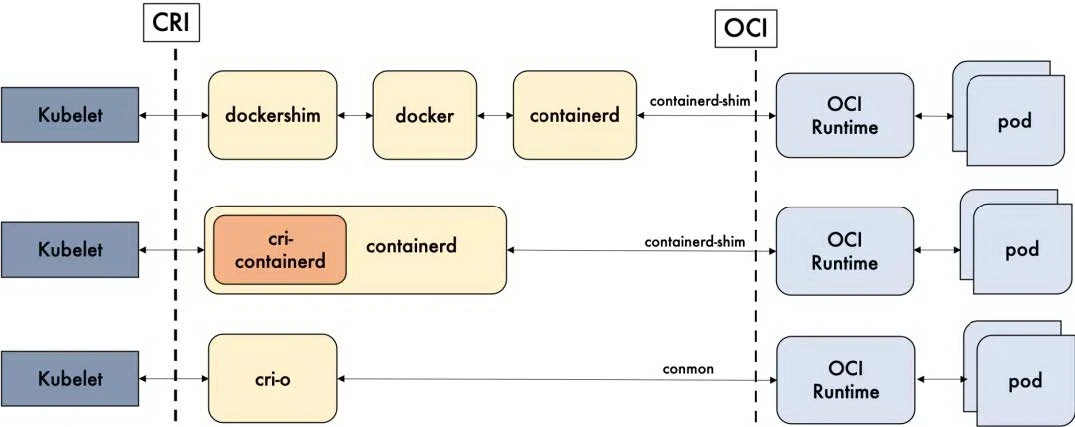
1.2 Kubernetes 1.24 之后不在支持 Docker?
- Kubernetes 和 Docker 的发展史:

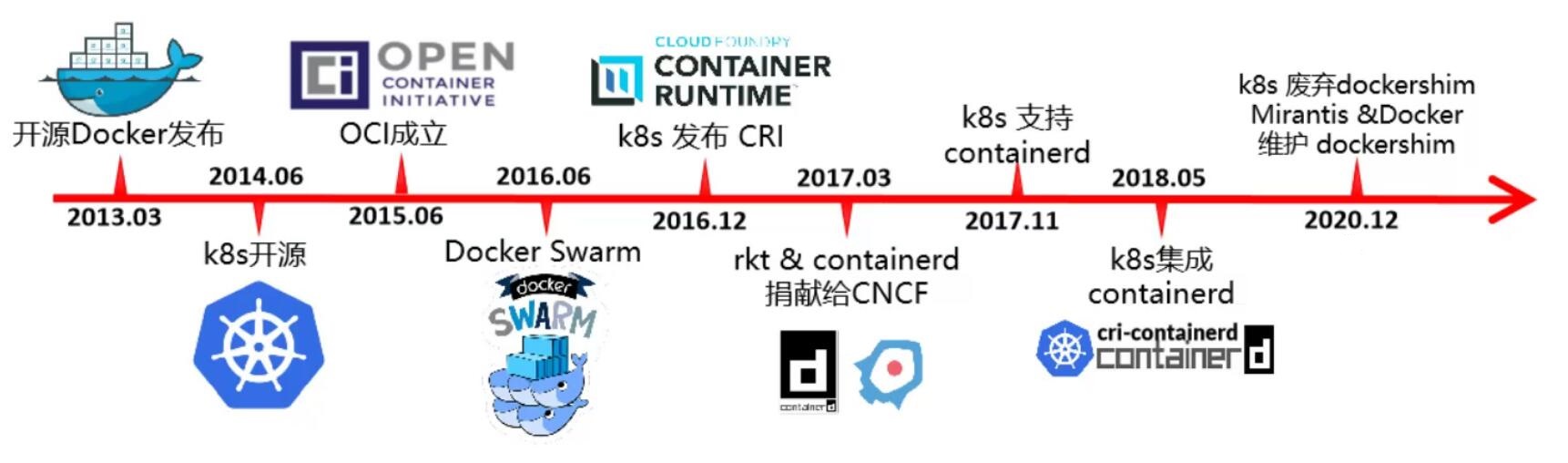
- 2014 年是 Docker 和 Kubernetes 的蜜月期。
- 2015 - 2016 年, Kubernetes & RKT VS Docker,最终 Docker 胜出。
- 2016 年,Kubernetes 逐渐赢得任务编排的胜利。
- 2017 年,rkt 和 containerd 捐献给 CNCF。
- 2020 年, Kubernetes 宣布废弃dockershim,但 Mirantis 和 Docker 宣布维护 dockershim。
- 2022 年 5 月 3 日,Kubernetes v1.24 正式发布,正式移除对 dockershim 的支持,即默认不再支持 Docker。
- ……
1.3 Kubernetes 调用 Docker 的变化
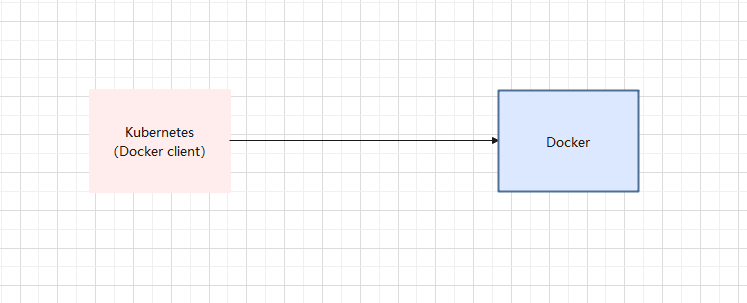
- 早期的时候,Kubernetes 集成了 Docker 的客户端:

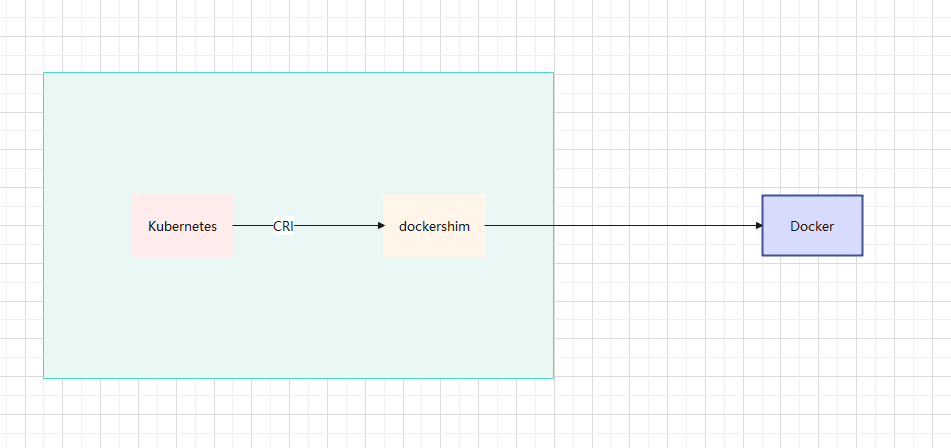
- 随着时间的推移,Kubernetes 提出了 CRI(Container Runtime Interface,容器运行时接口),然后通过 dockershim(Kubernetes 维护,并自带) 去调用 Docker。

- 之后,Kubernetes 将 dockershim 作为依赖(Kubernetes 维护),然后通过 dockershim 去调用 Docker。

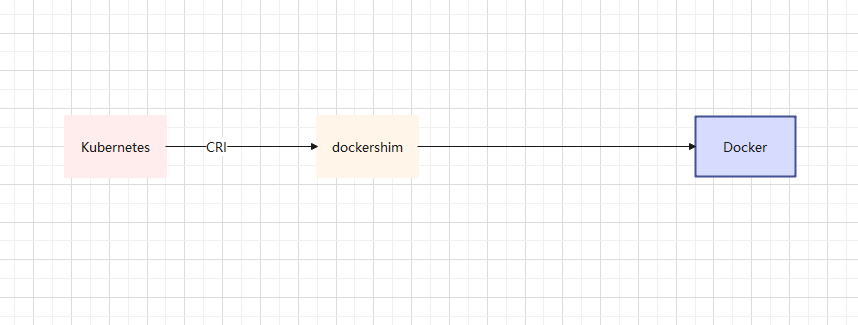
- 目前,dockershim 被 Kubernetes 官方宣布废弃,但是 Docker 宣布维护(项目就是 cri-dockerd)。

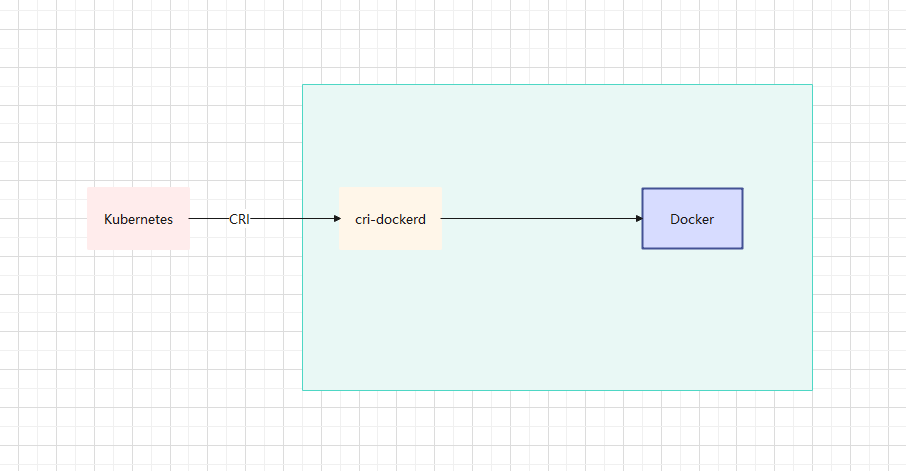
1.4 Kubernetes 集群的创建方案
- 示意图:

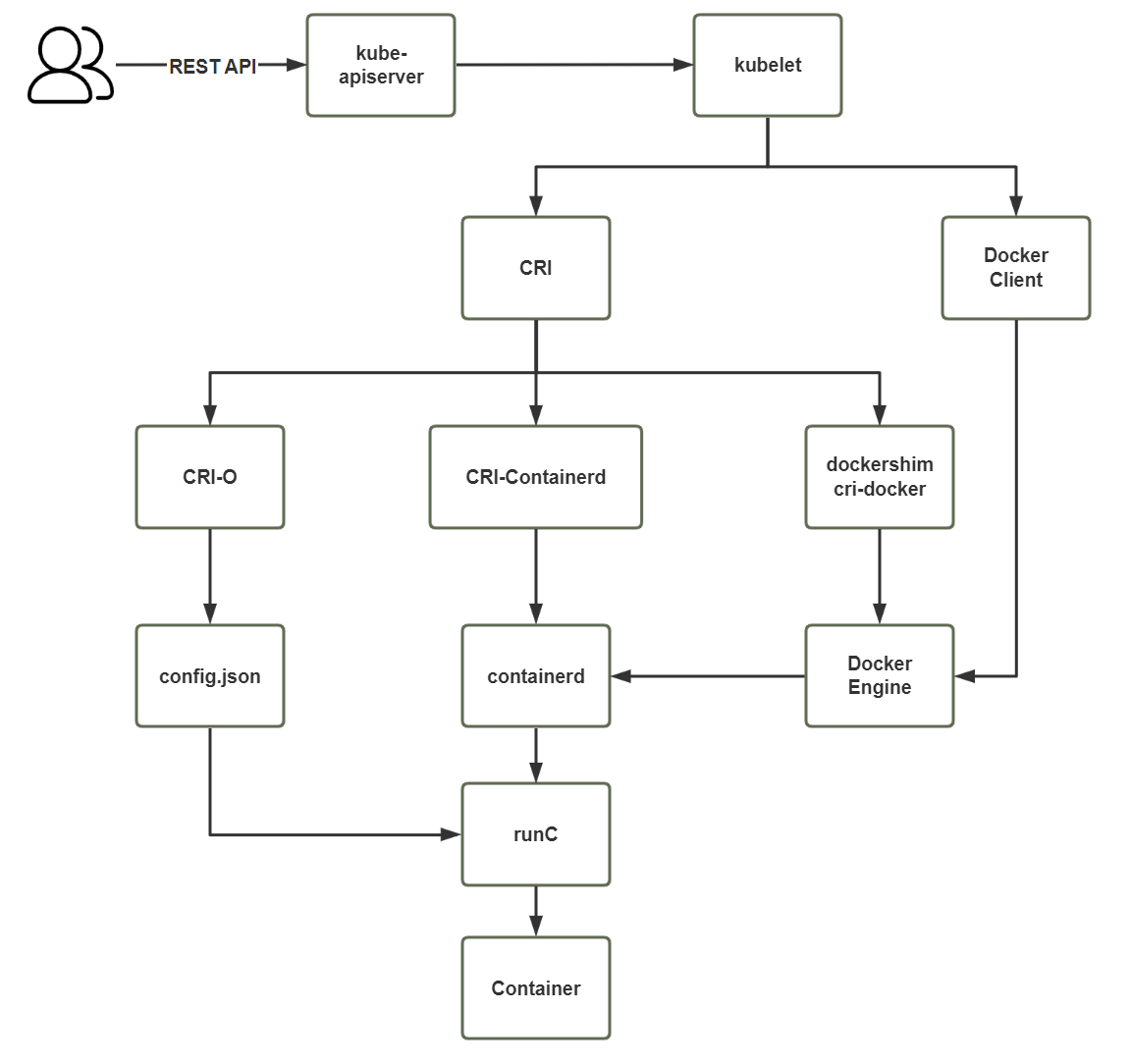
- 方式 1:Containerd,默认情况下,Kubernetes 在创建集群的时候,使用的就是 Containerd 方式。
- 方式 2:Docker,Docker 使用的普及率较高,虽然 Kubernetes-v1.24 默认情况下废弃了 kubelet 对于 Docker 的支持,但是我们还可以借助于 Mirantis 维护的 cri-dockerd 插件方式来实现 Kubernetes 集群的创建。Docker Engine 没有实现 CRI, 而这是容器运行时在 Kubernetes 中工作所需要的。 为此,必须安装一个额外的服务 cri-dockerd。 cri-dockerd 是一个基于传统的内置 Docker 引擎支持的项目, 它在 1.24 版本从 kubelet 中移除。
- 方式 3::CRI-O,CRI-O 的方式是 Kubernetes 创建容器最直接的一种方式,在创建集群的时候,需要借助于 cri-o 插件的方式来实现 Kubernetes 集群的创建。
第二章:环境规划
2.1 集群类型
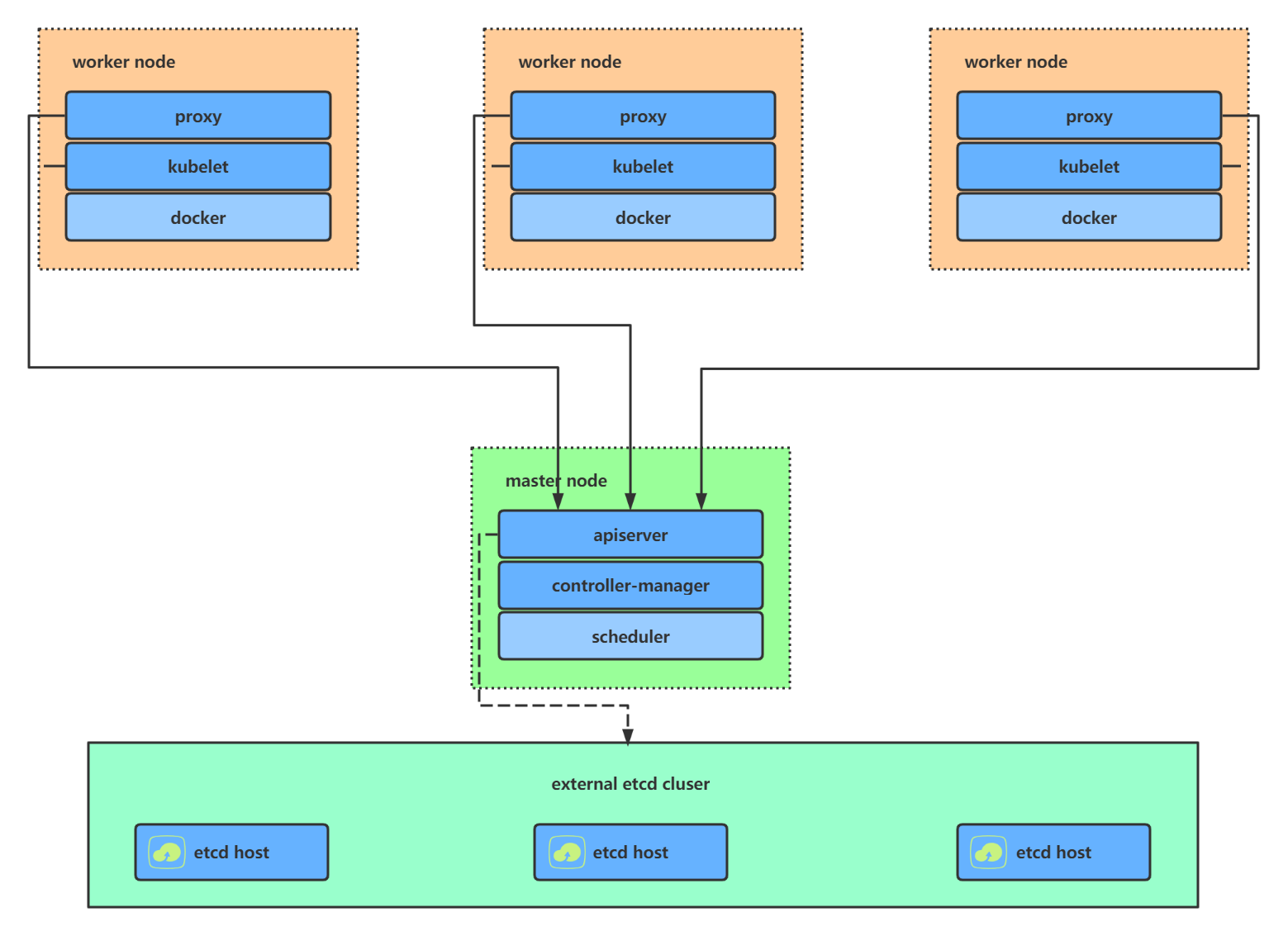
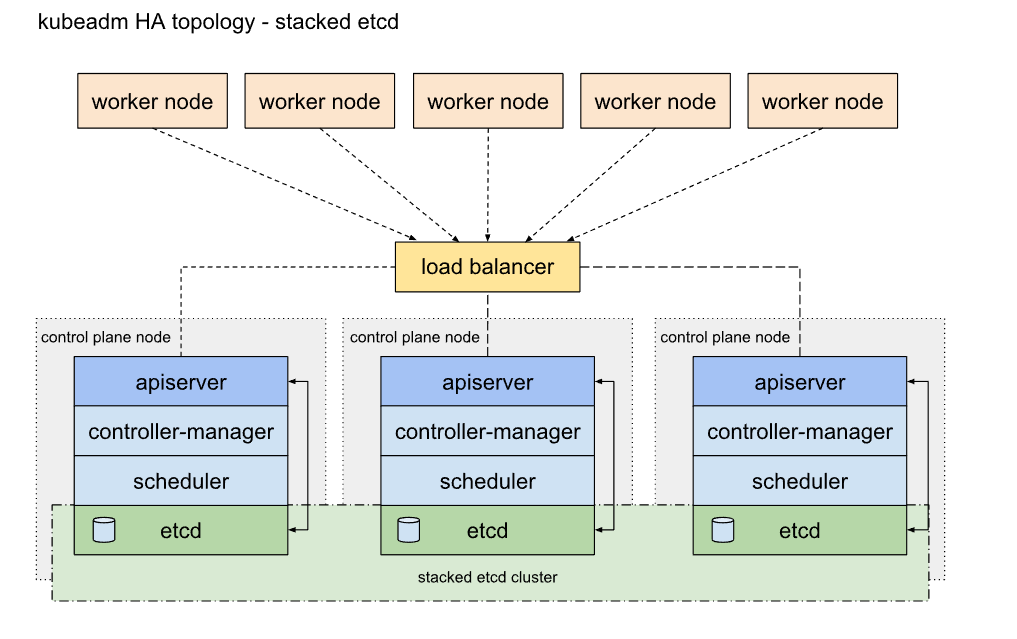
- Kubernetes 集群大致分为两类:一主多从和多主多从。
- 一主多从(单 master ):一个 Master 节点和多台 Node 节点,搭建简单,但是有单机故障风险,适合用于测试环境。
- 多主多从(高可用):多台 Master 节点和多台 Node 节点,搭建麻烦,安全性高,适合用于生产环境。
- 单 master 的架构图:

- 高可用集群的架构图:

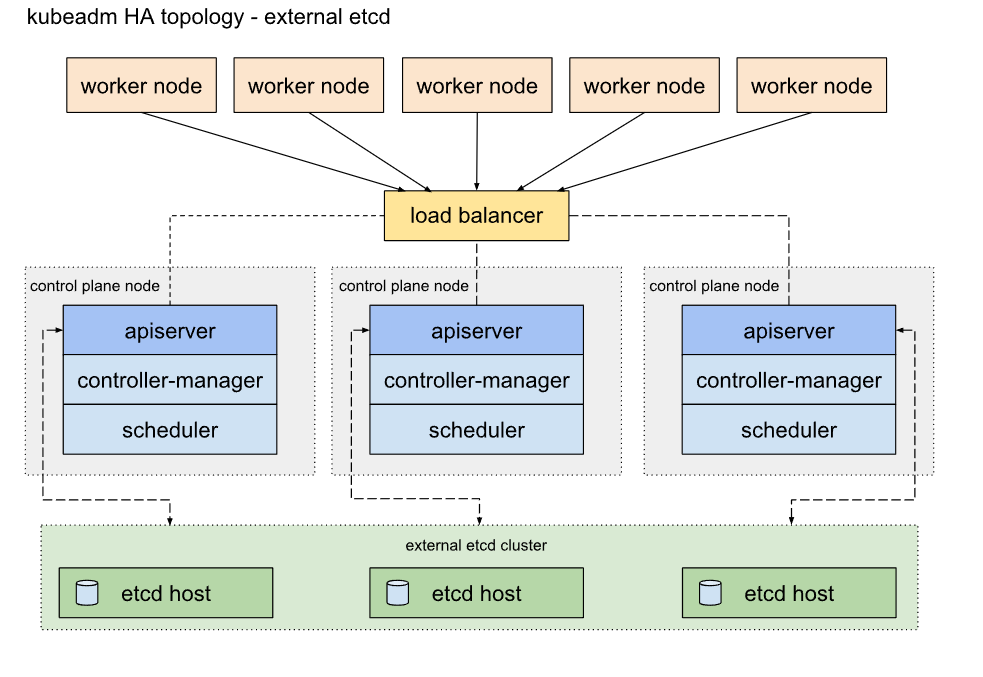

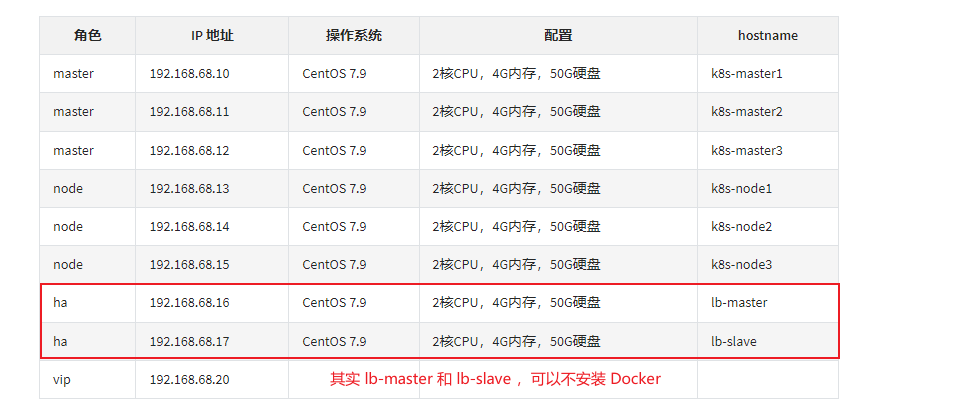
2.2 主机规划
- 主机规划:
| 角色 | IP 地址 | 操作系统 | 配置 | hostname |
|---|---|---|---|---|
| master | 192.168.68.10 | CentOS 7.9 | 2核CPU,3G内存,50G硬盘 | k8s-master1 |
| master | 192.168.68.11 | CentOS 7.9 | 2核CPU,3G内存,50G硬盘 | k8s-master2 |
| master | 192.168.68.12 | CentOS 7.9 | 2核CPU,3G内存,50G硬盘 | k8s-master3 |
| node | 192.168.68.13 | CentOS 7.9 | 2核CPU,3G内存,50G硬盘 | k8s-node1 |
| node | 192.168.68.14 | CentOS 7.9 | 2核CPU,3G内存,50G硬盘 | k8s-node2 |
| node | 192.168.68.15 | CentOS 7.9 | 2核CPU,3G内存,50G硬盘 | k8s-node3 |
| ha | 192.168.68.16 | CentOS 7.9 | 2核CPU,3G内存,50G硬盘 | lb-master |
| ha | 192.168.68.17 | CentOS 7.9 | 2核CPU,3G内存,50G硬盘 | lb-slave |
| vip | 192.168.68.20 |
说明:如果是本地虚拟机搭建,可以使用 VBR 技术,常见的有 Haproxy + Keepalived 或 Nginx + Keepalived ;但是,如果是在云厂商提供的机器中,就需要使用 VPC 了。
- 本次 Kubernetes 集群的架构图:

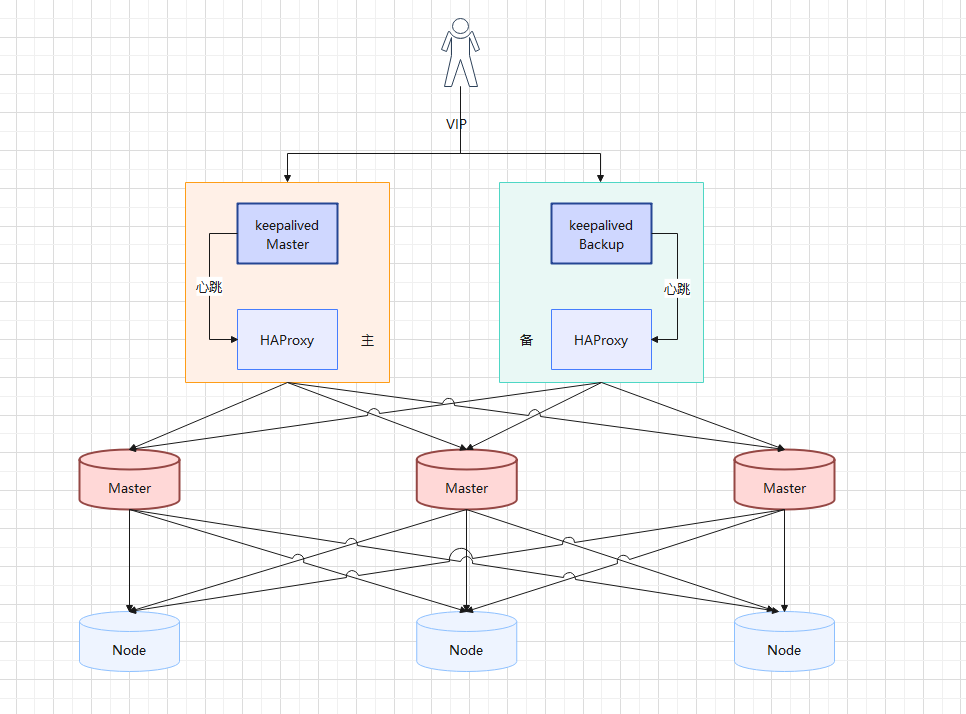
第三章:前置准备
3.1 升级系统内核
- 查看当前系统的版本:

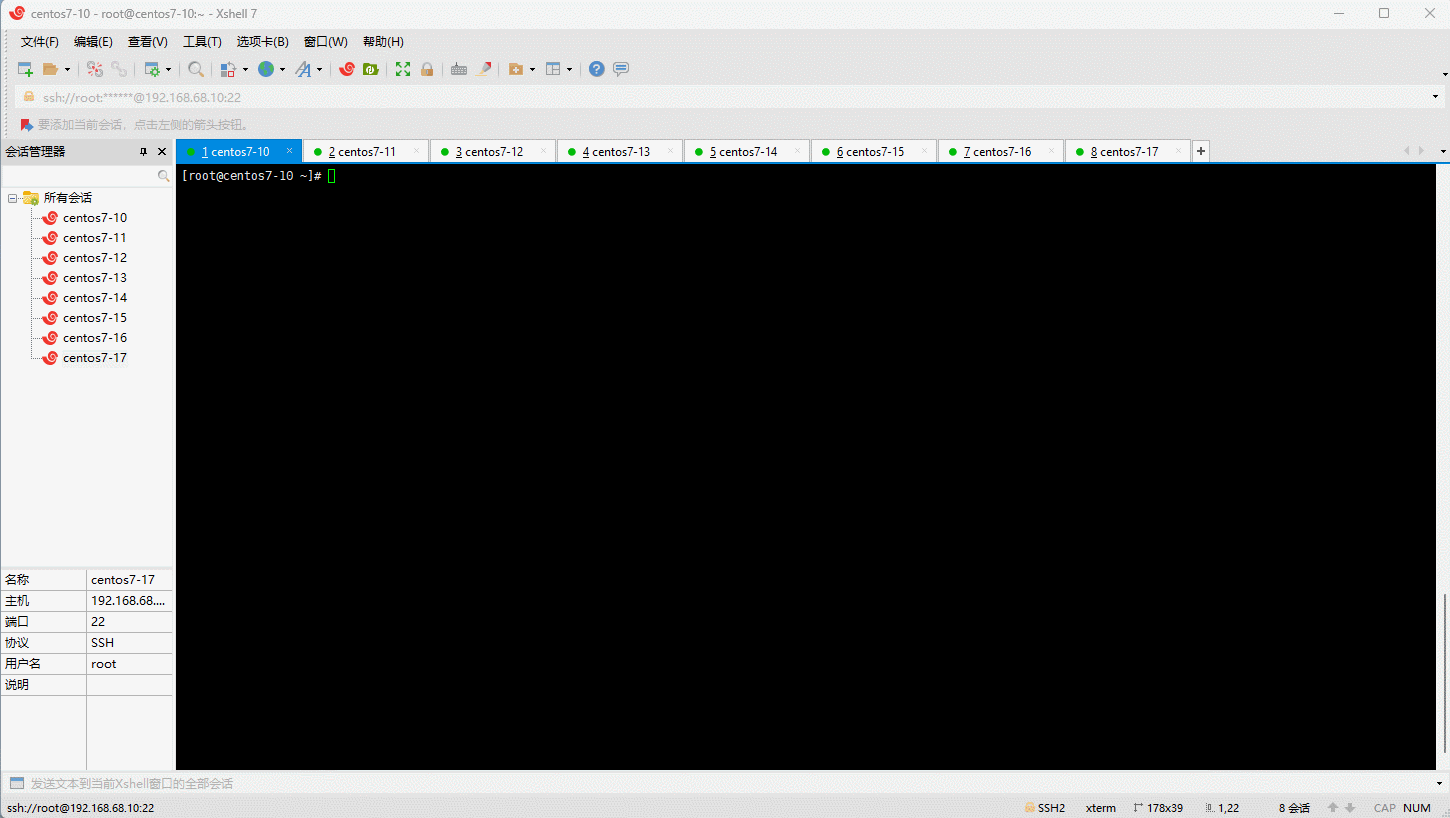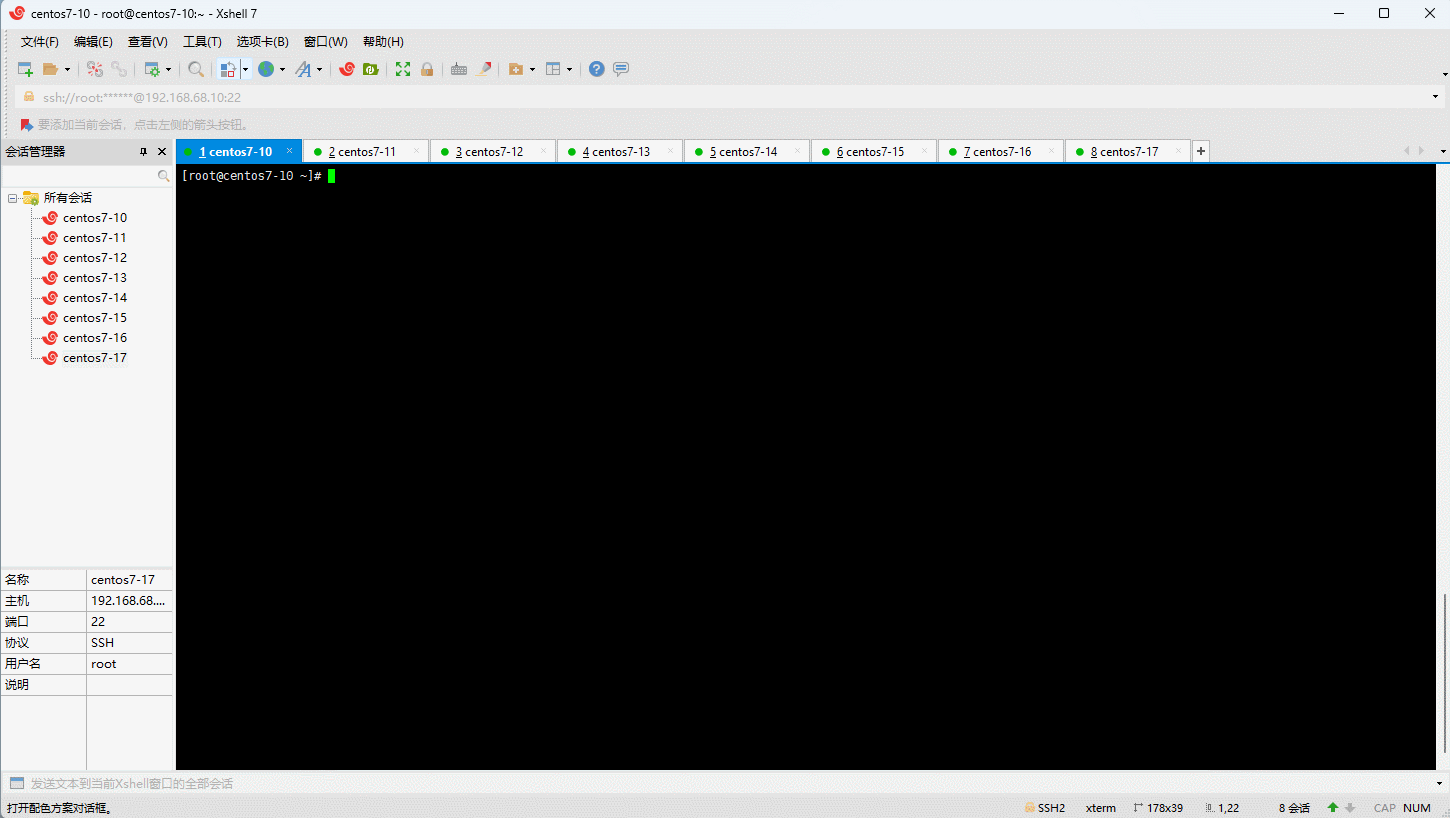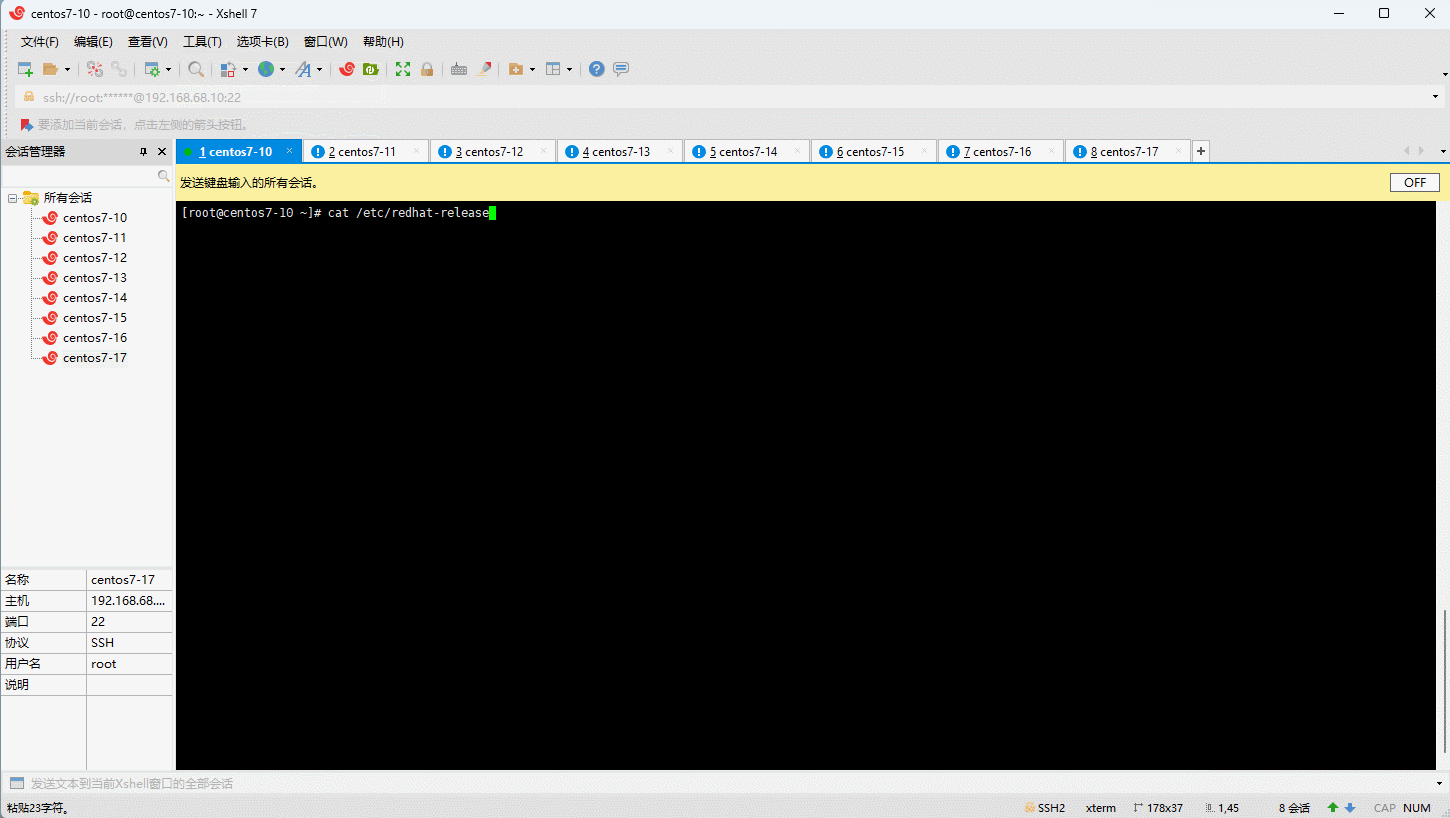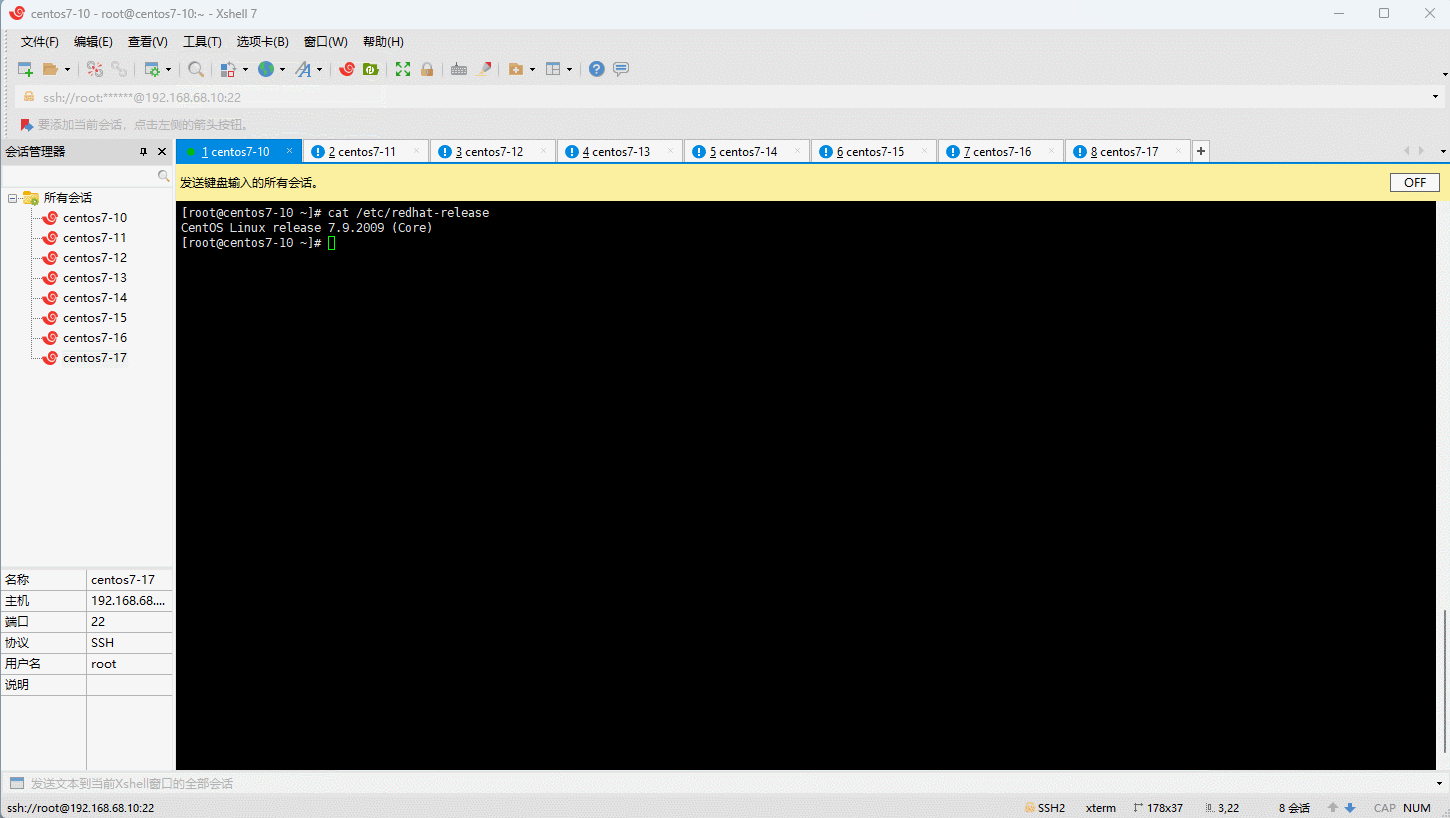
- 查看当前系统的内核:

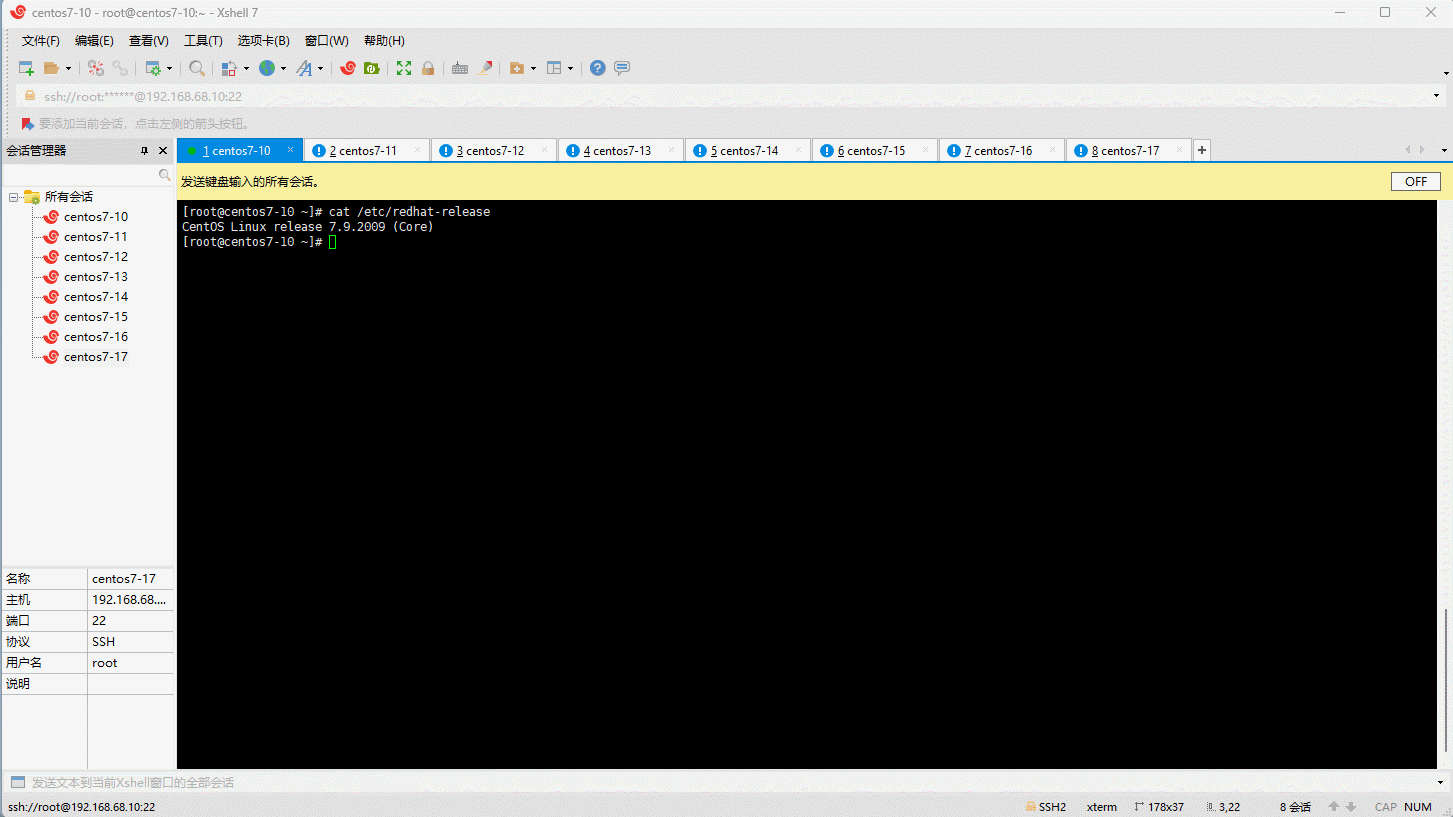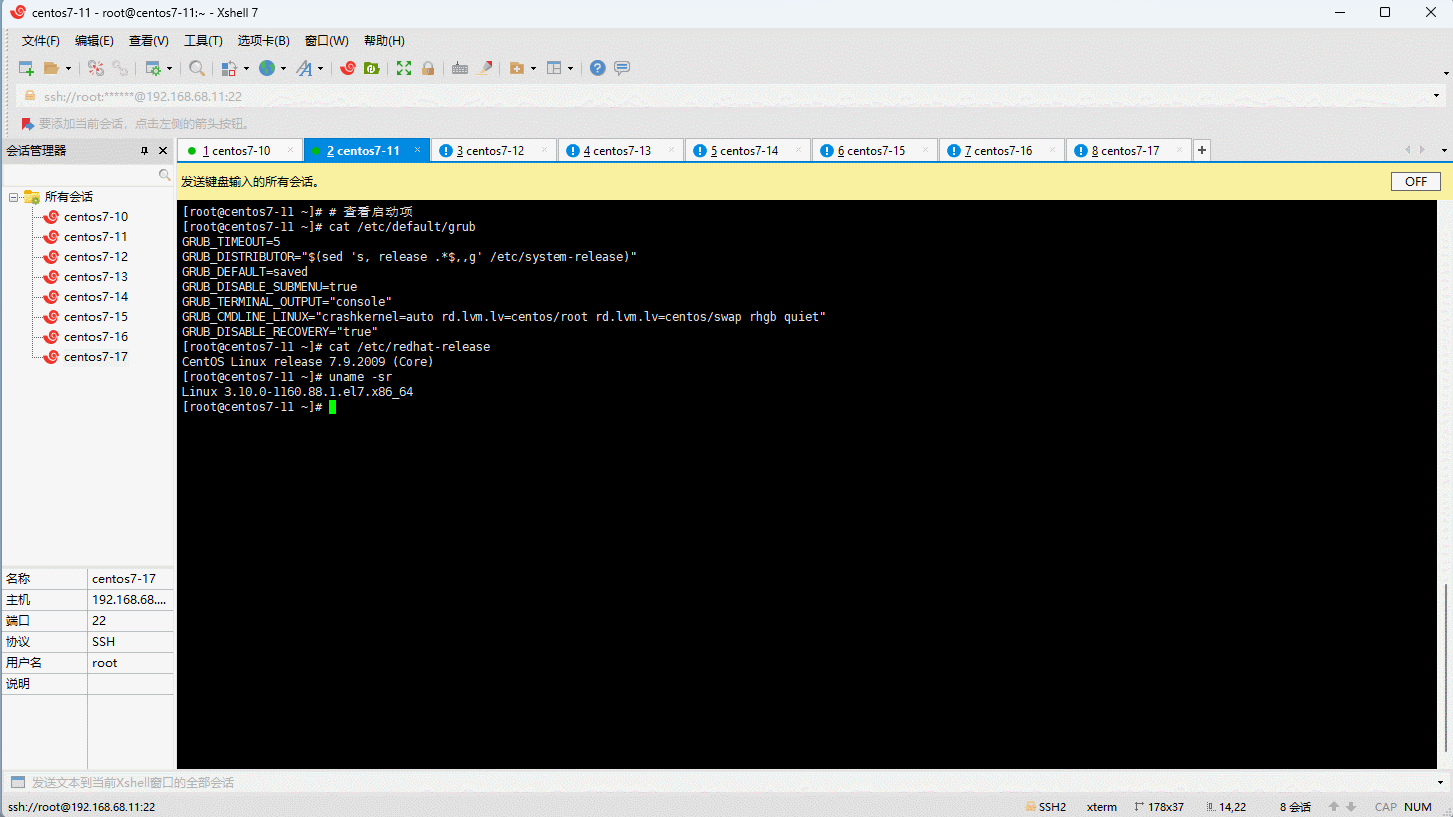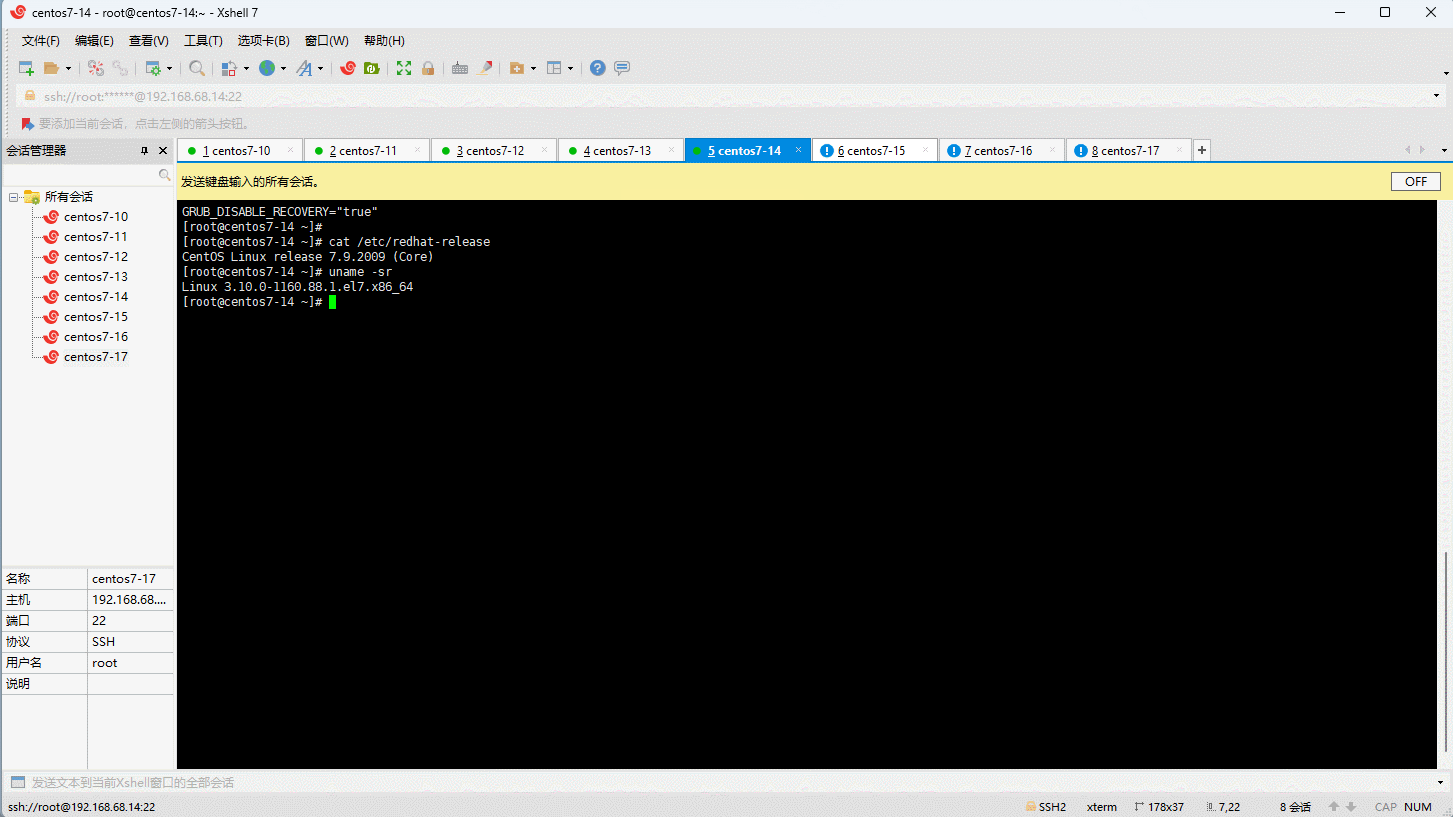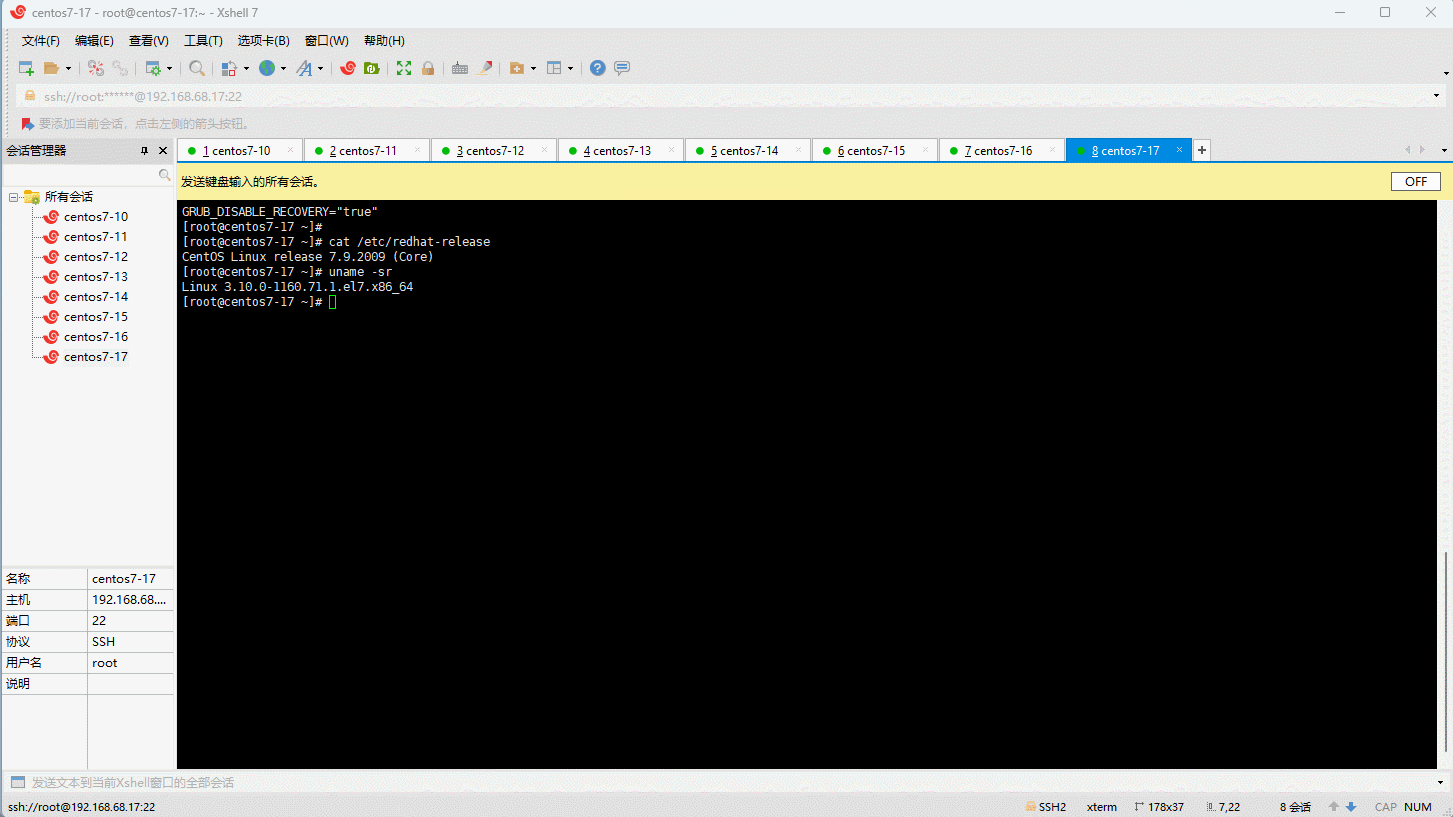
- 在 CentOS 7.x 上启用 ELRepo 仓库:

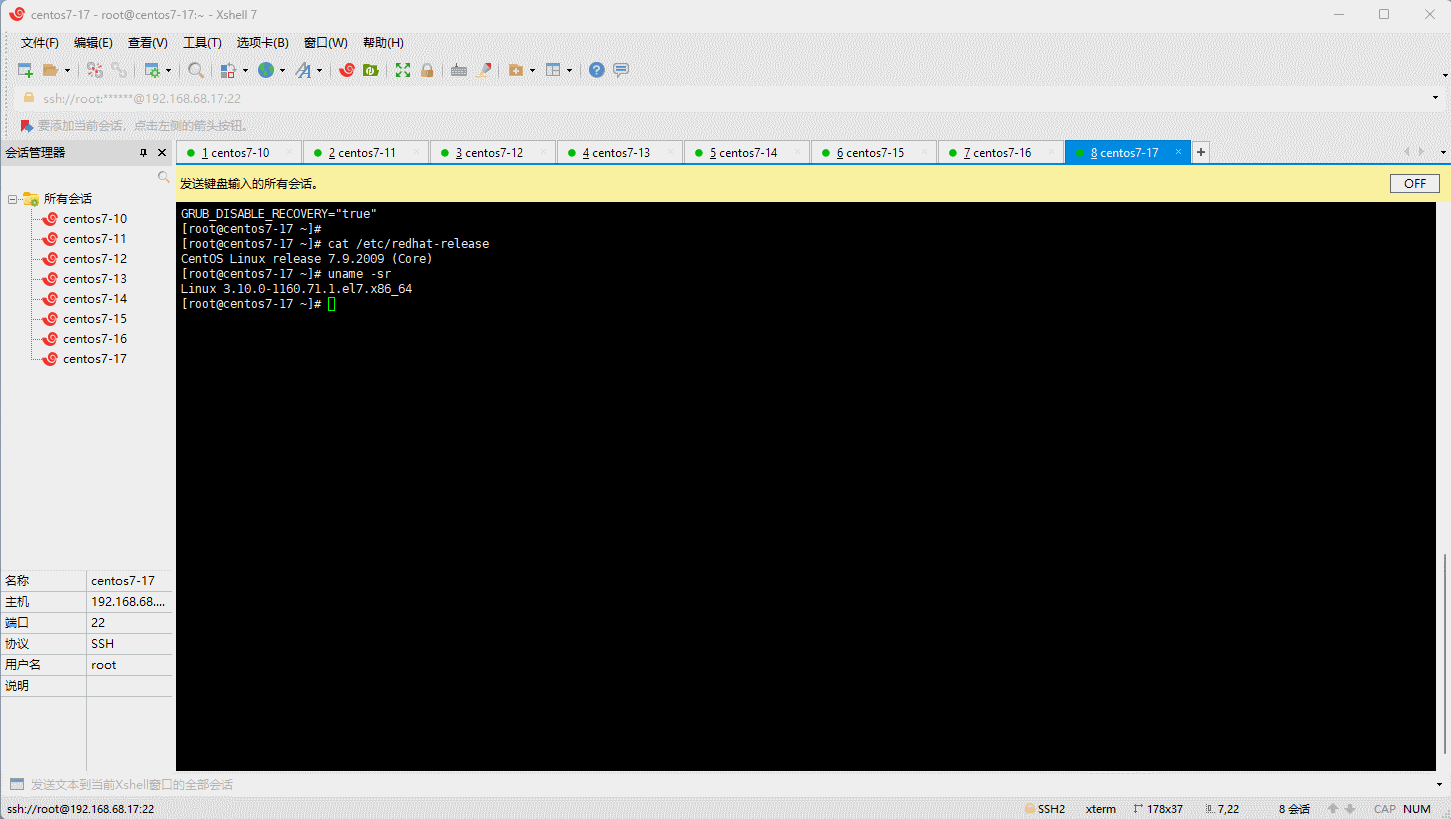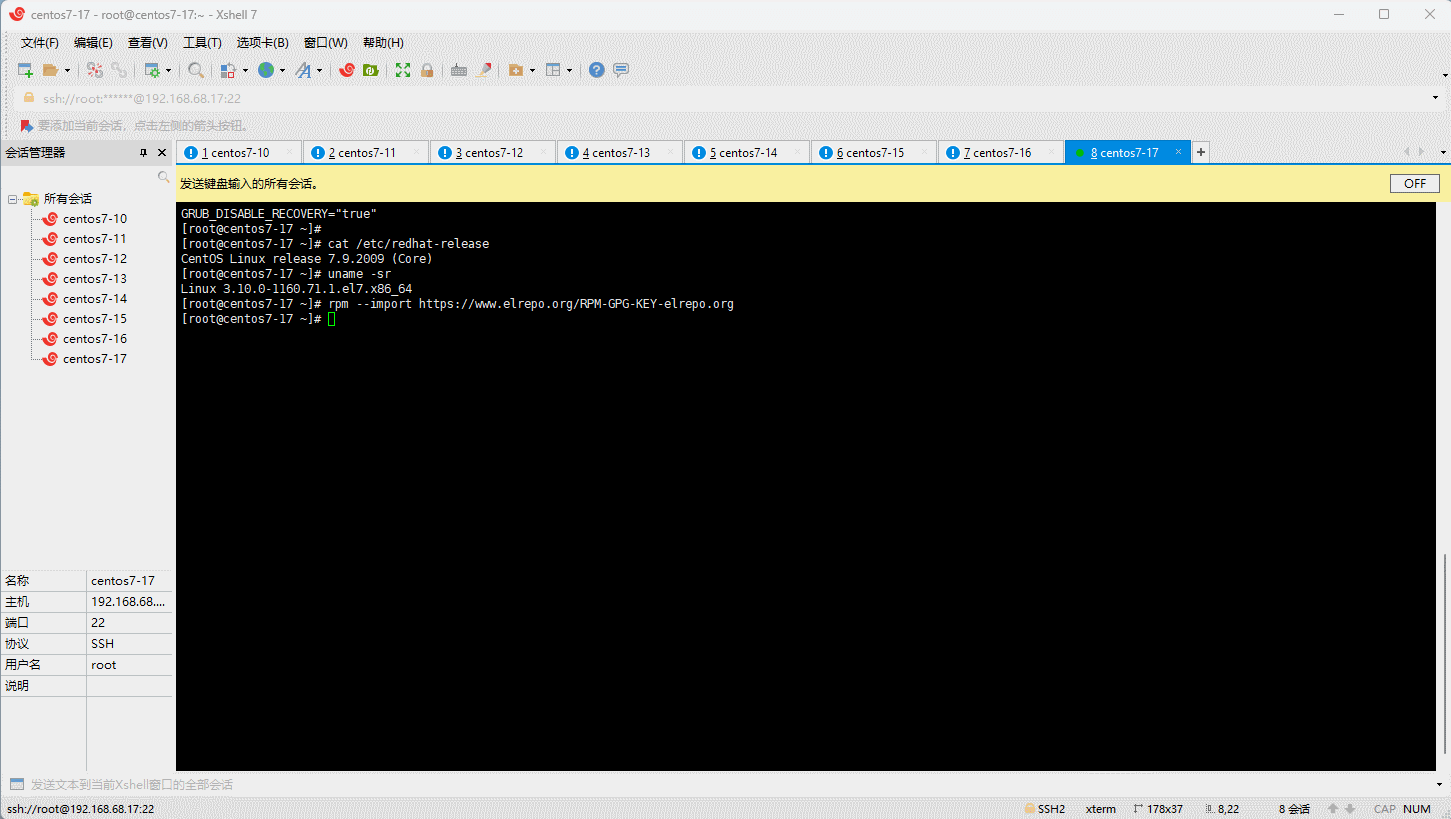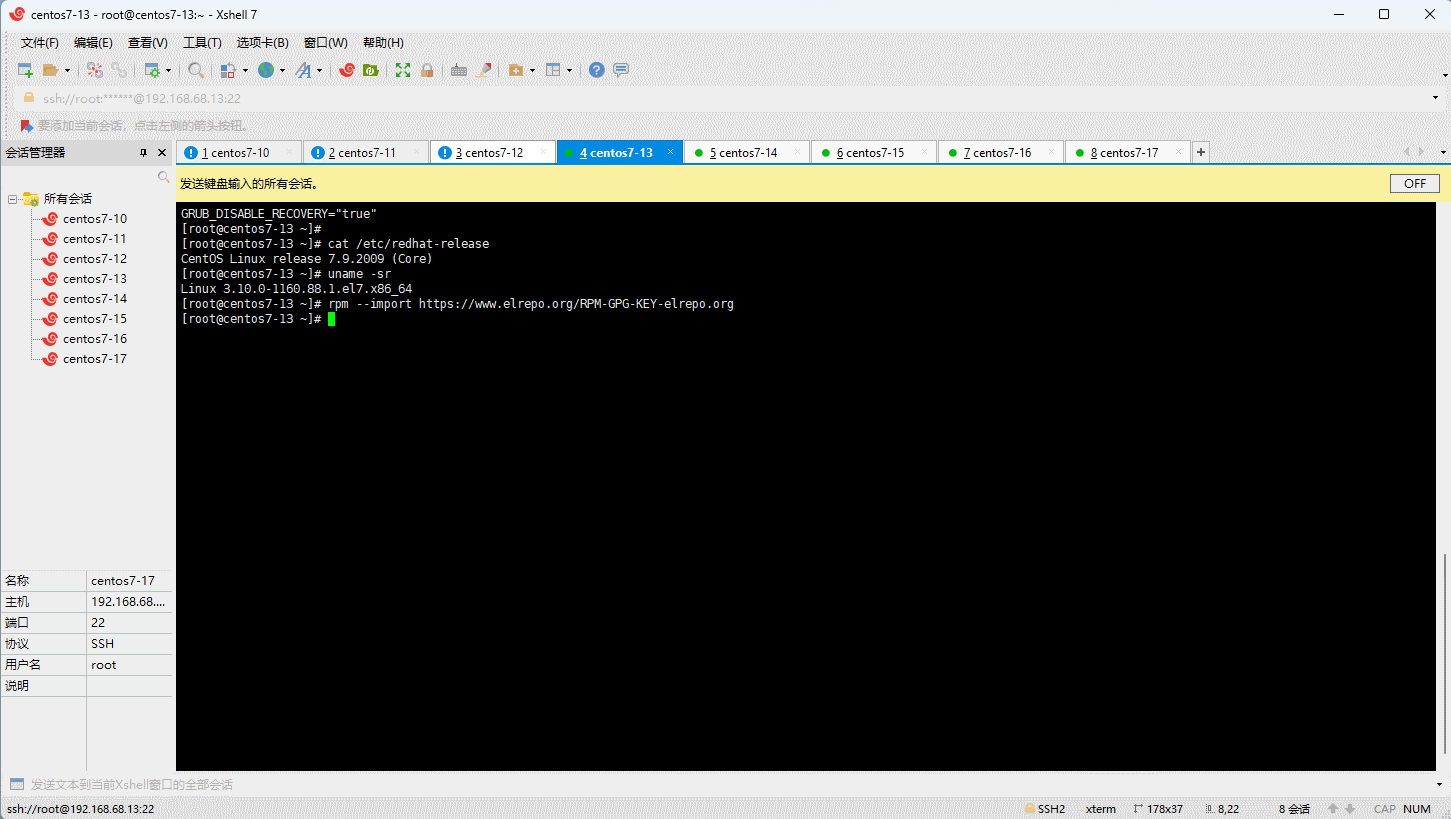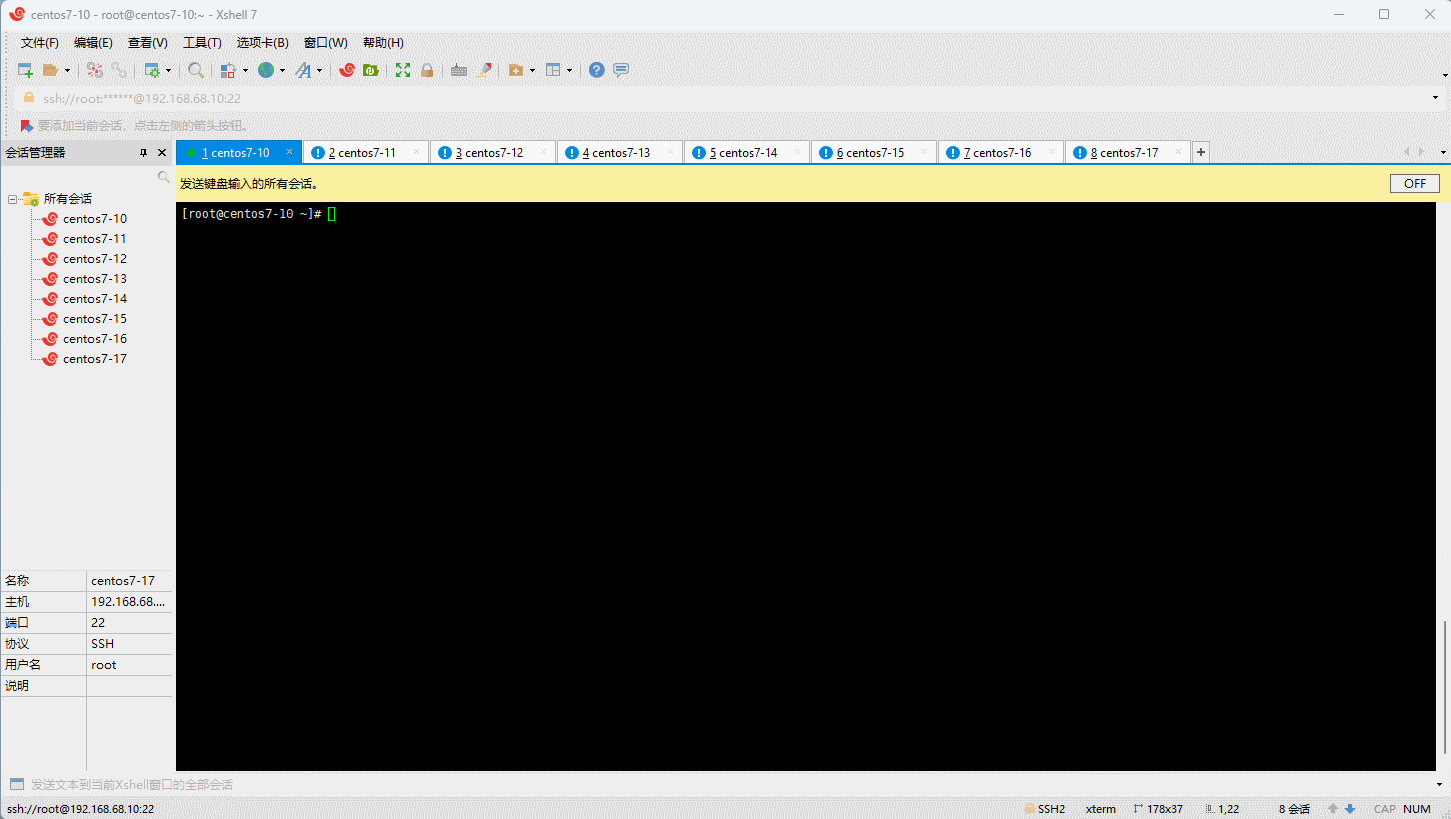
- 查看可用的系统内核相关包:

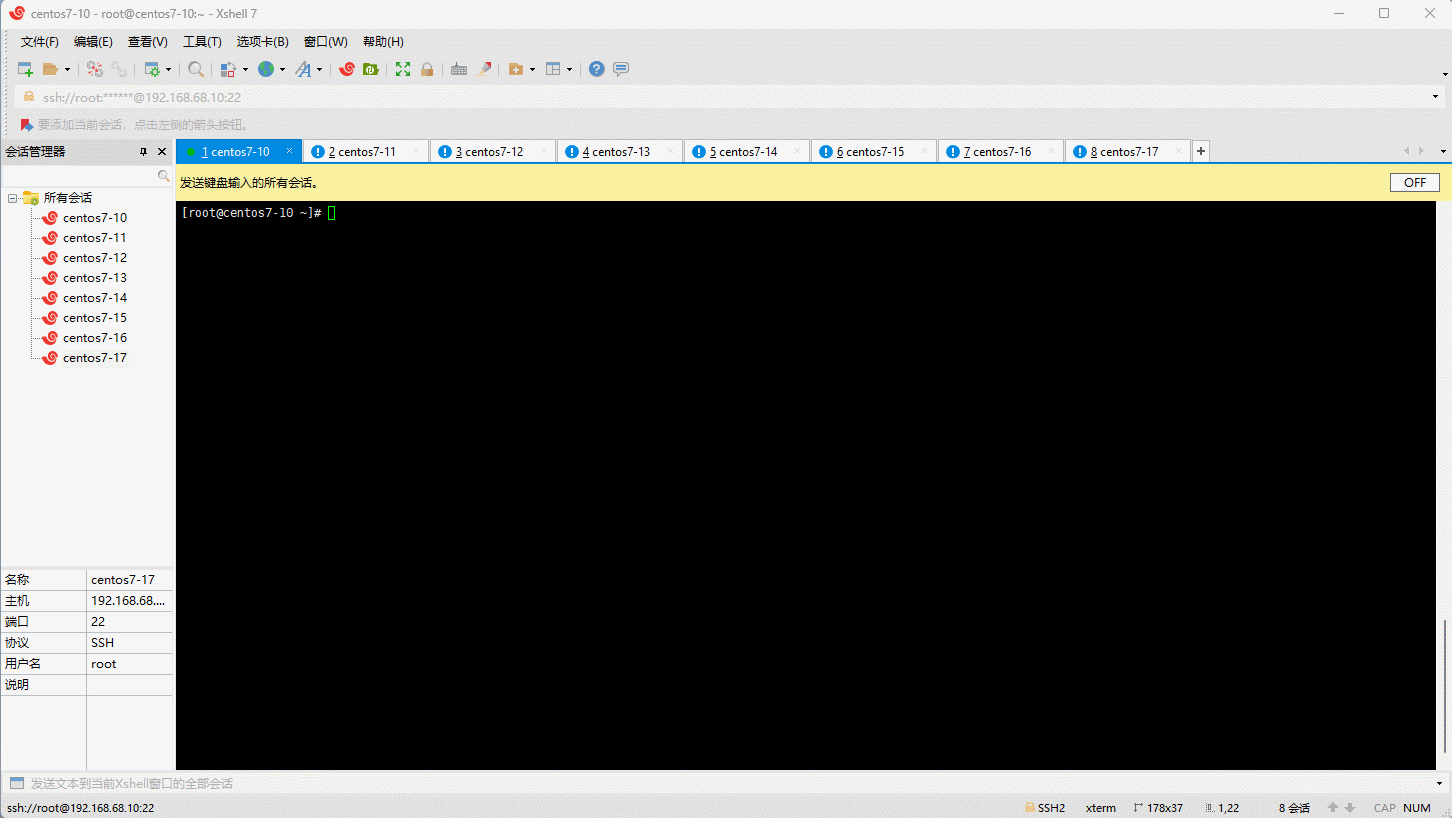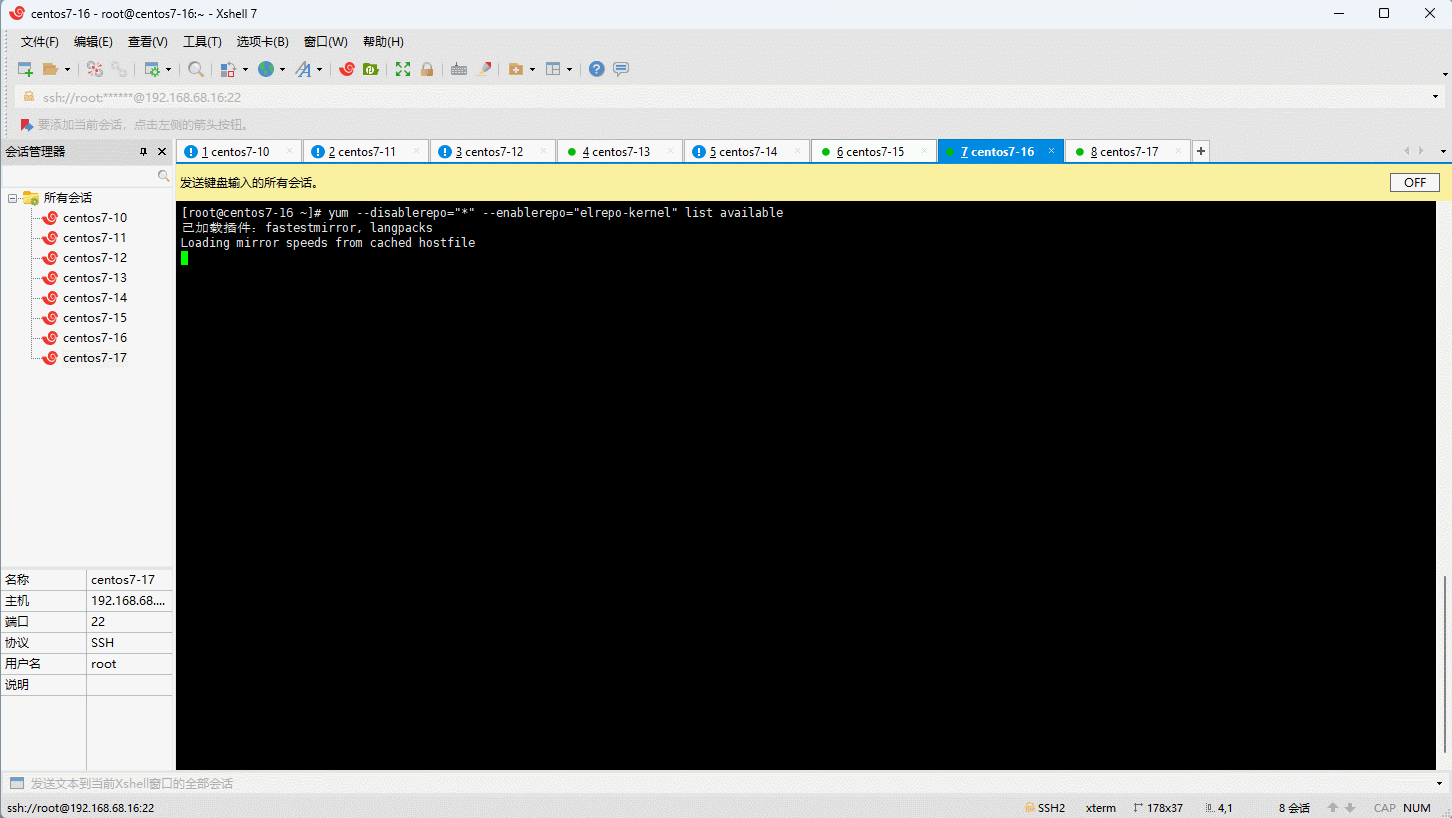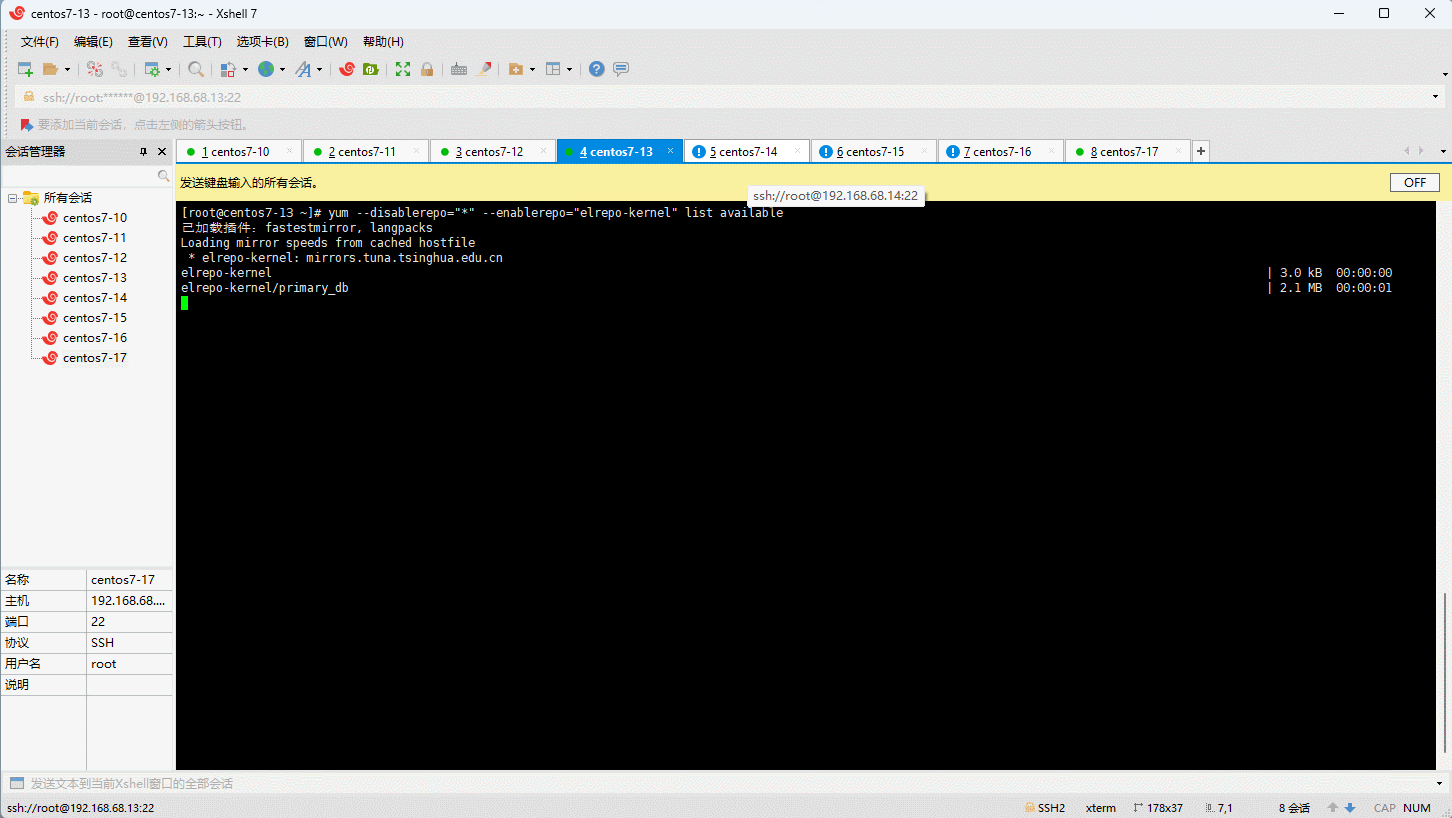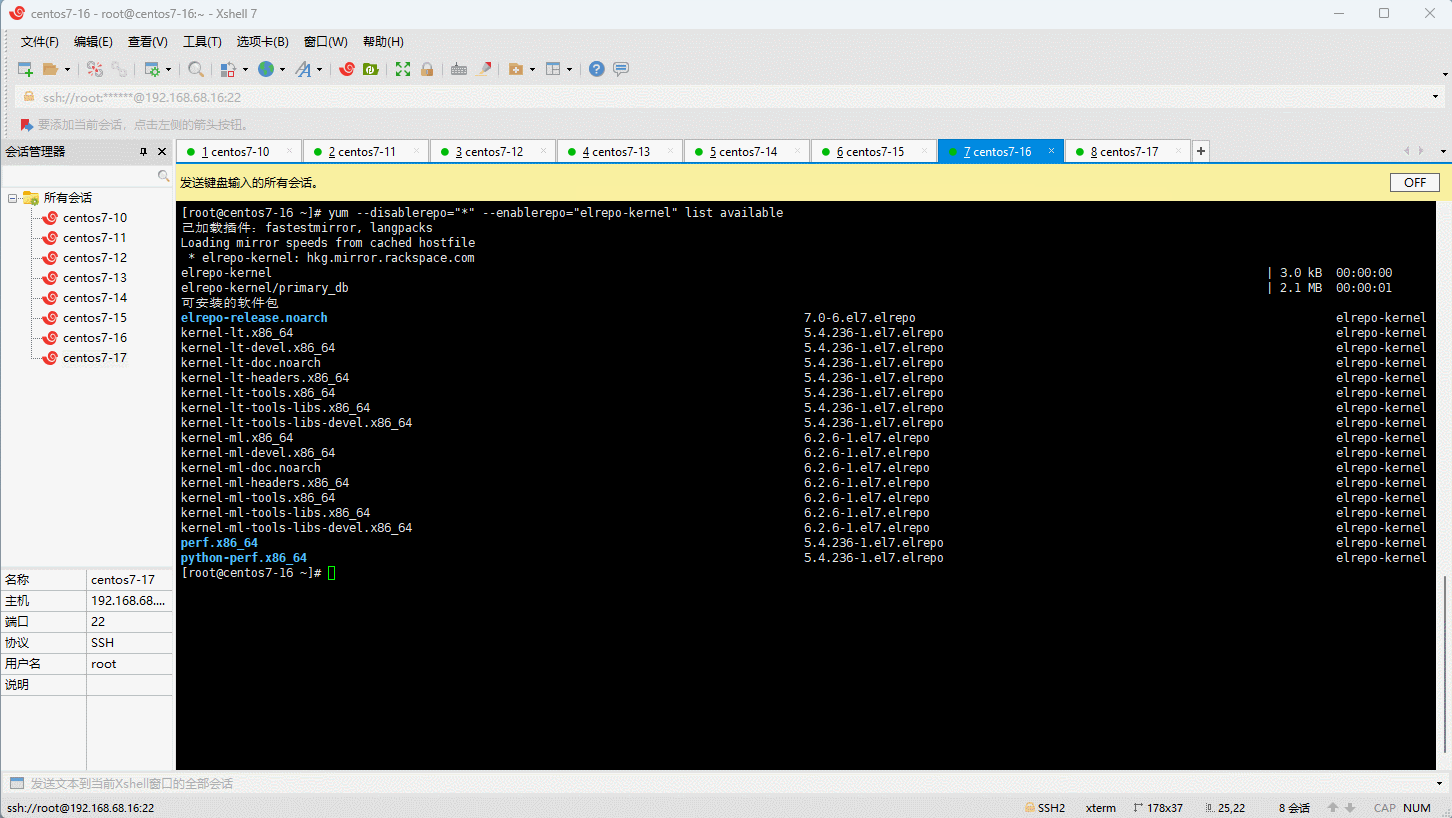
- 安装长期支持内核版本:

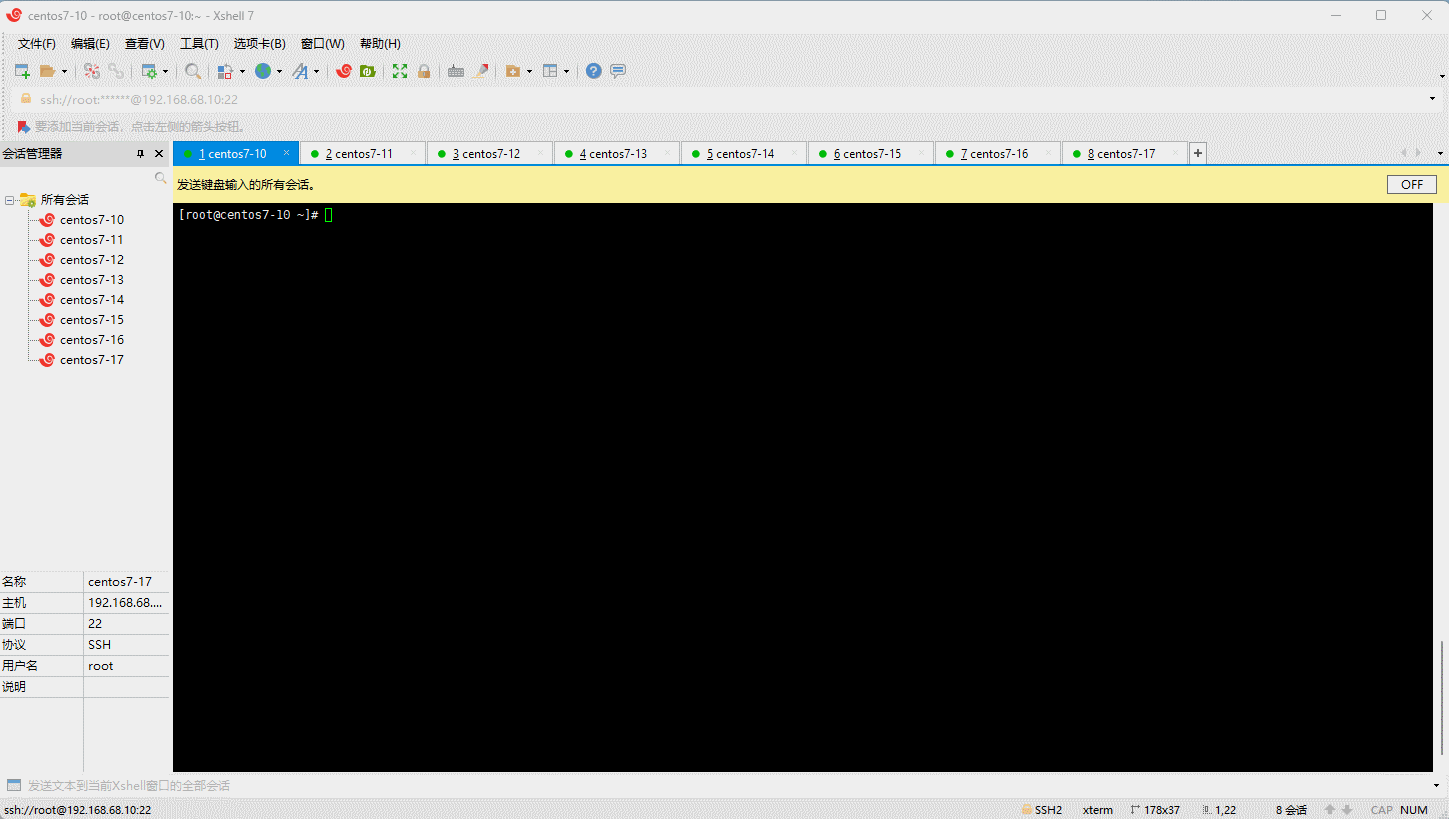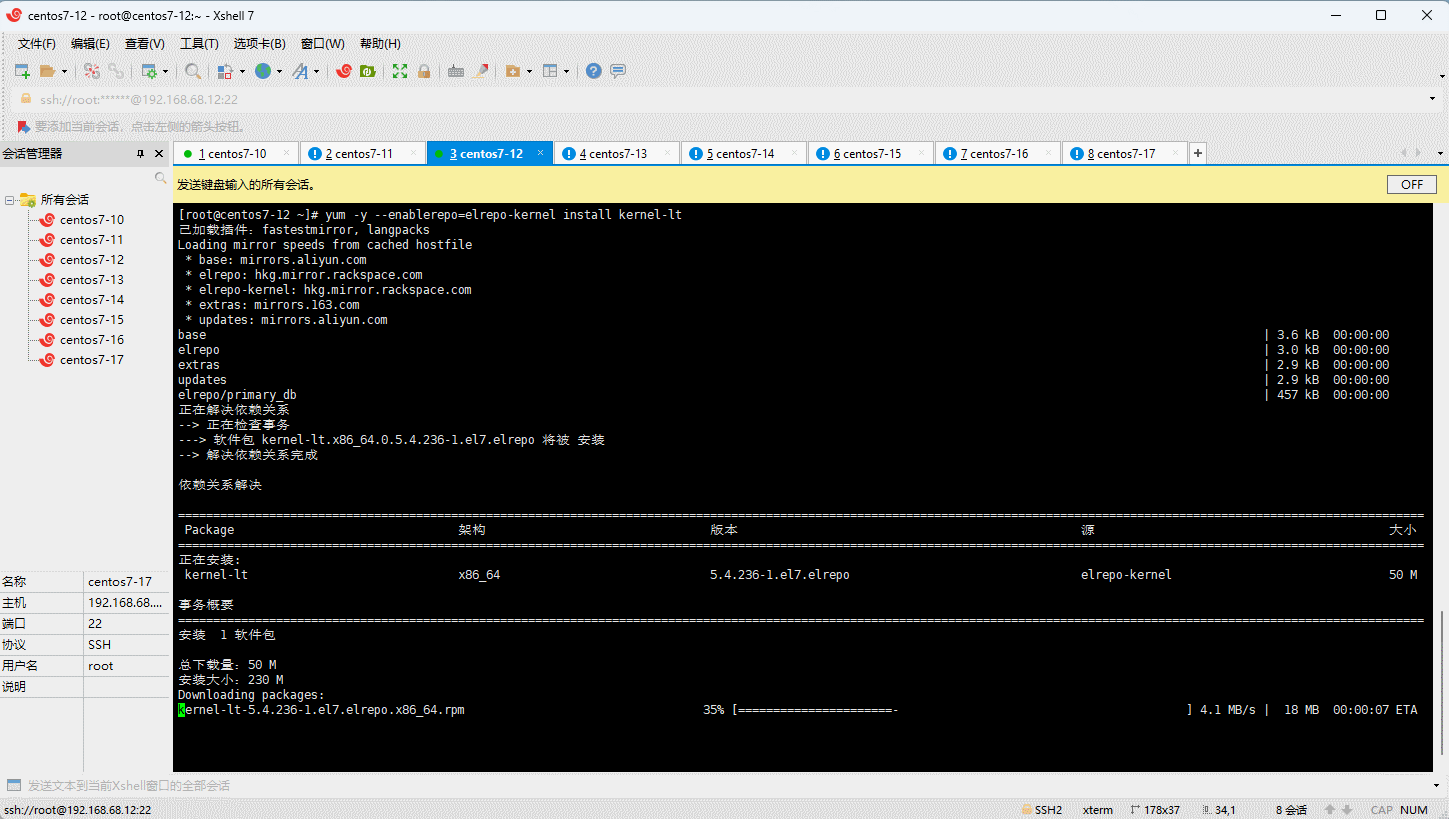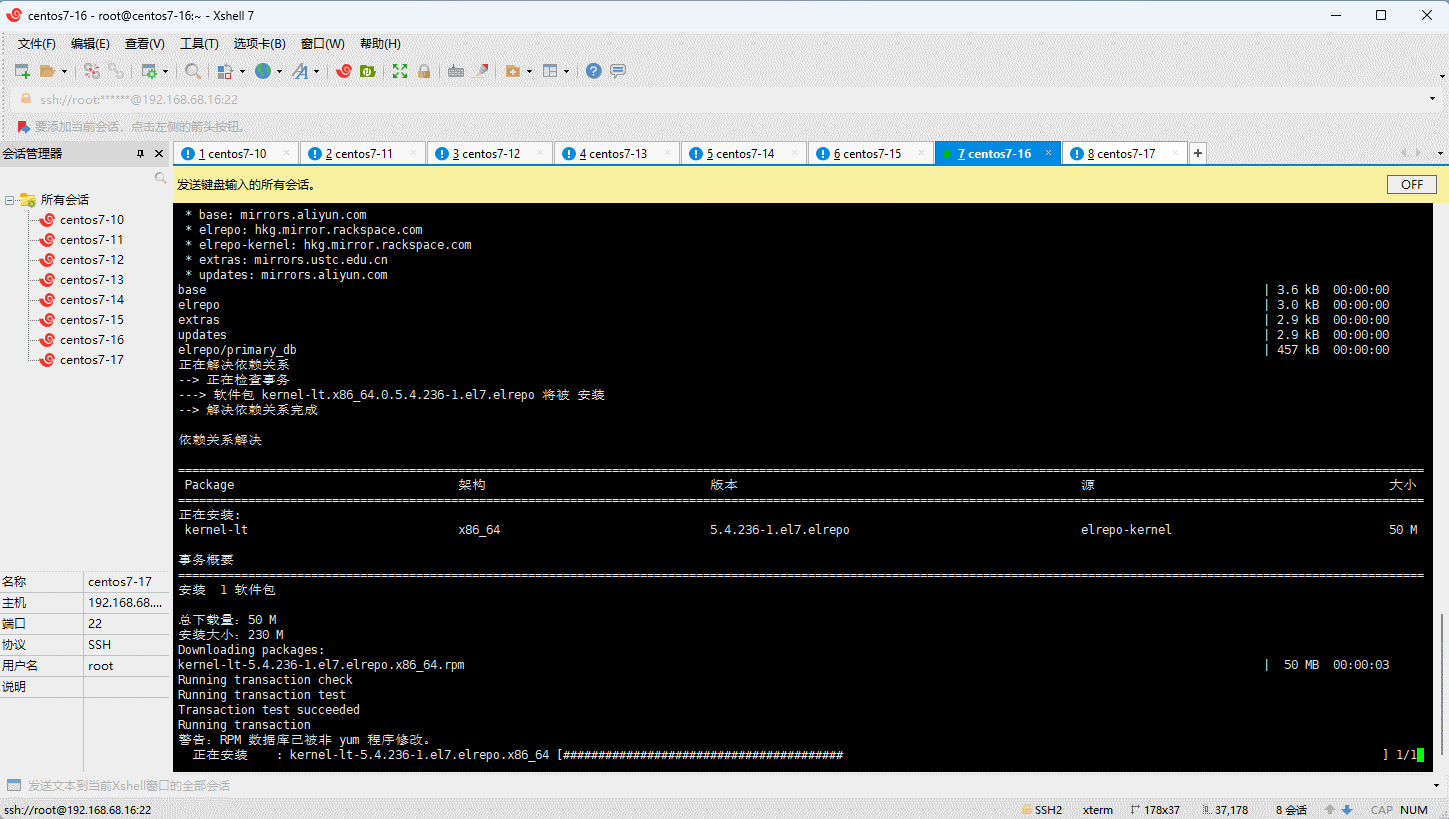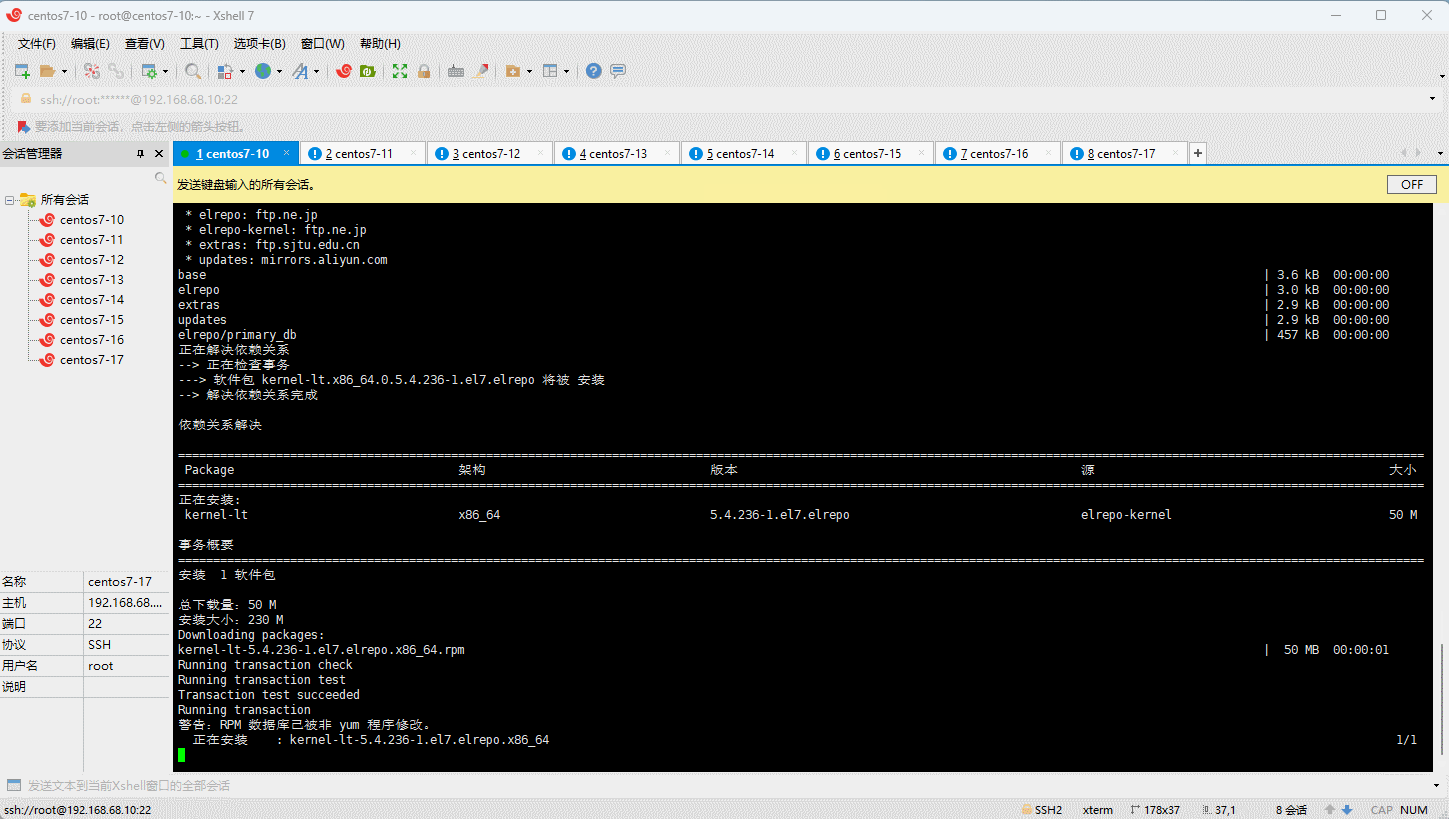
- 设置默认的内核版本:

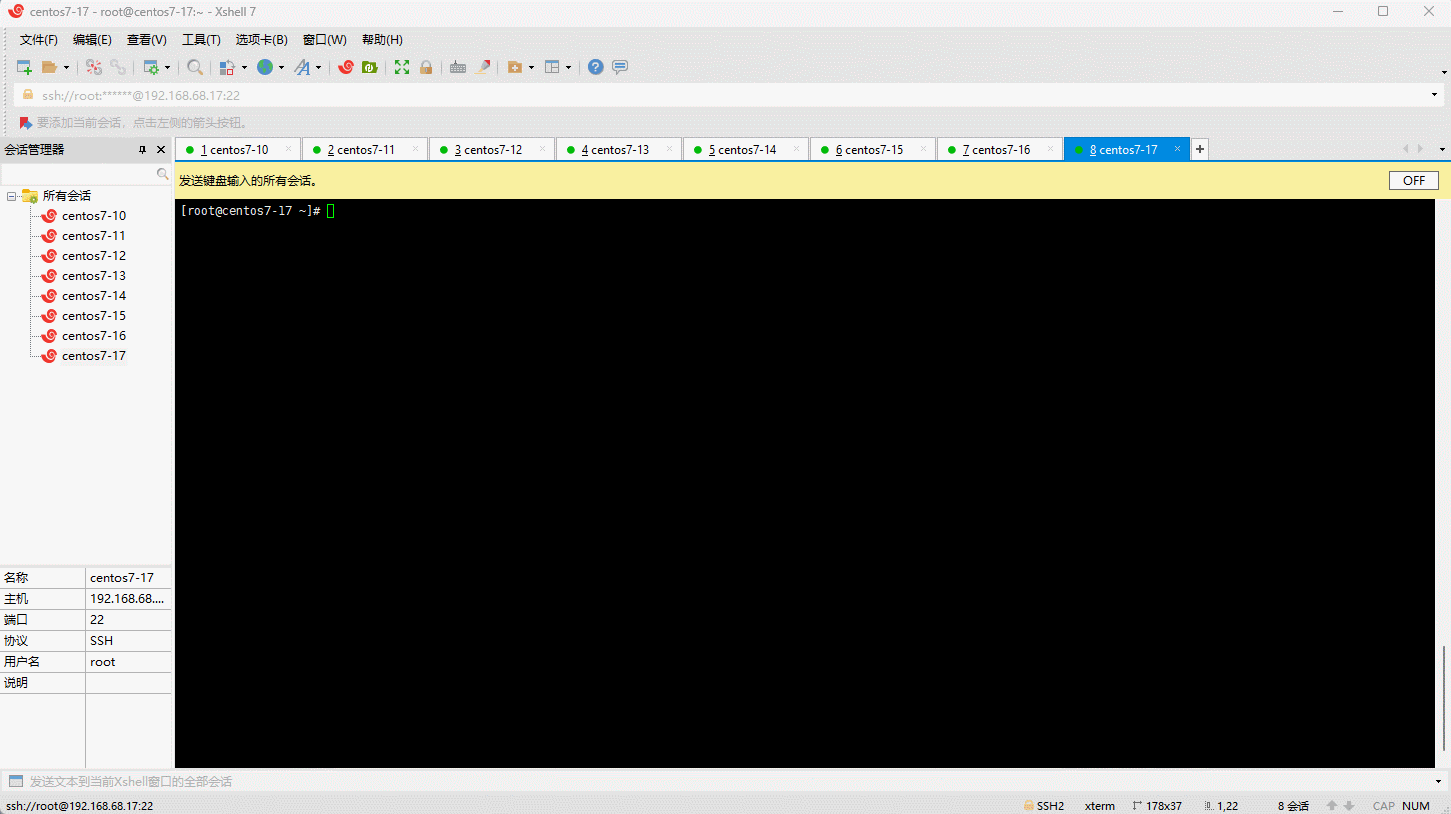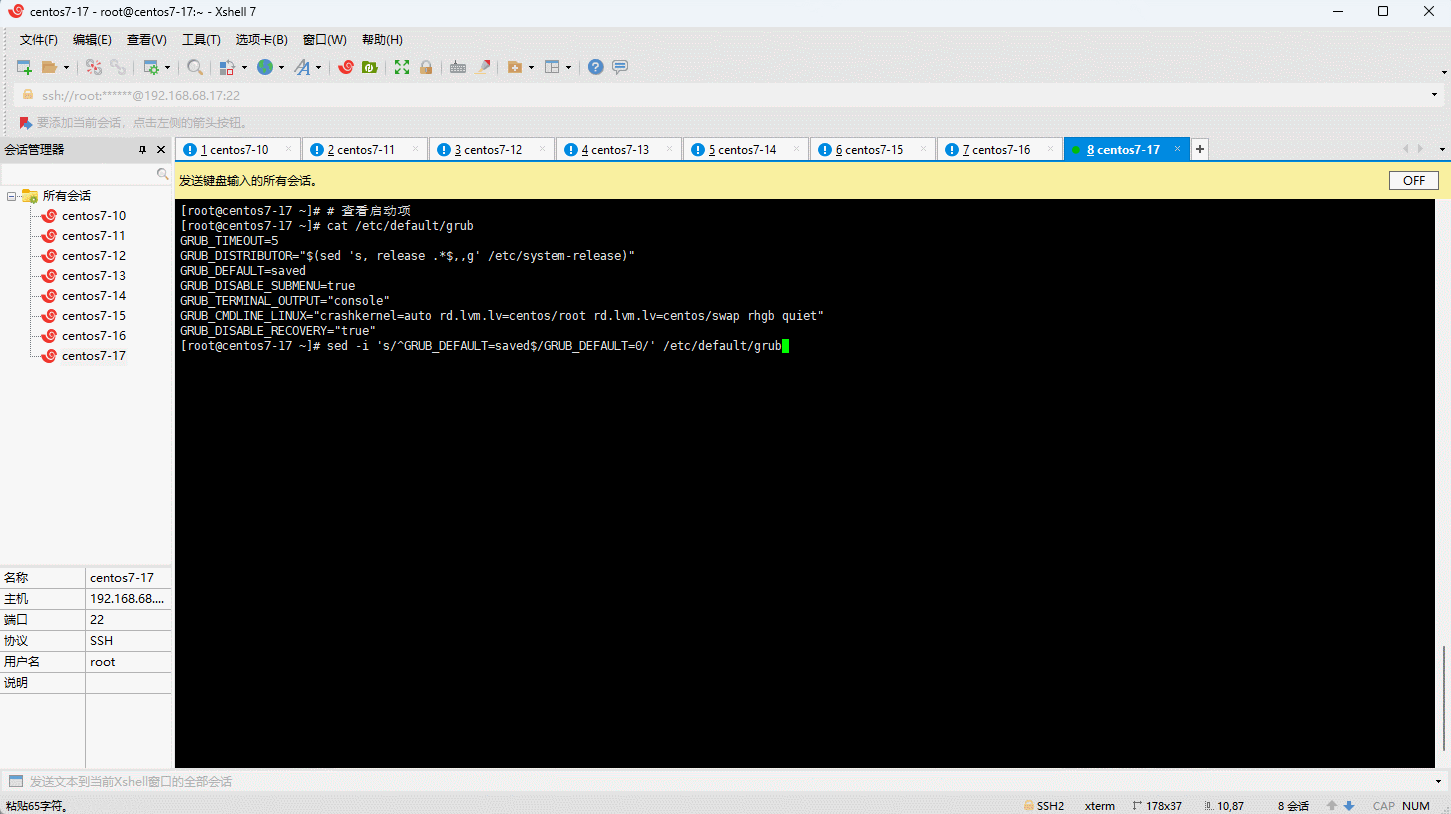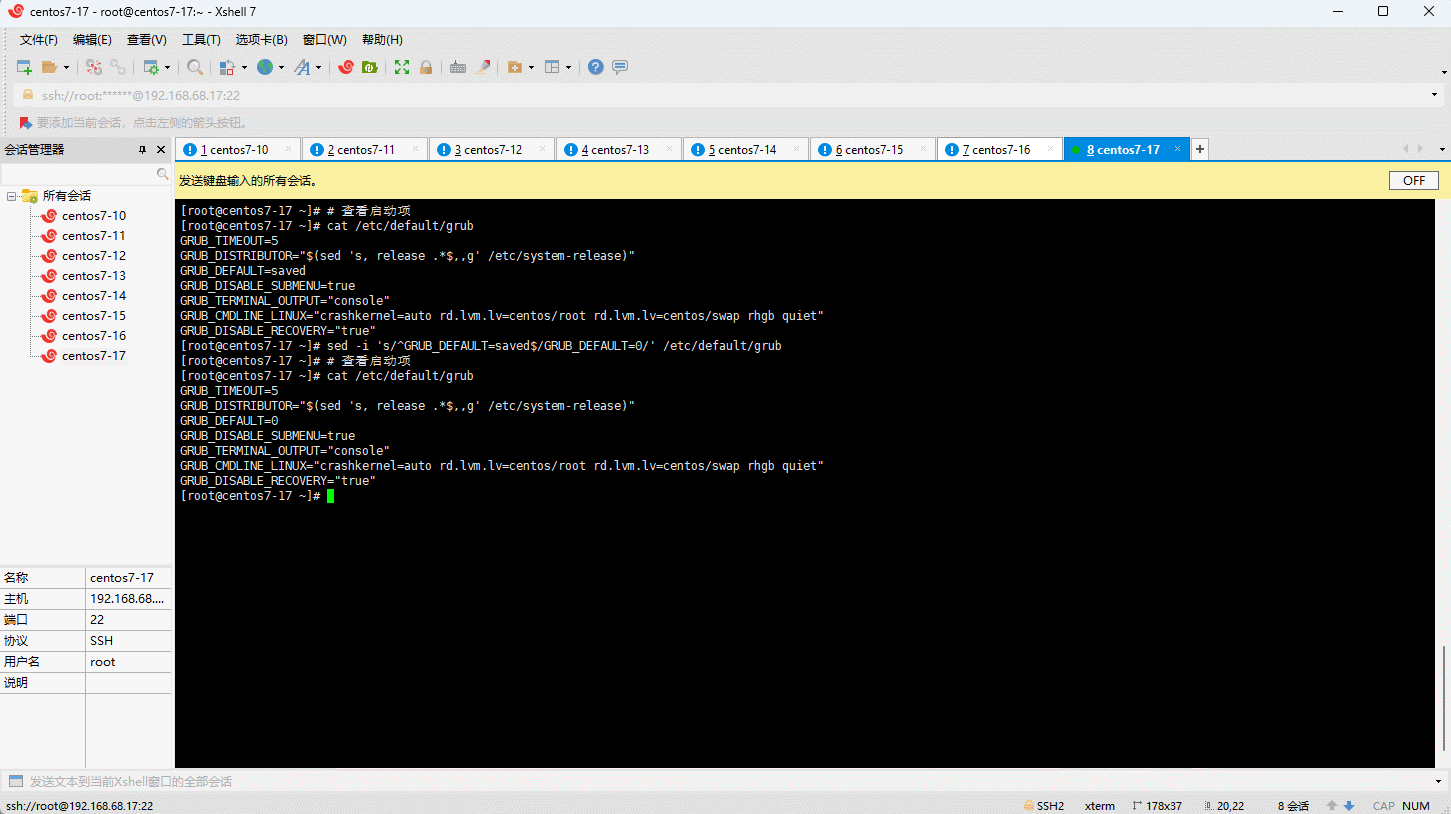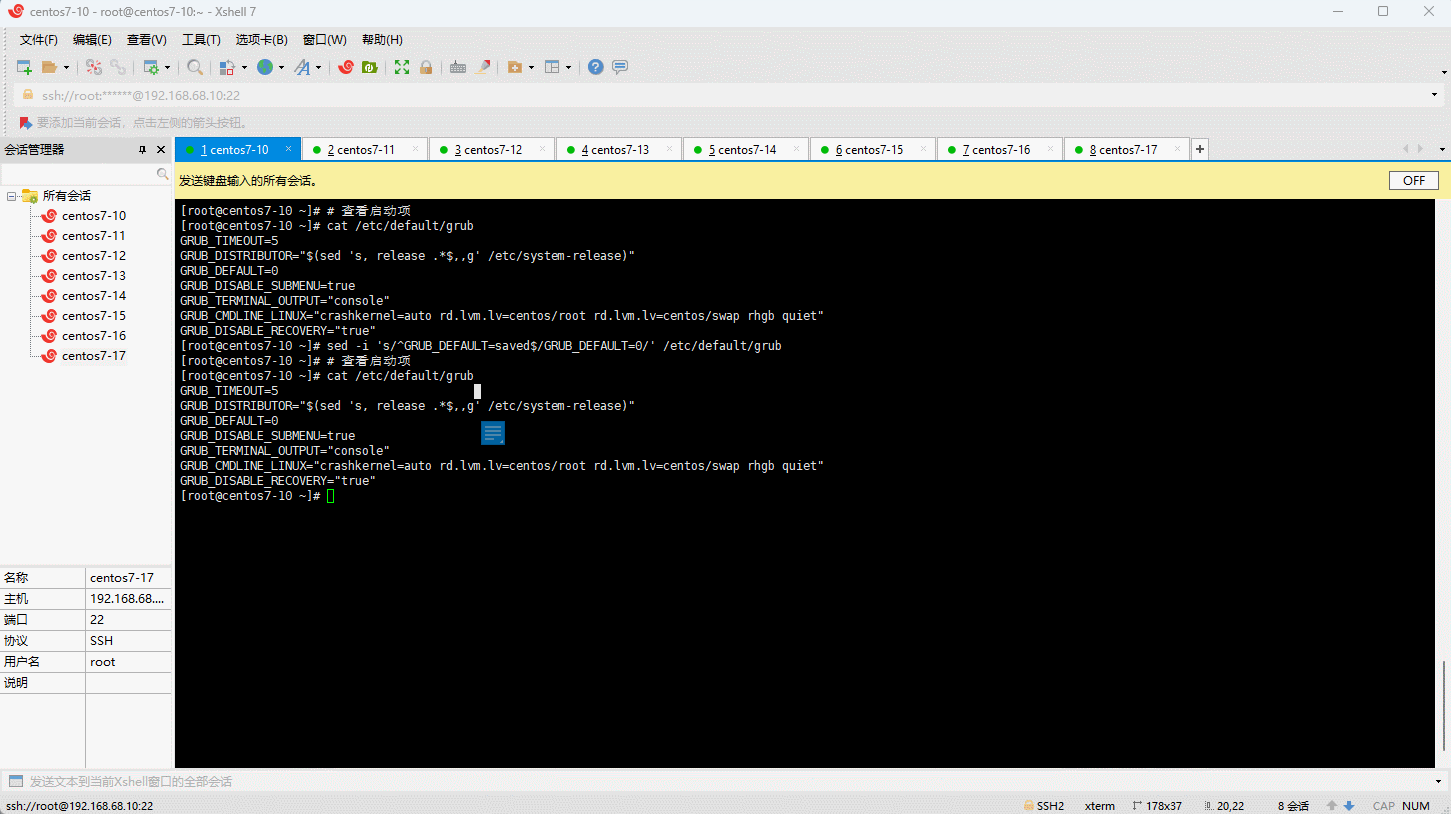
- 重新创建内核配置:

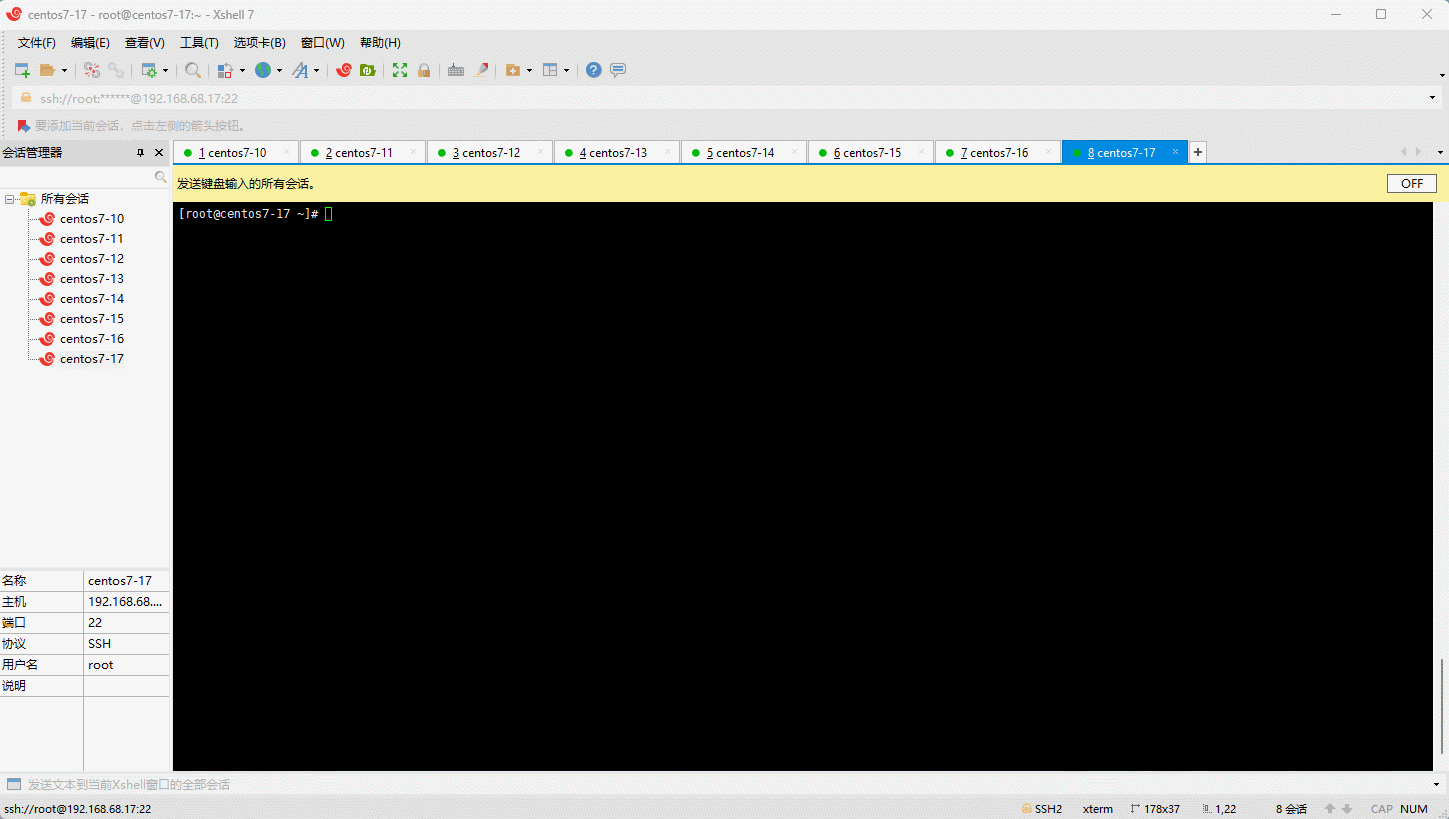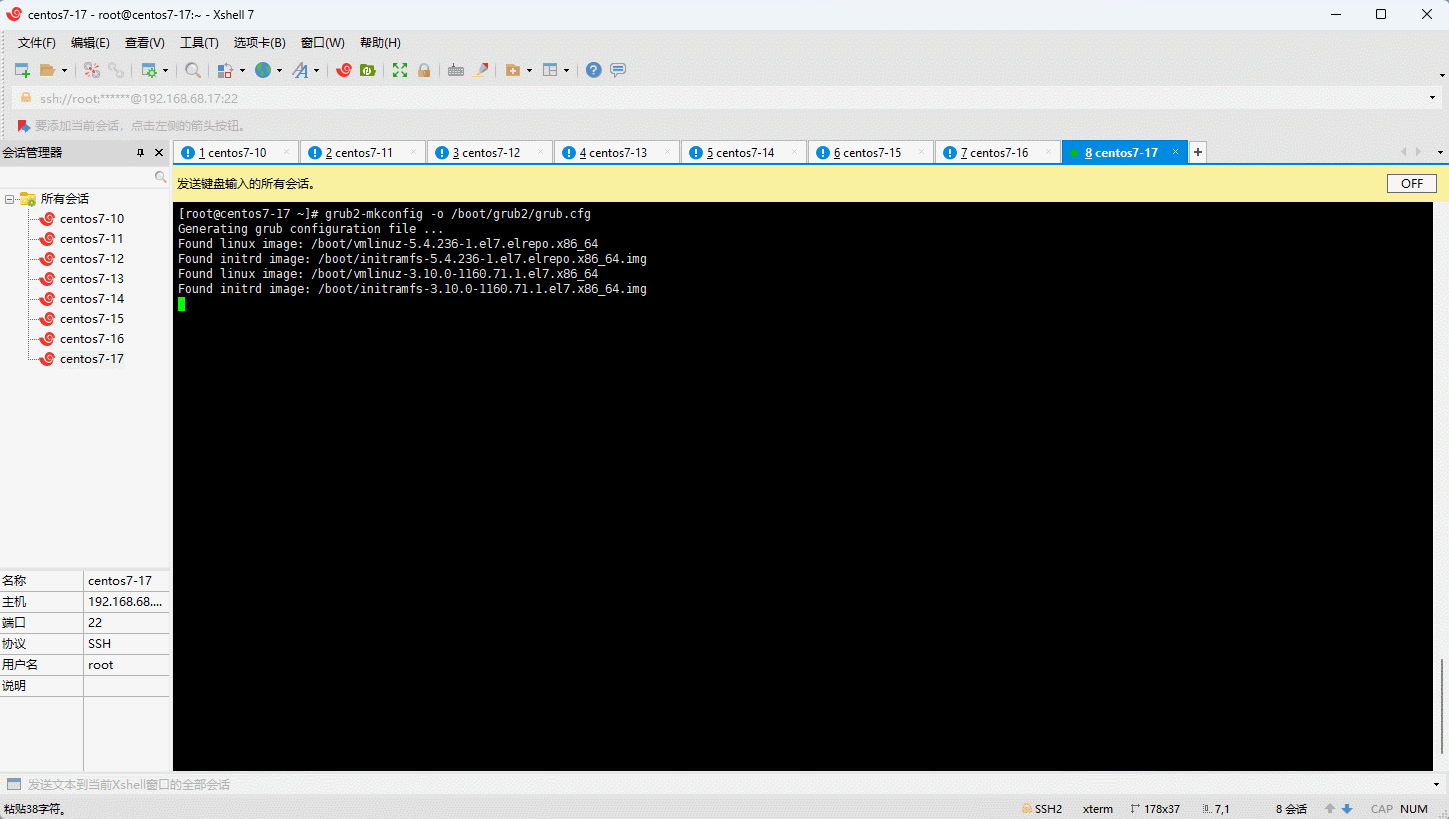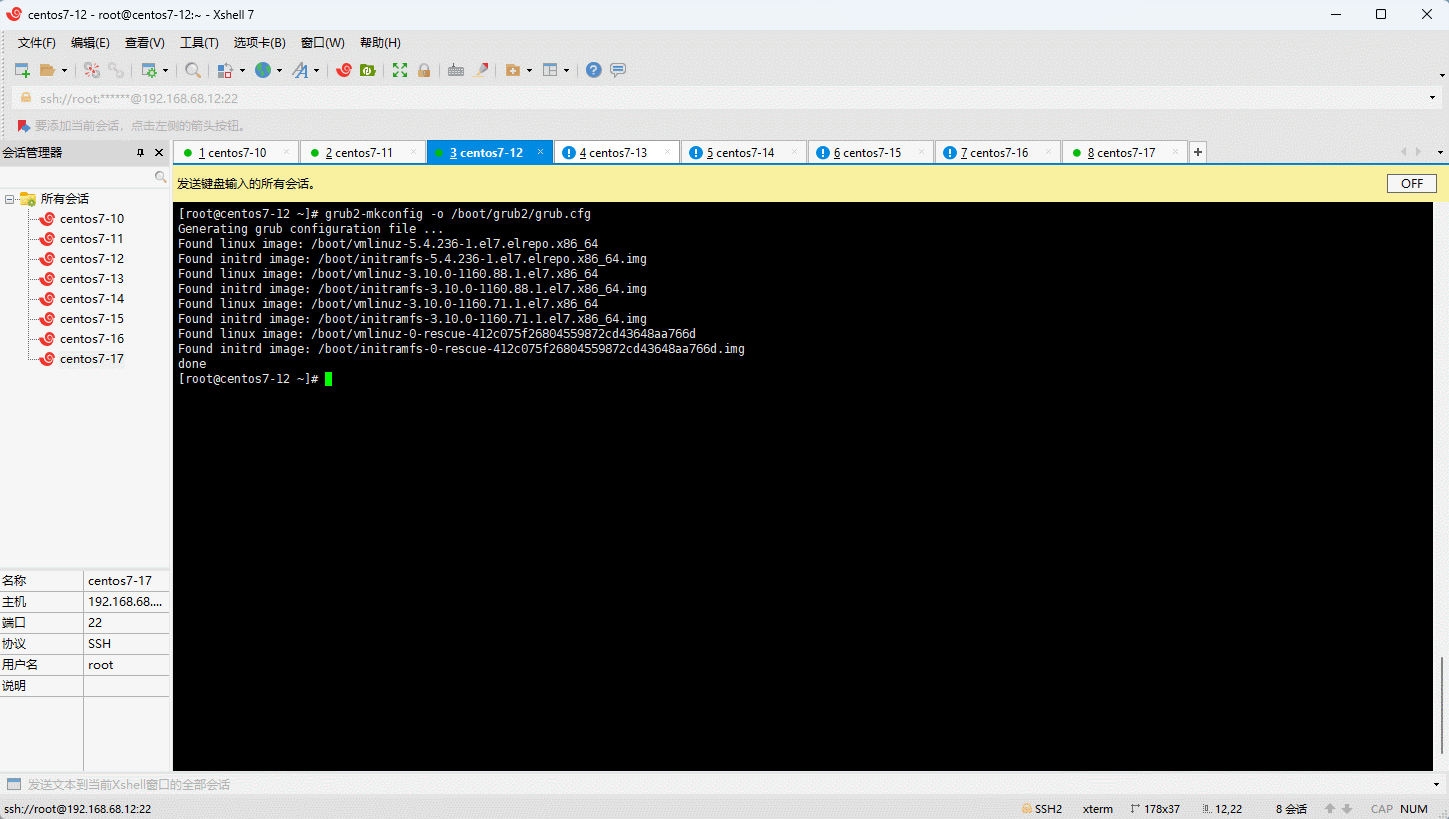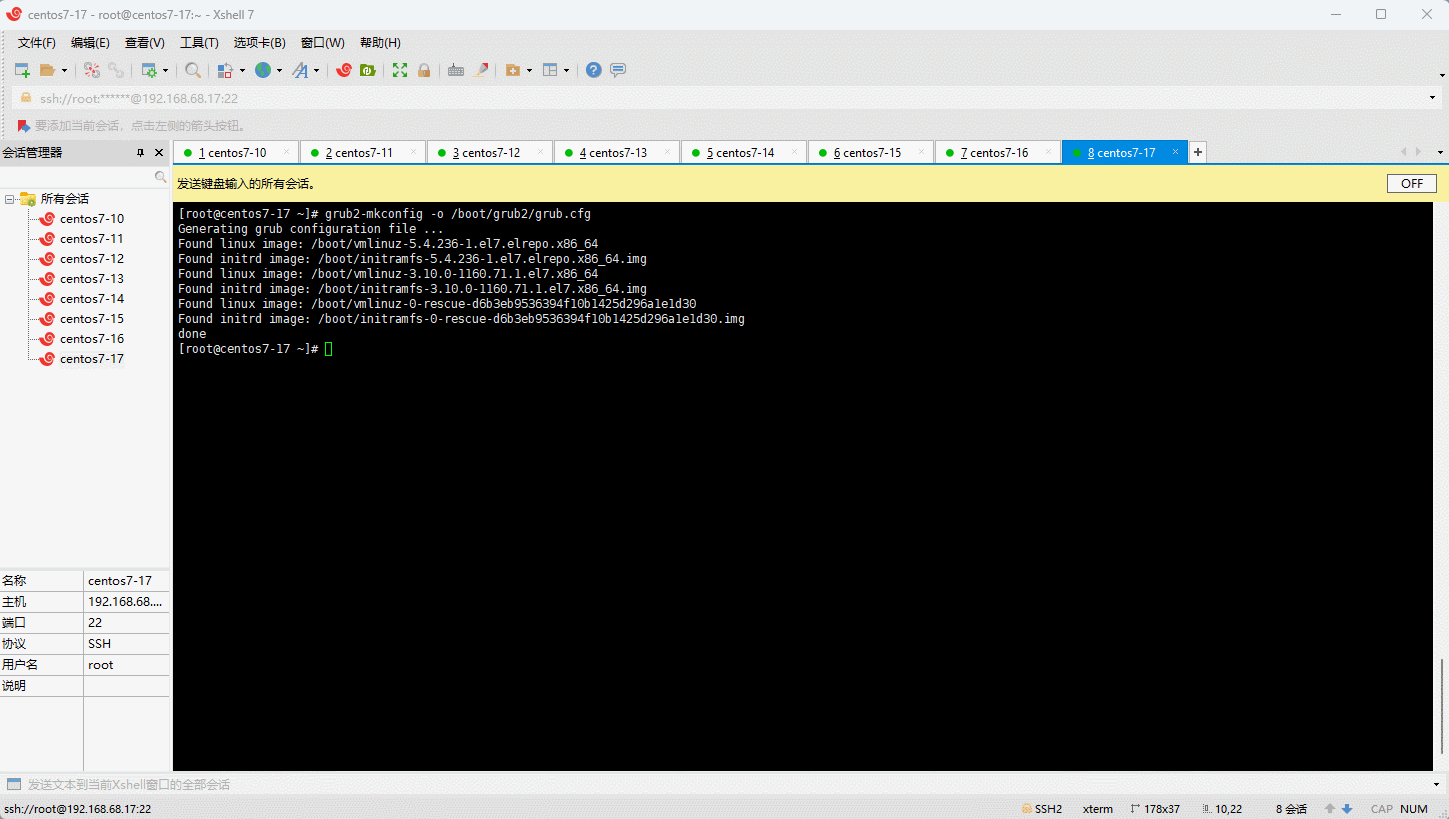
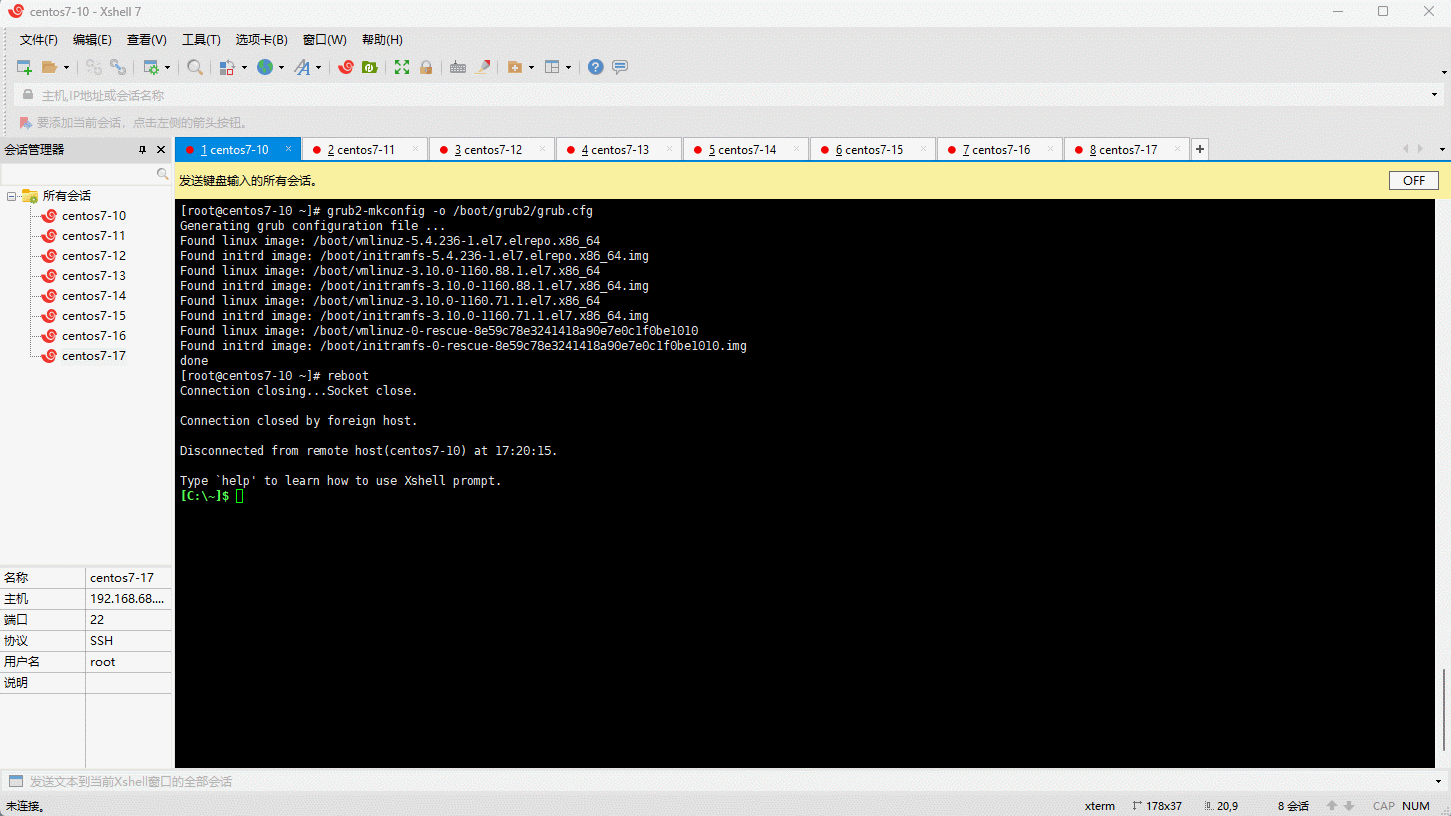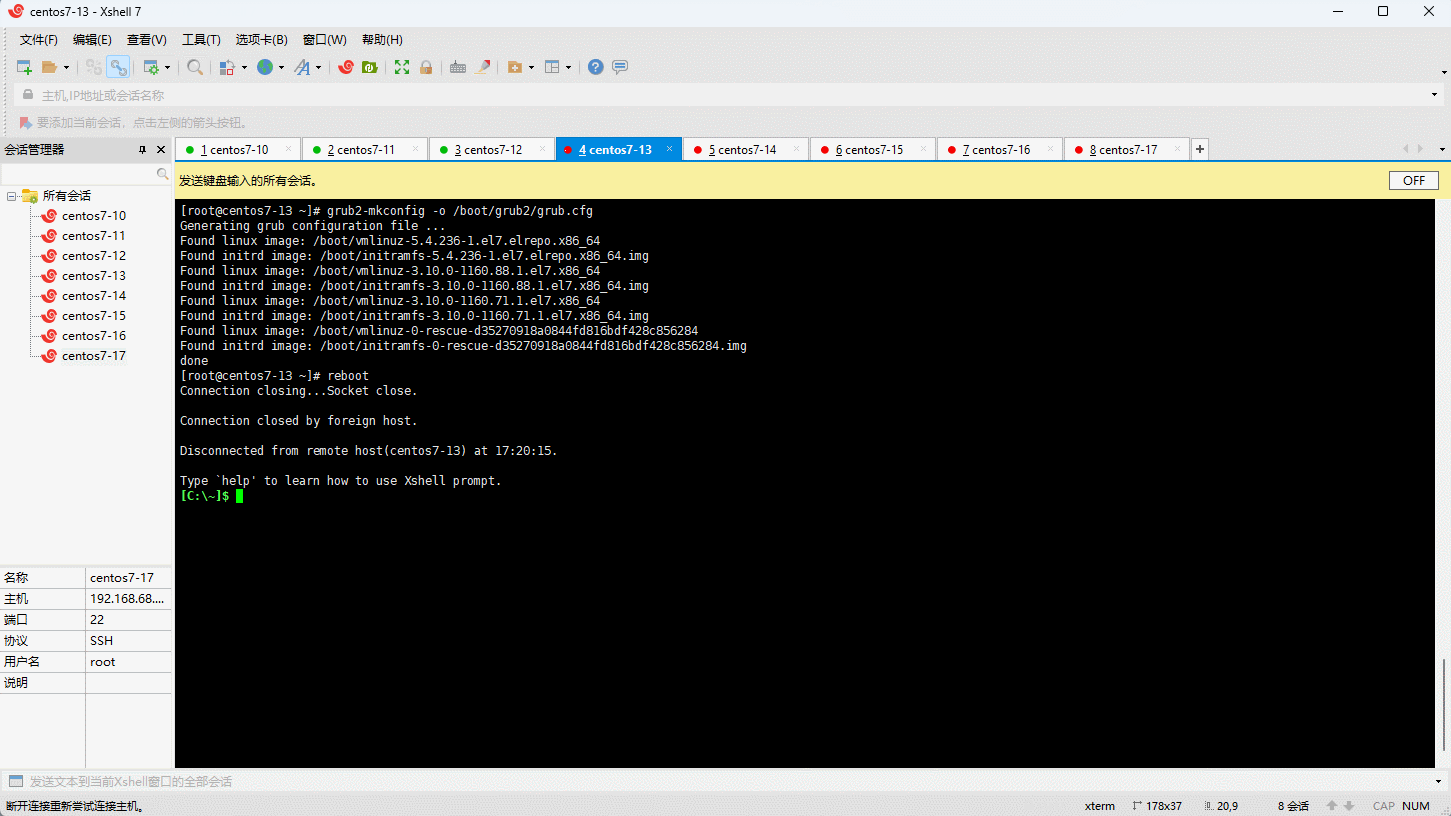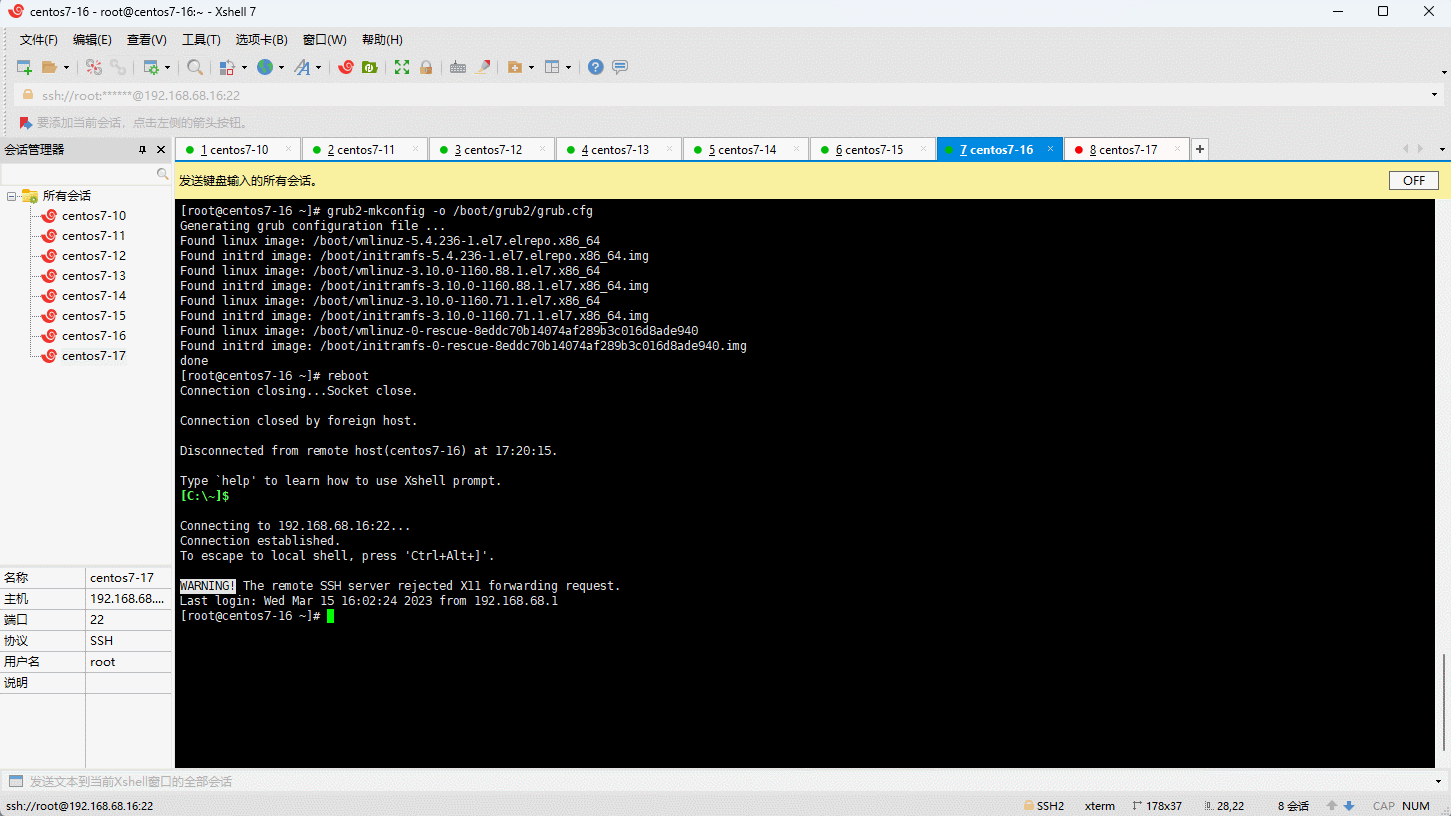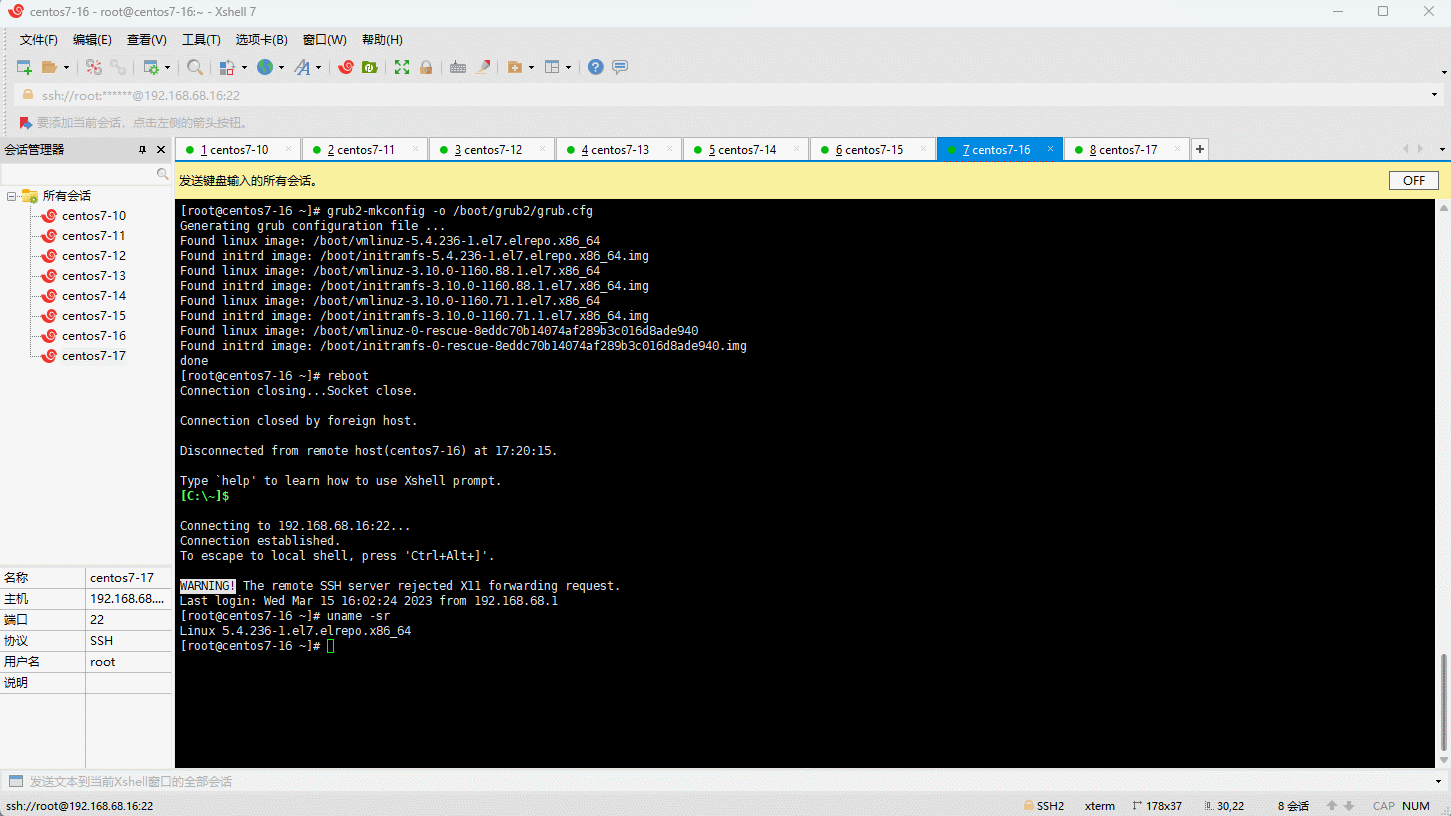
- 重启系统:

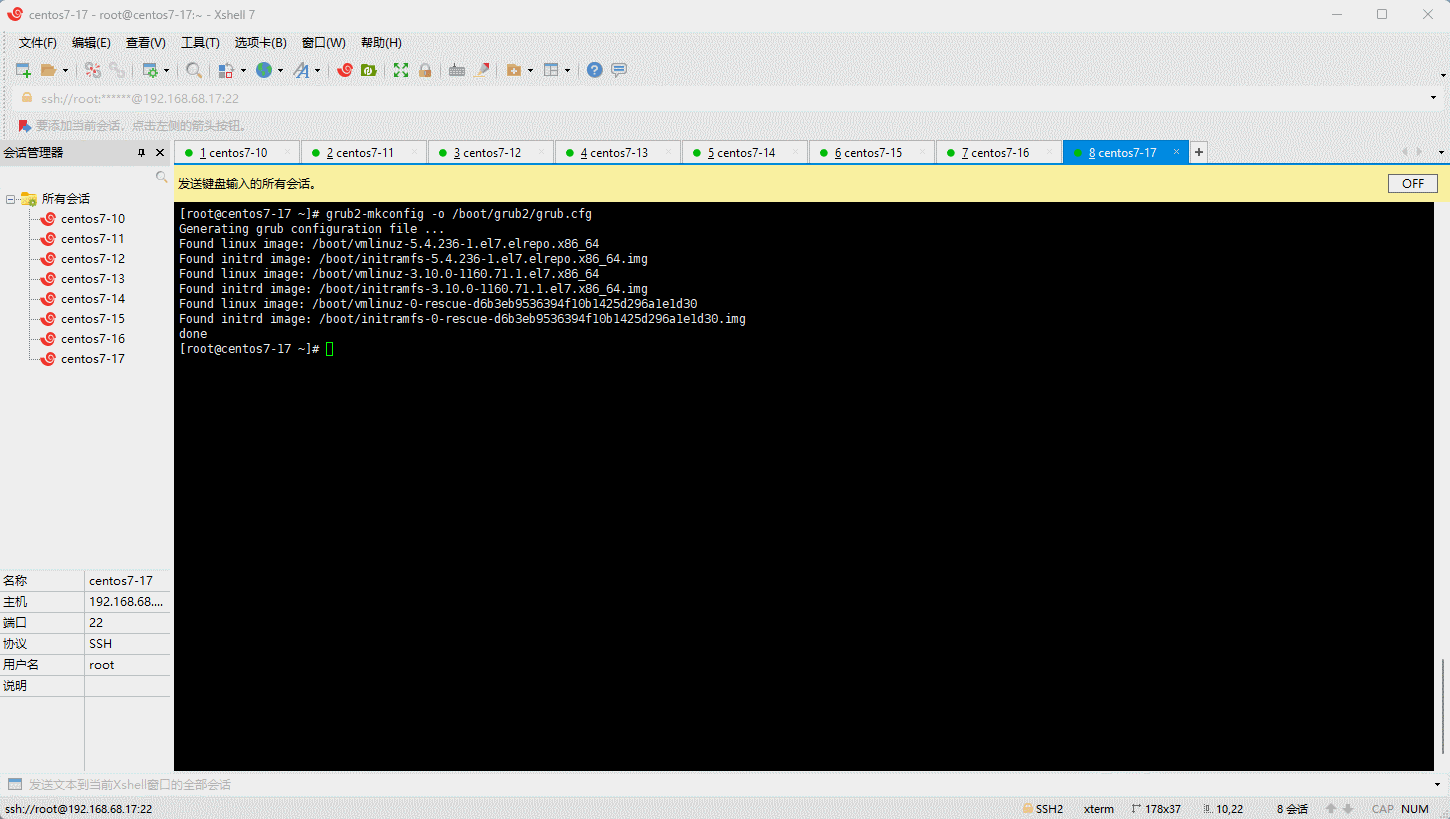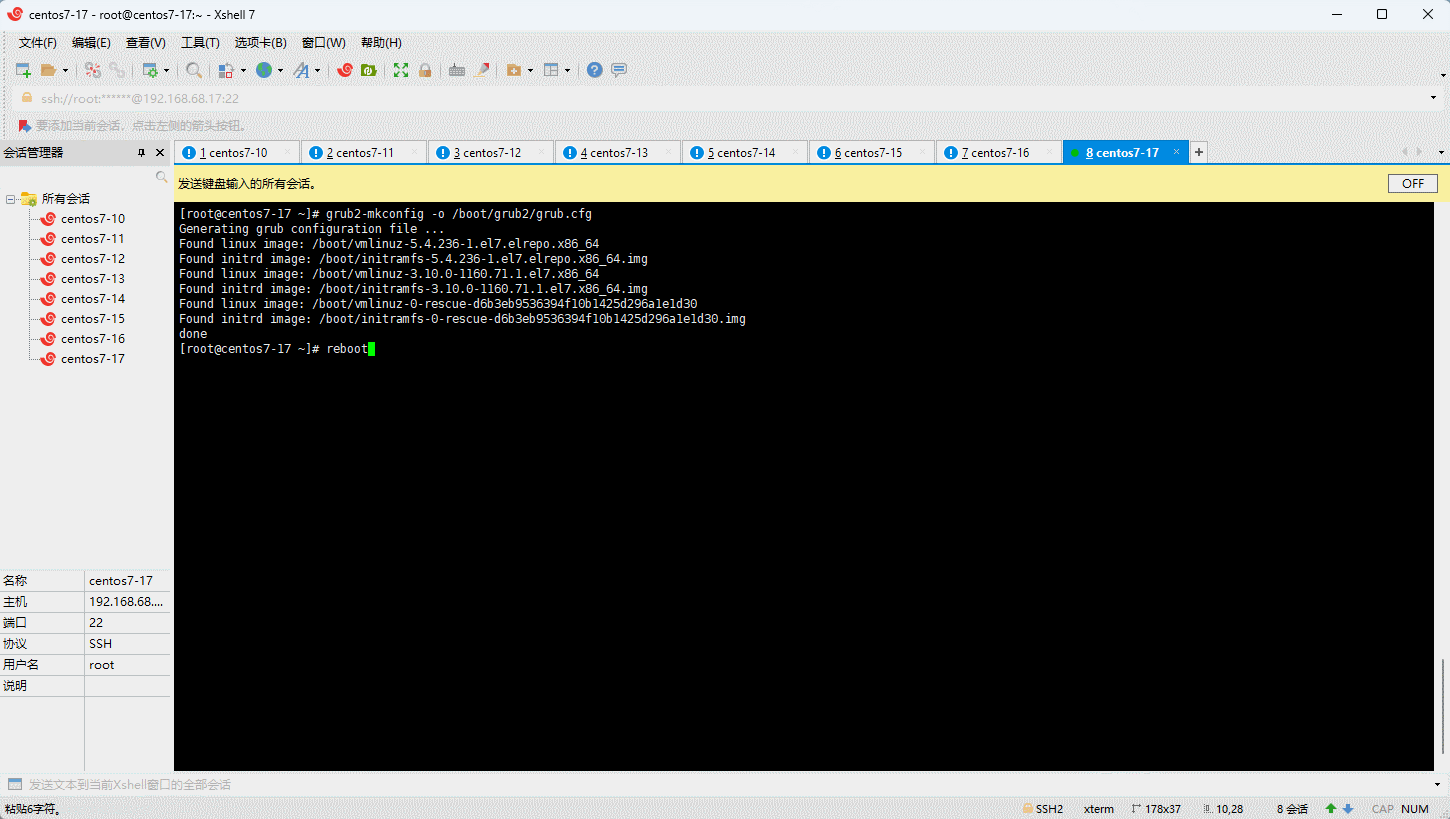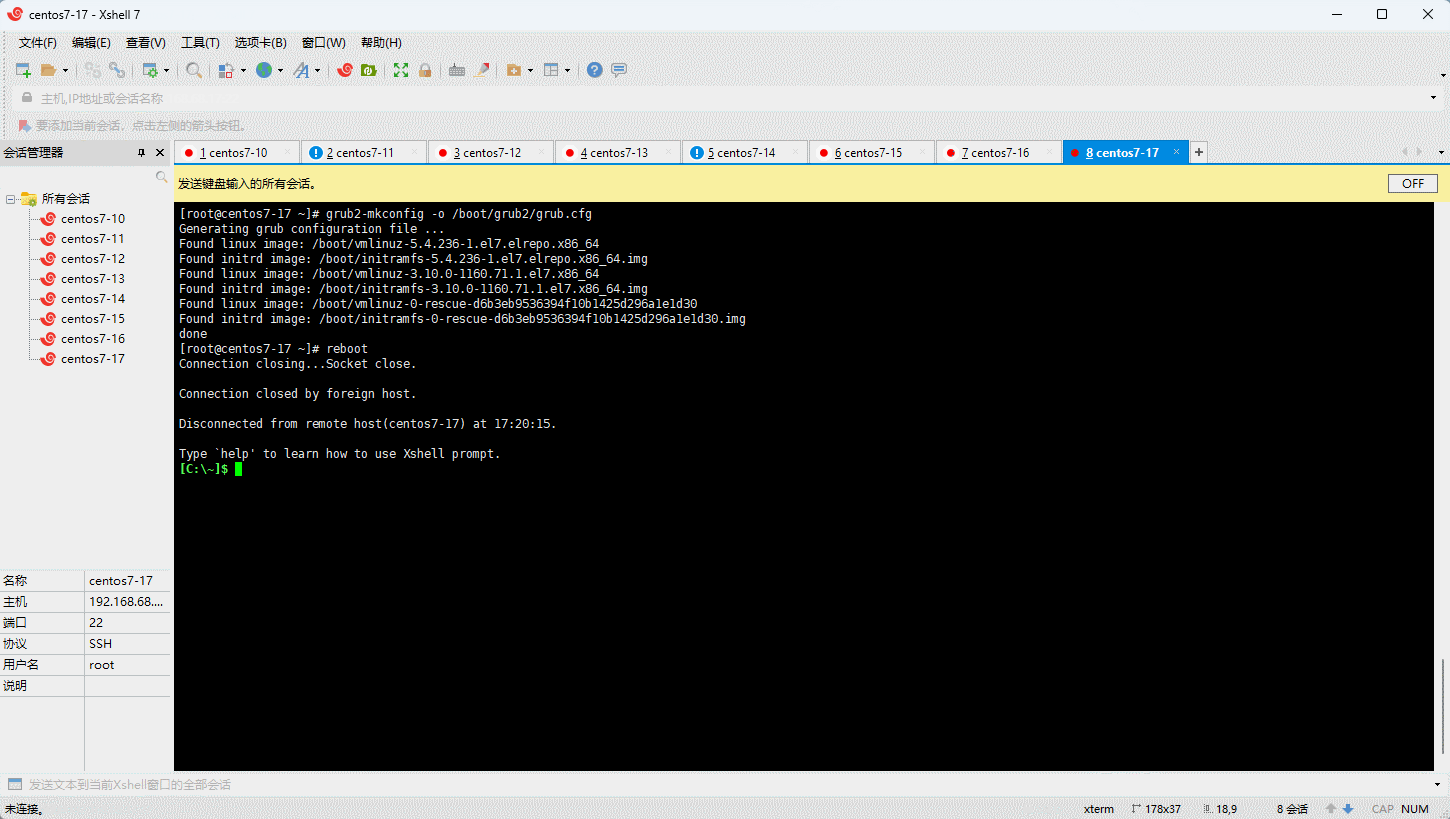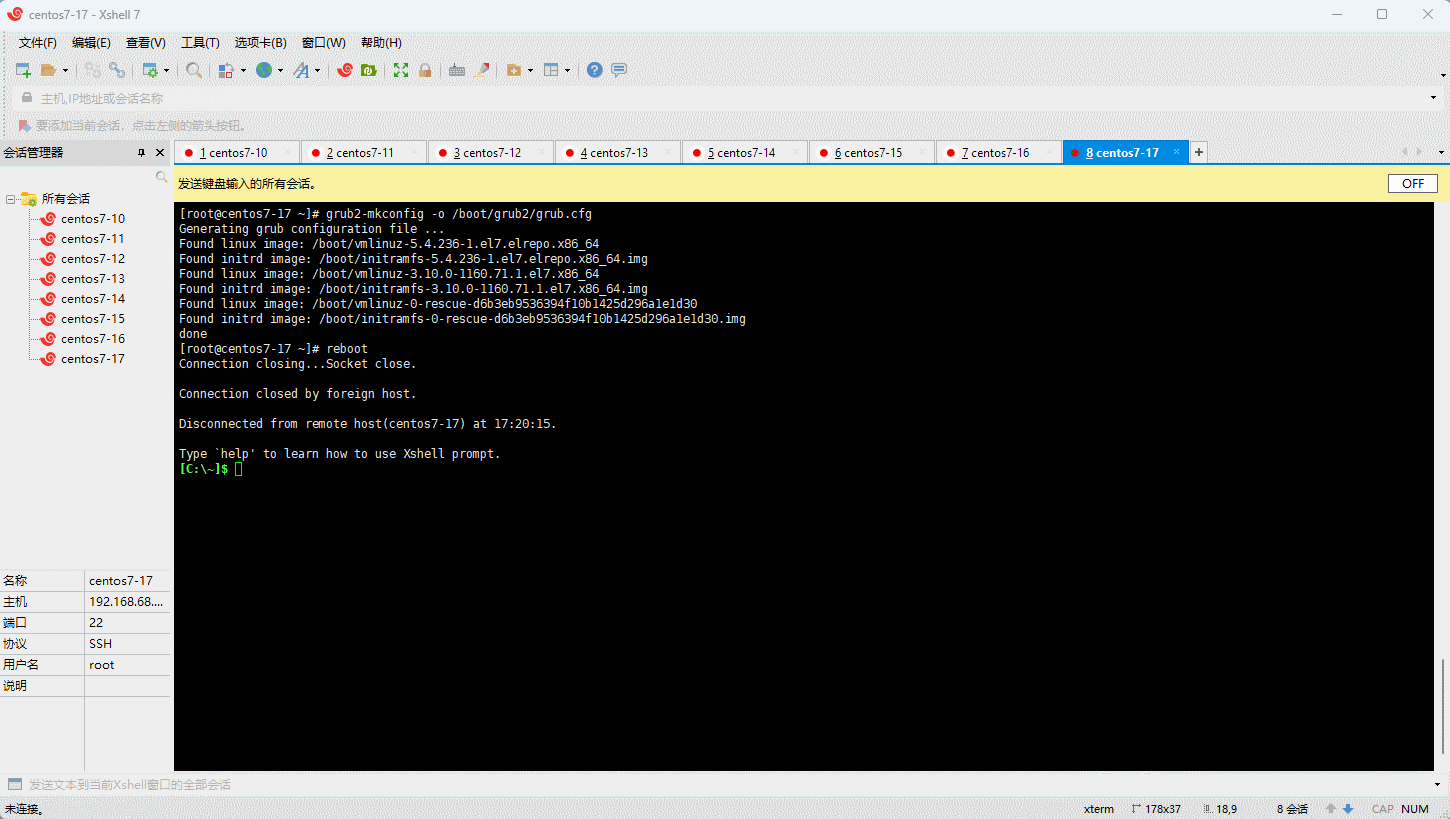
- 查看当前系统的内核:

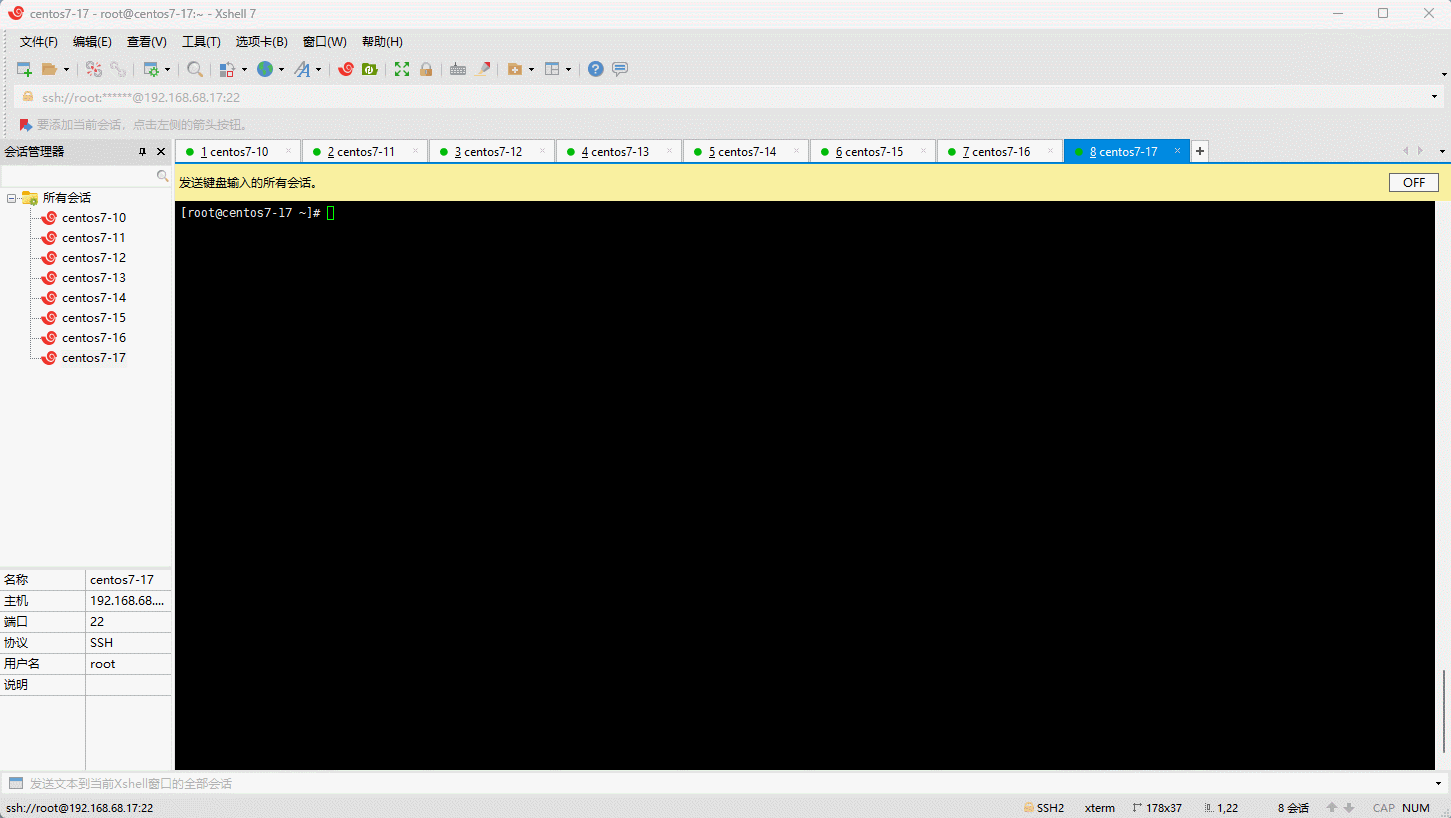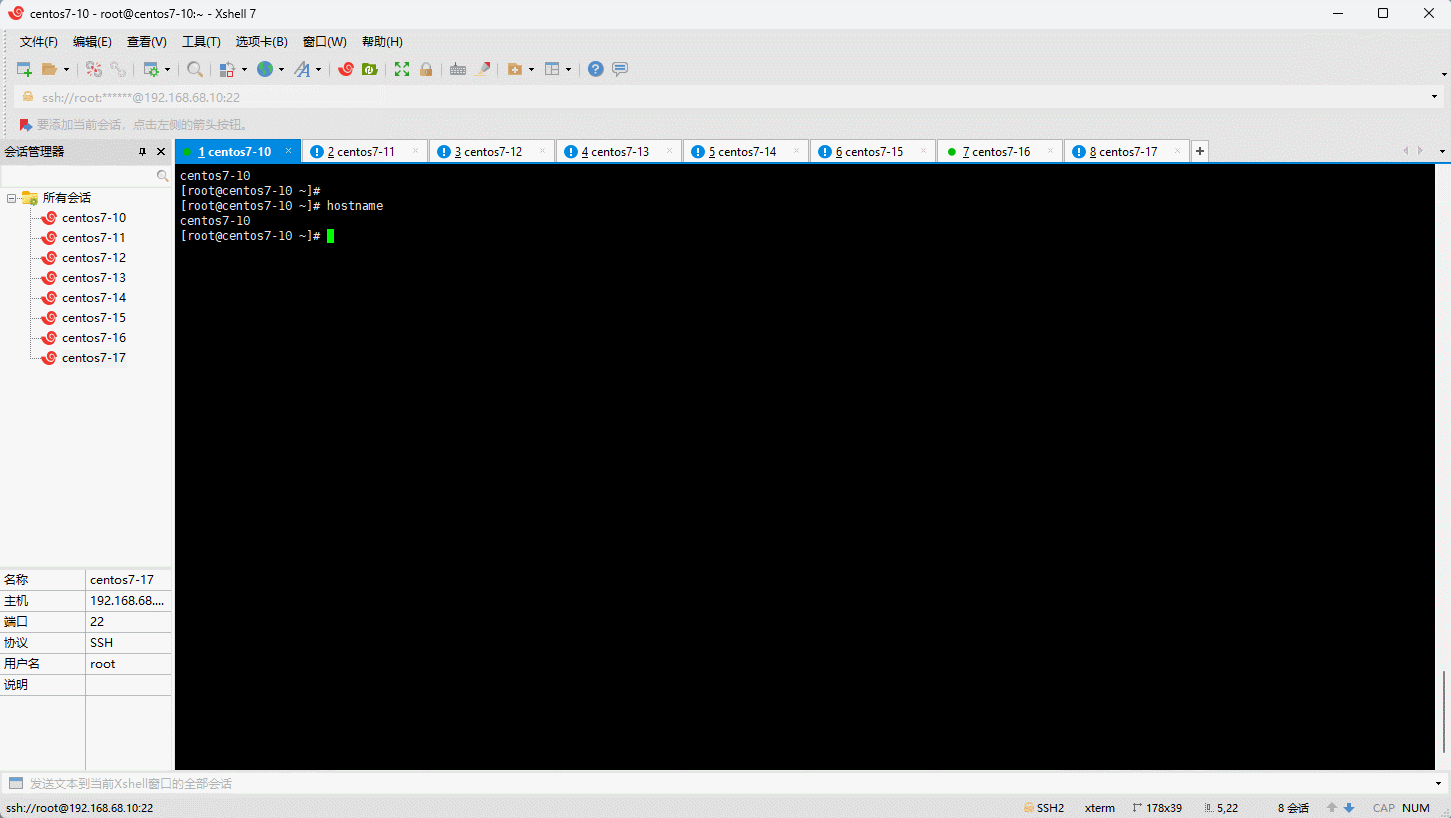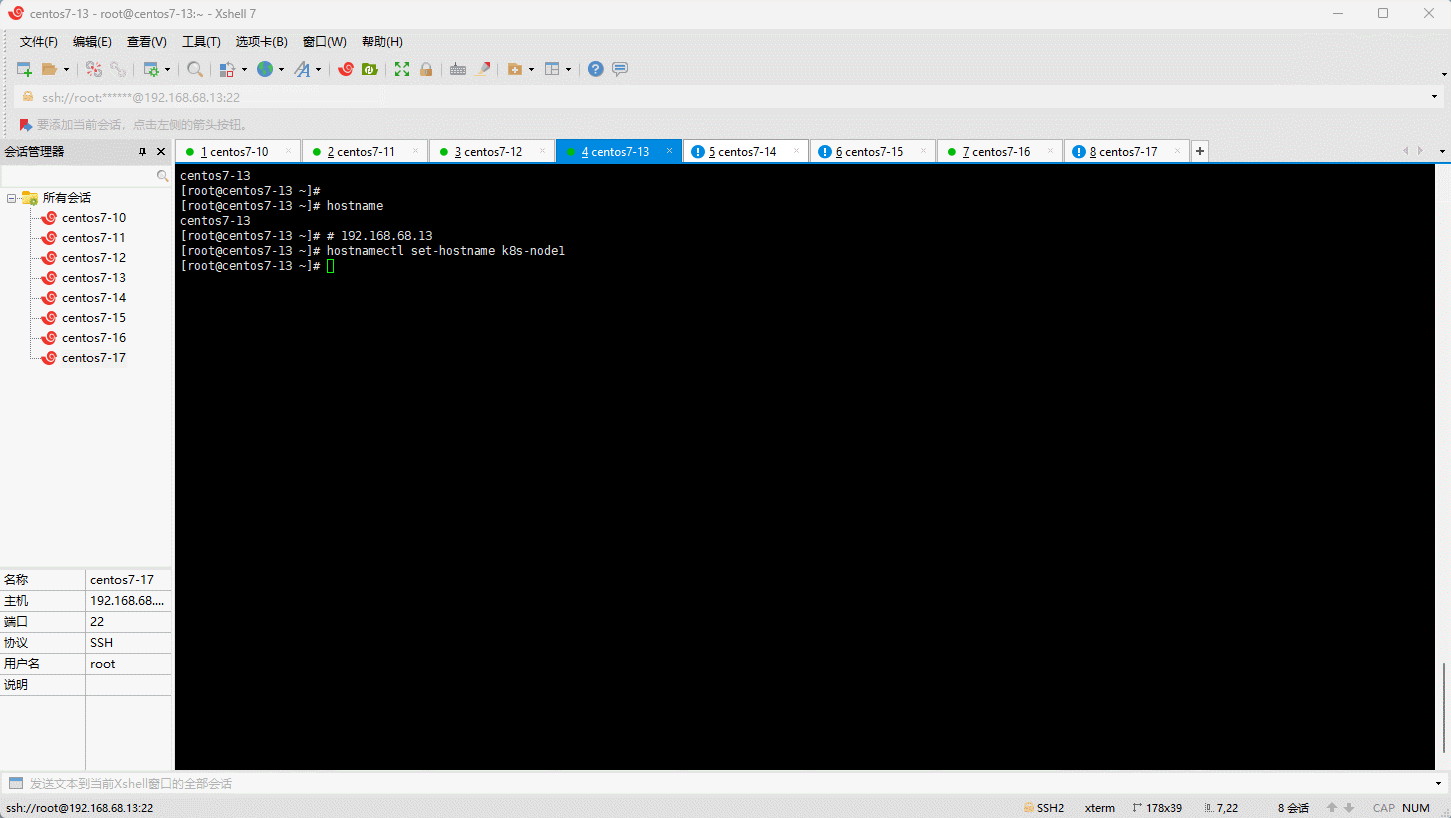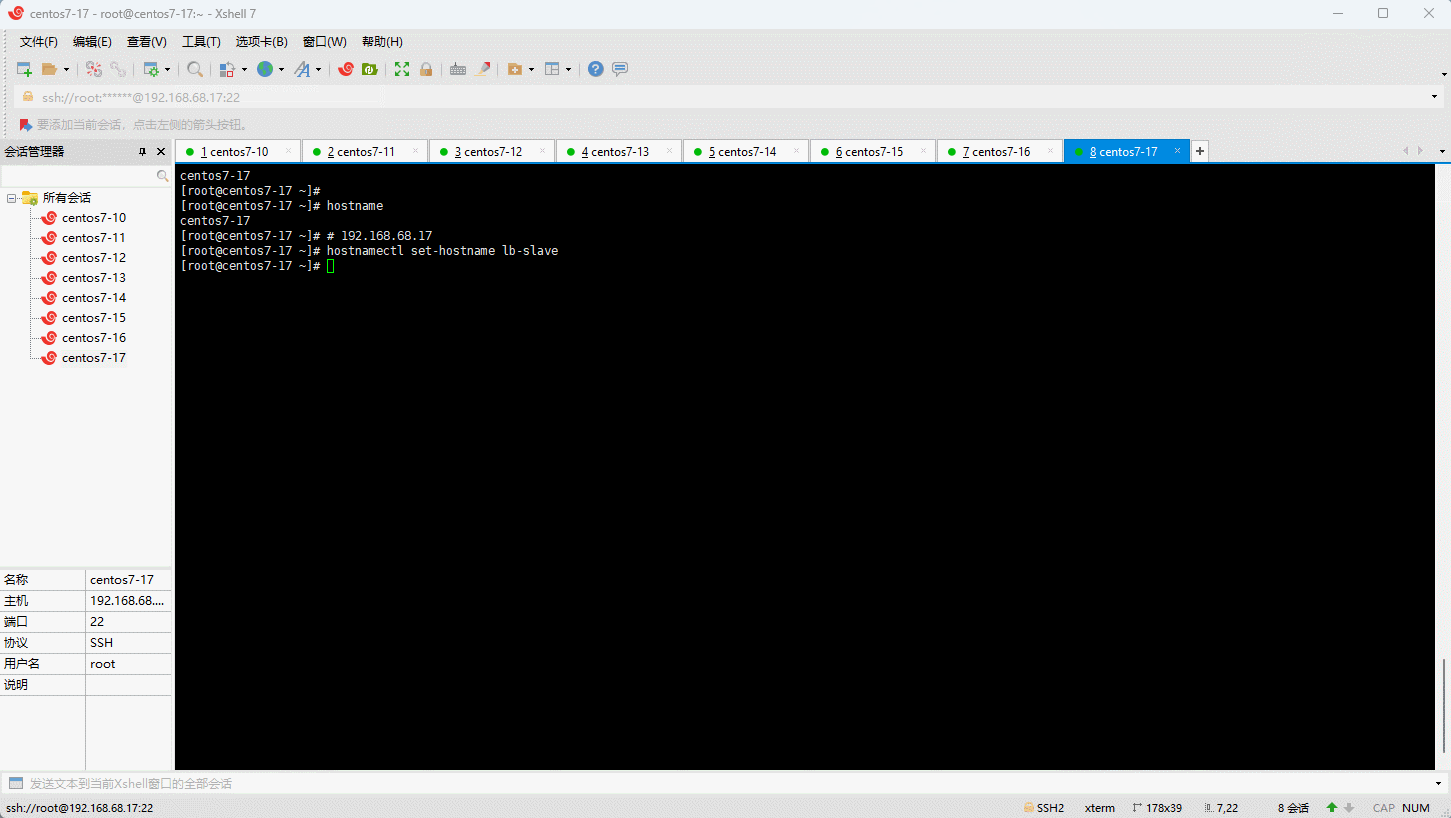
3.2 设置主机名
- 命令:
- 示例:

3.3 主机名解析
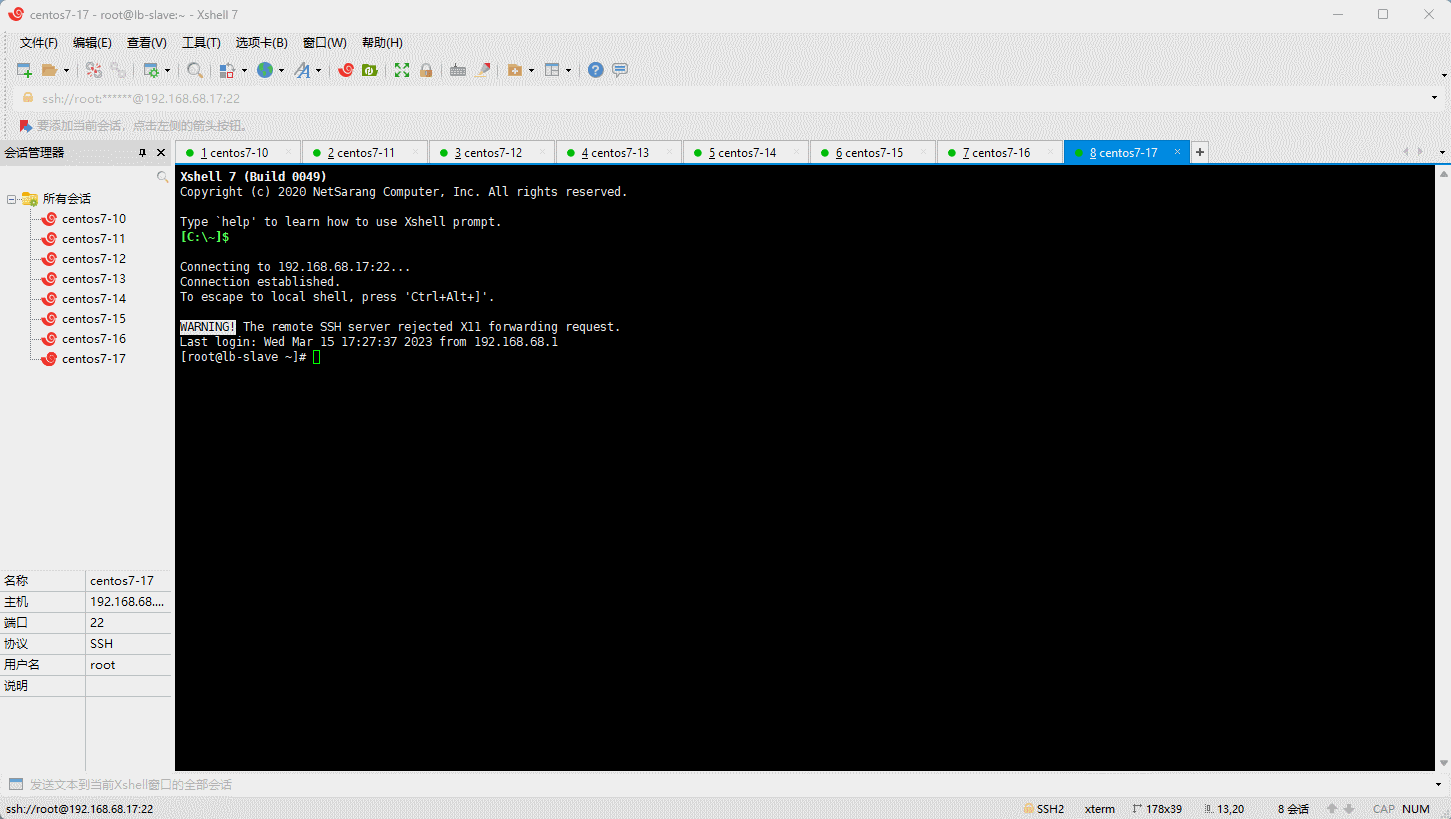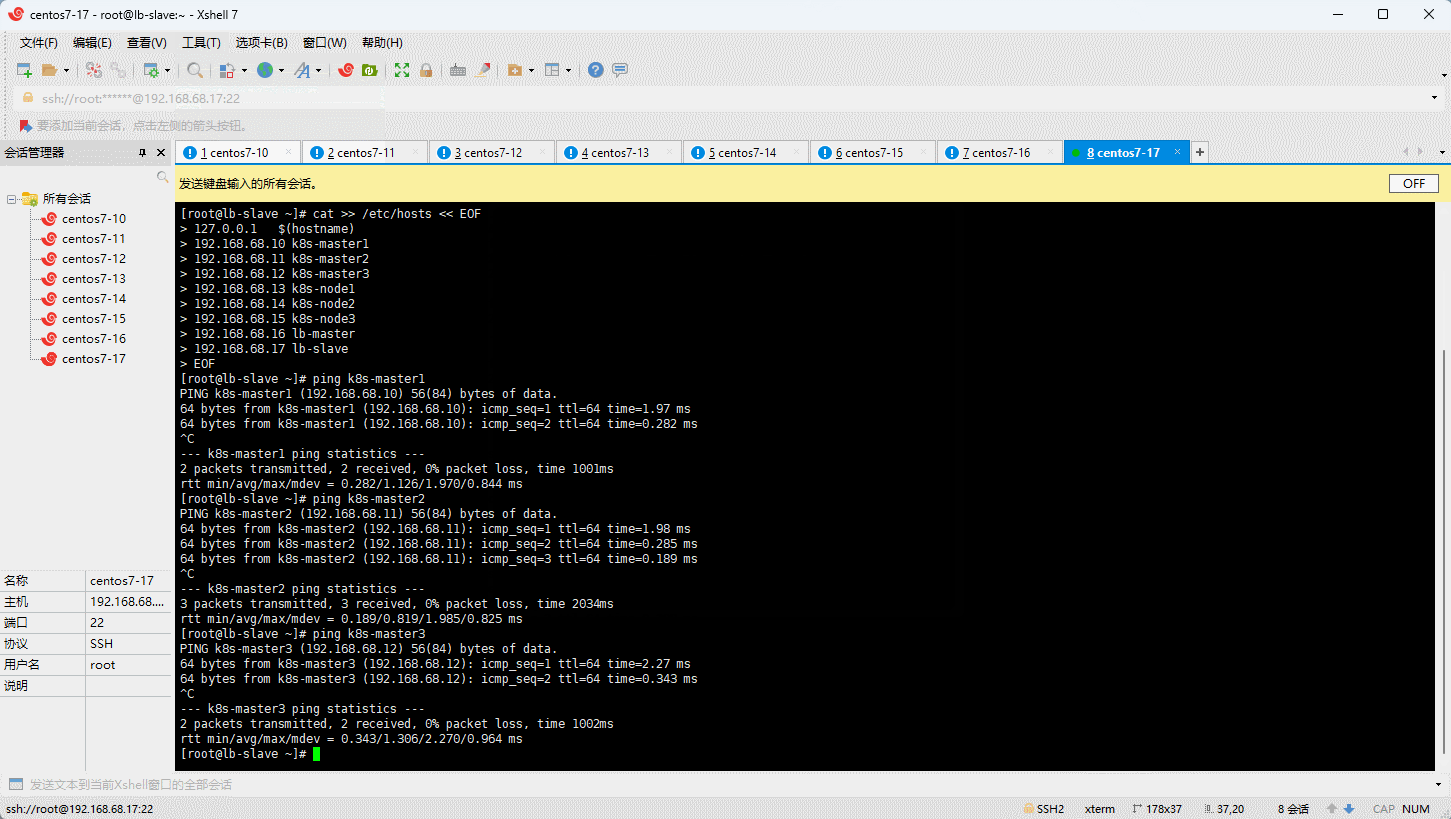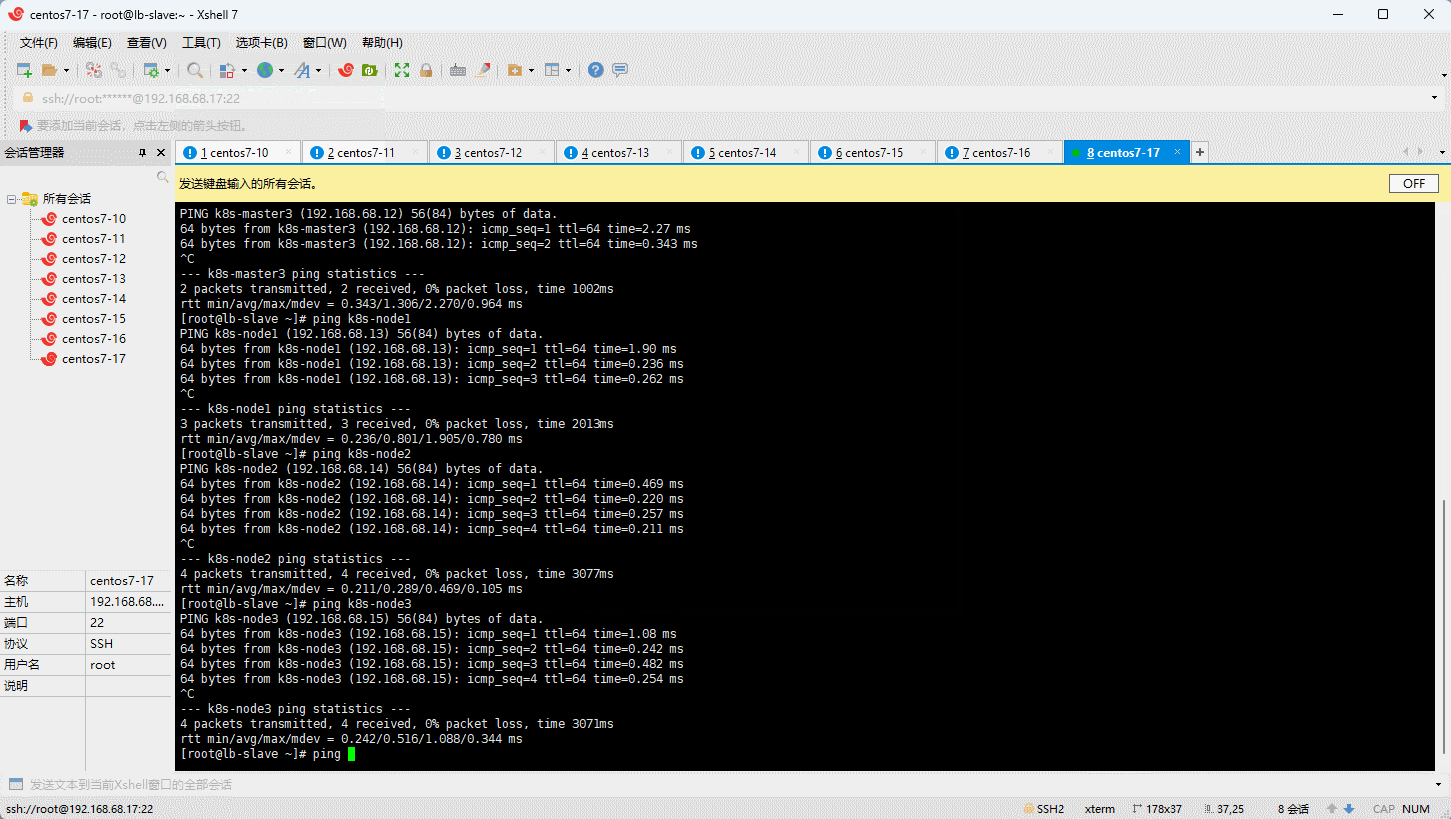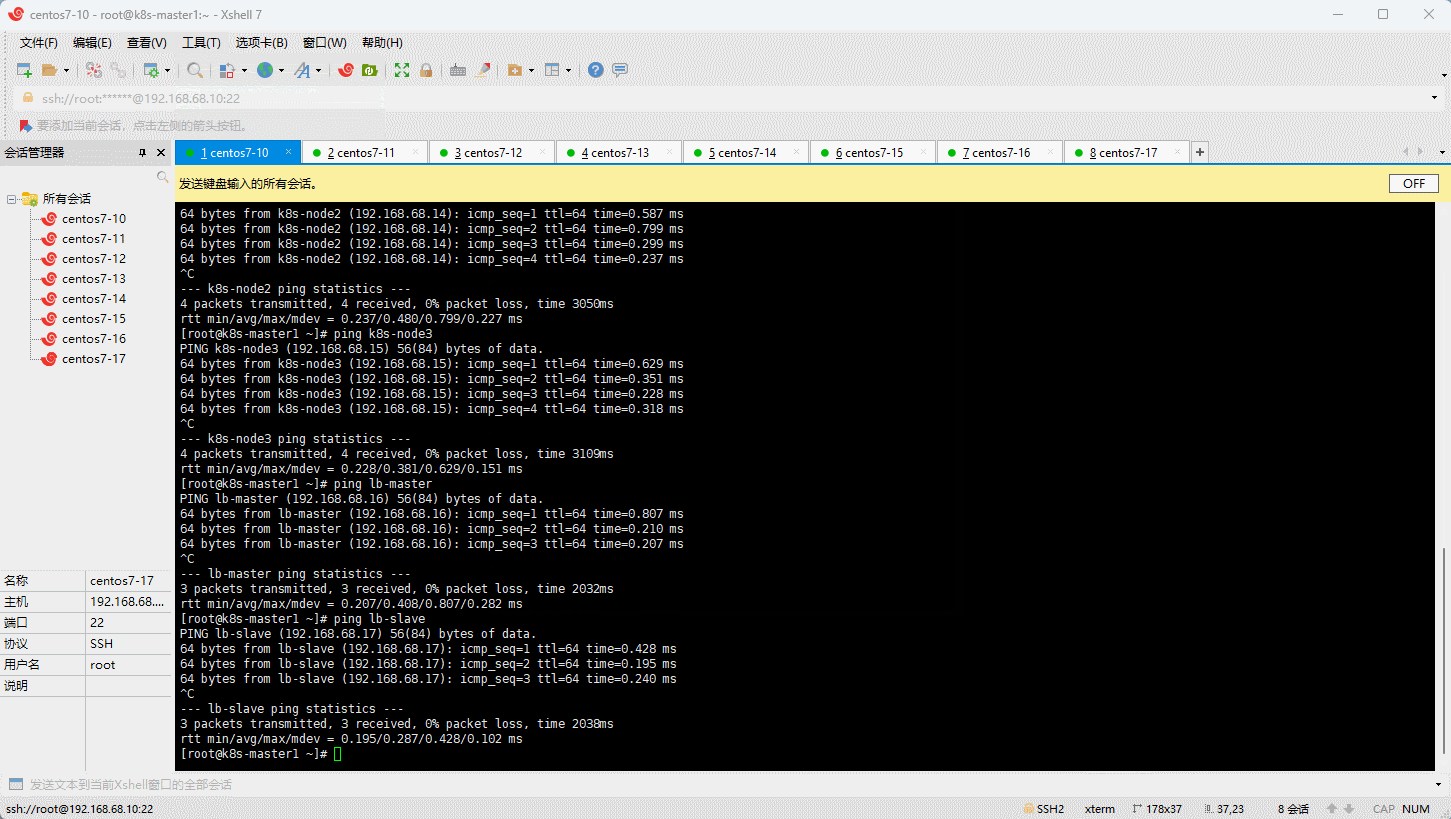
- 为了方便后面集群节点间的直接调用,需要配置一下主机名解析,企业中推荐使用内部的 DNS 服务器:
cat >> /etc/hosts << EOF
127.0.0.1 $(hostname)
192.168.68.10 k8s-master1
192.168.68.11 k8s-master2
192.168.68.12 k8s-master3
192.168.68.13 k8s-node1
192.168.68.14 k8s-node2
192.168.68.15 k8s-node3
192.168.68.16 lb-master
192.168.68.17 lb-slave
EOF

3.4 时间同步
- Kubernetes 要求集群中的节点时间必须精确一致,所以在每个节点上添加时间同步:
yum -y install ntpdate
ntpdate ntp1.aliyun.com
systemctl status ntpdate
systemctl start ntpdate
systemctl status ntpdate
systemctl enable ntpdate

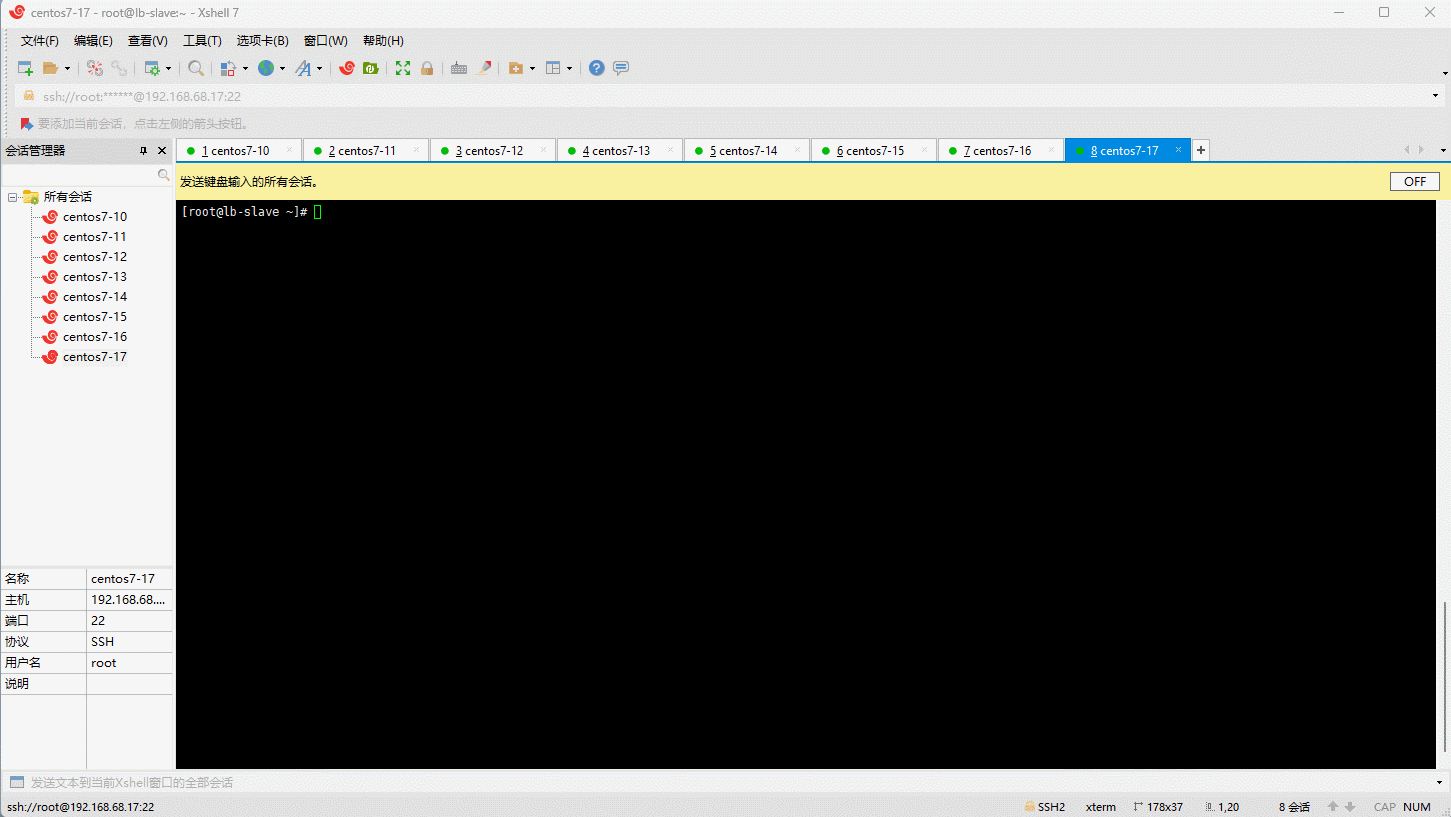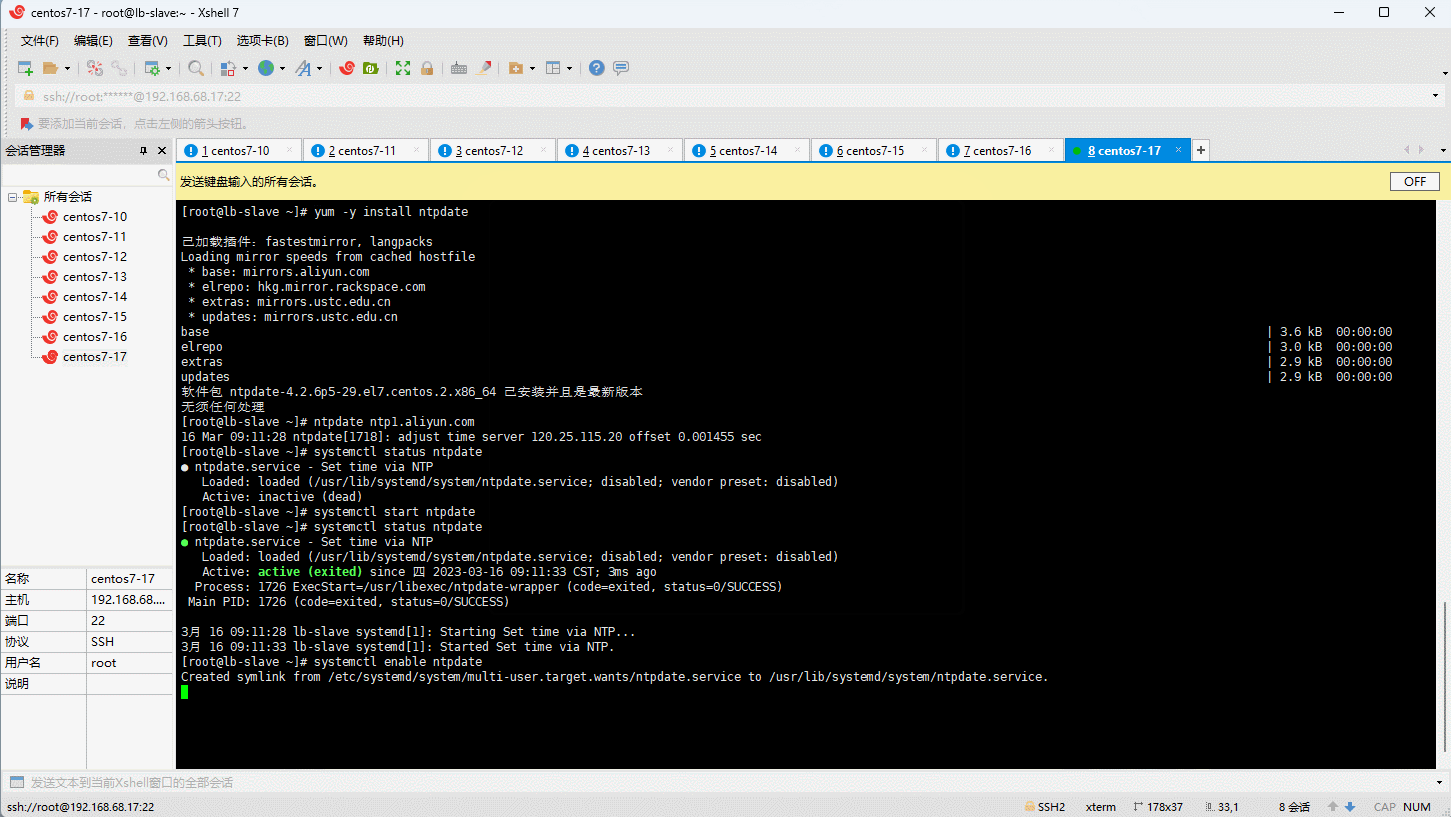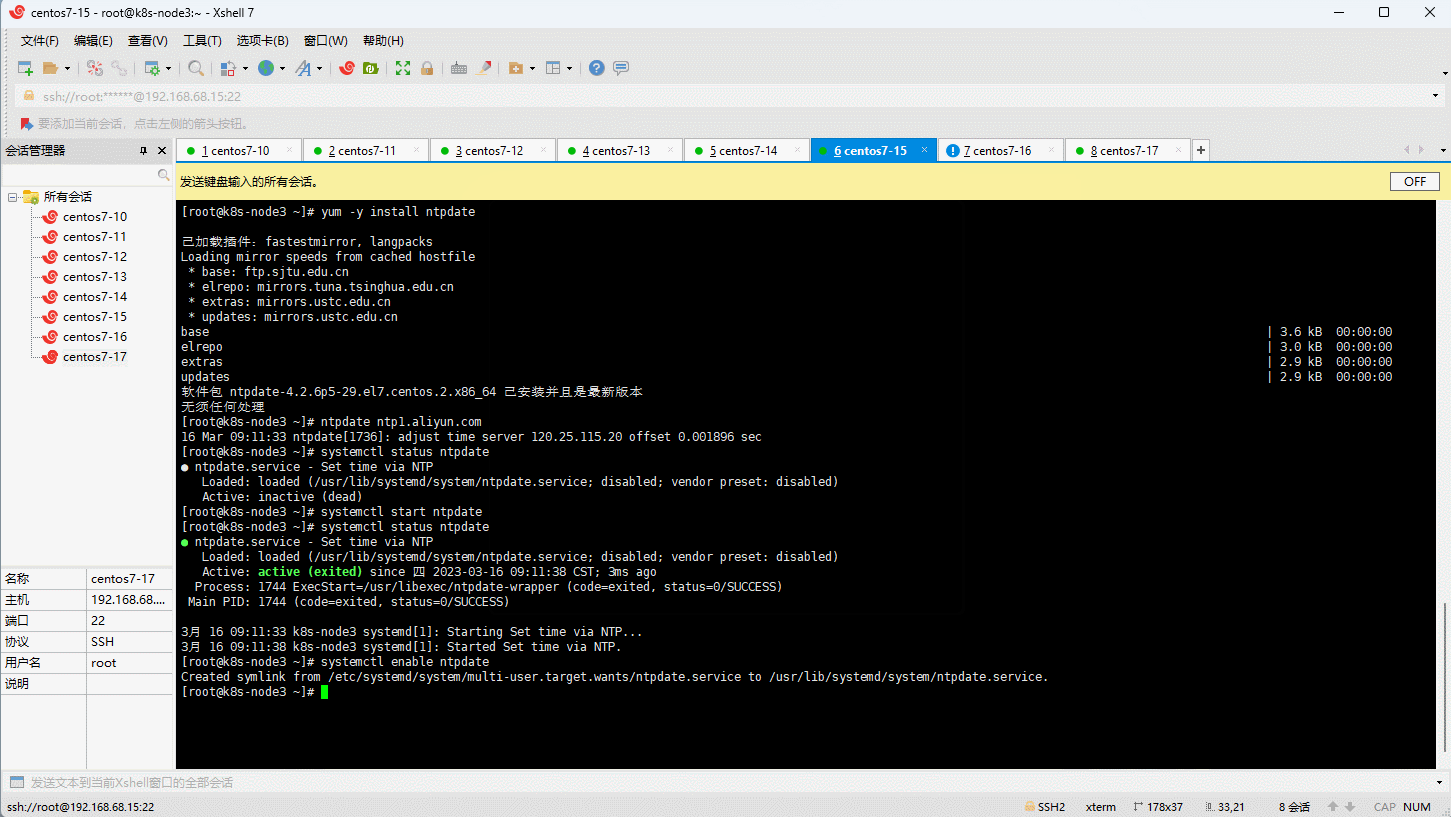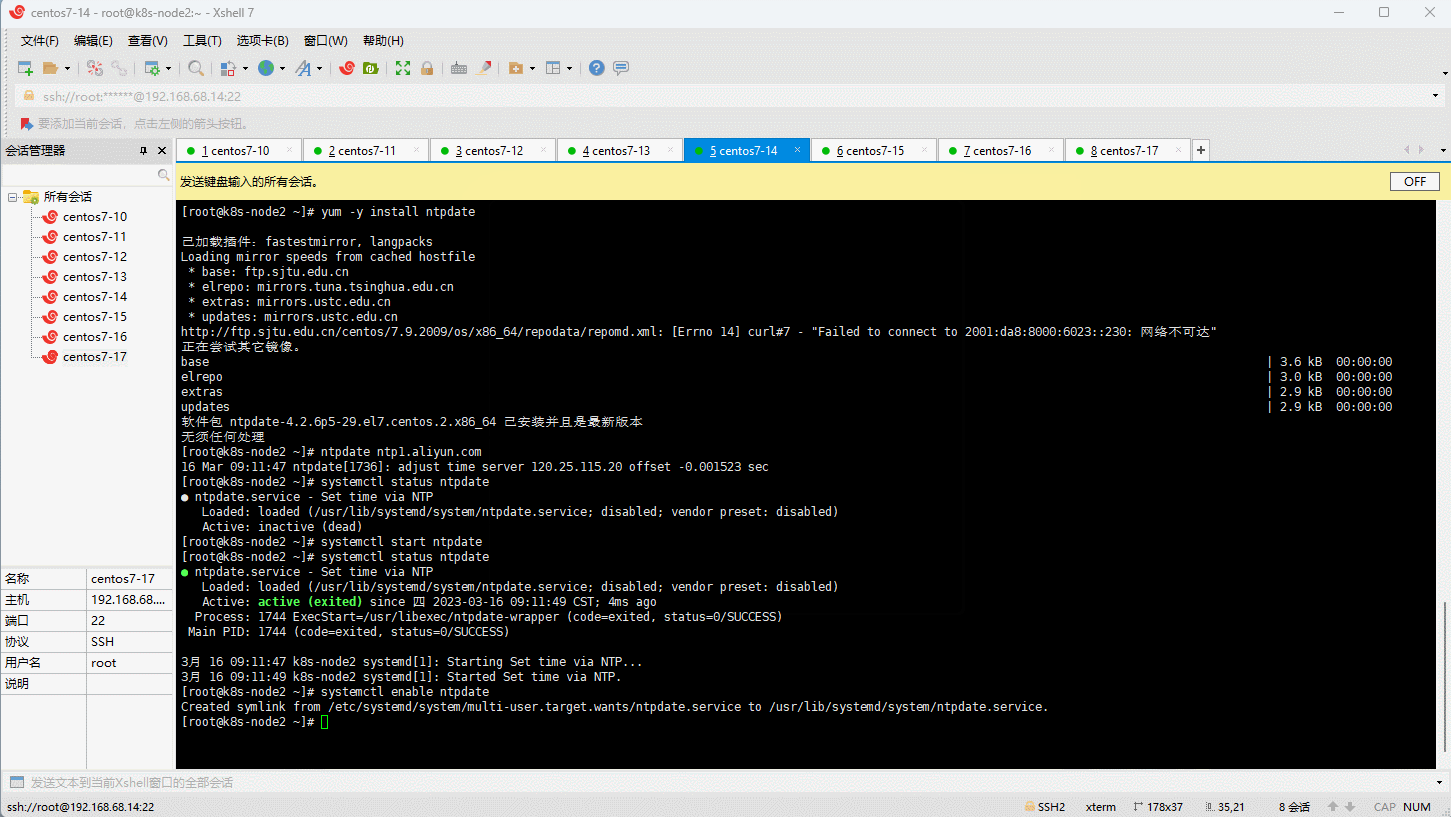
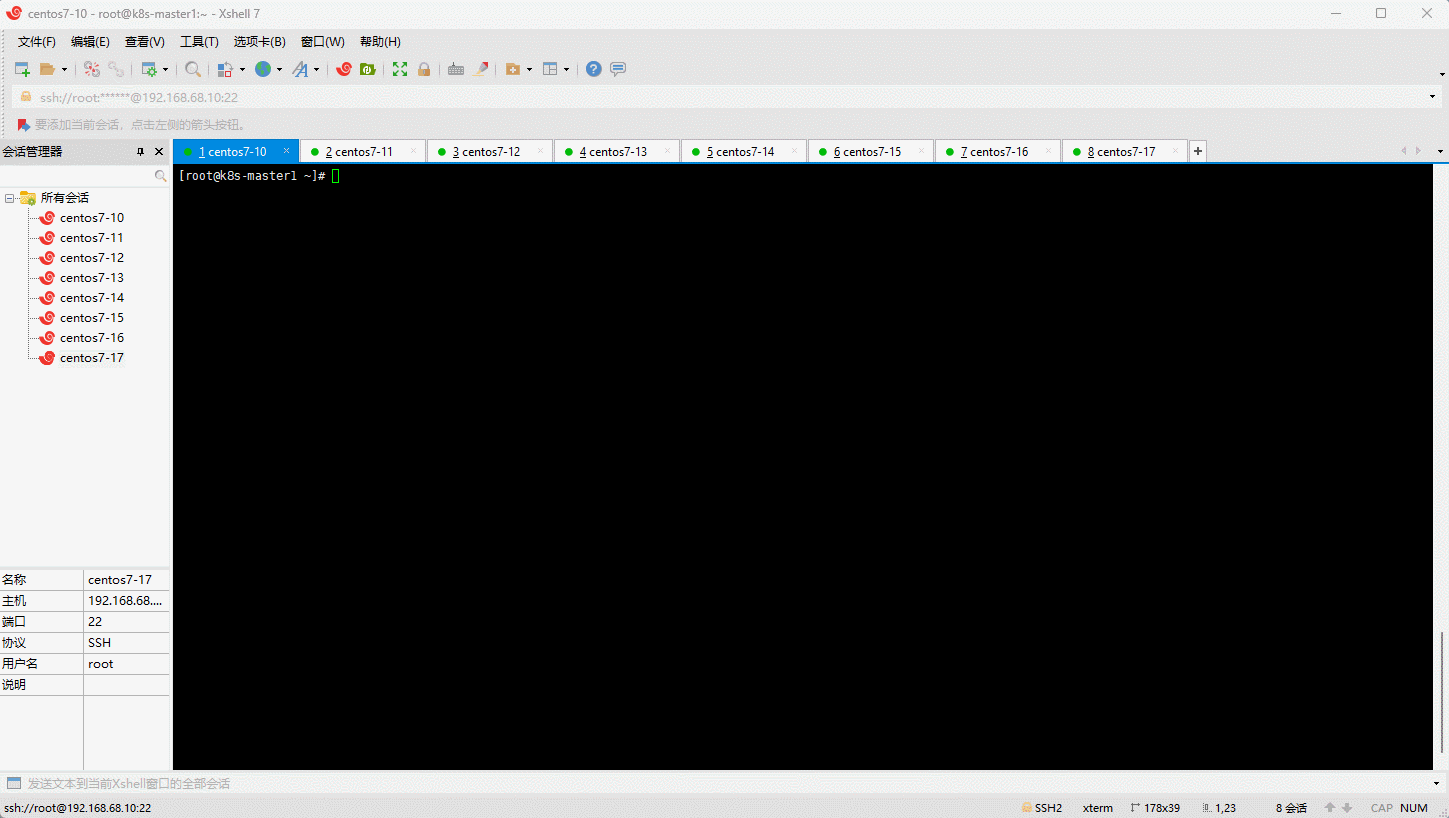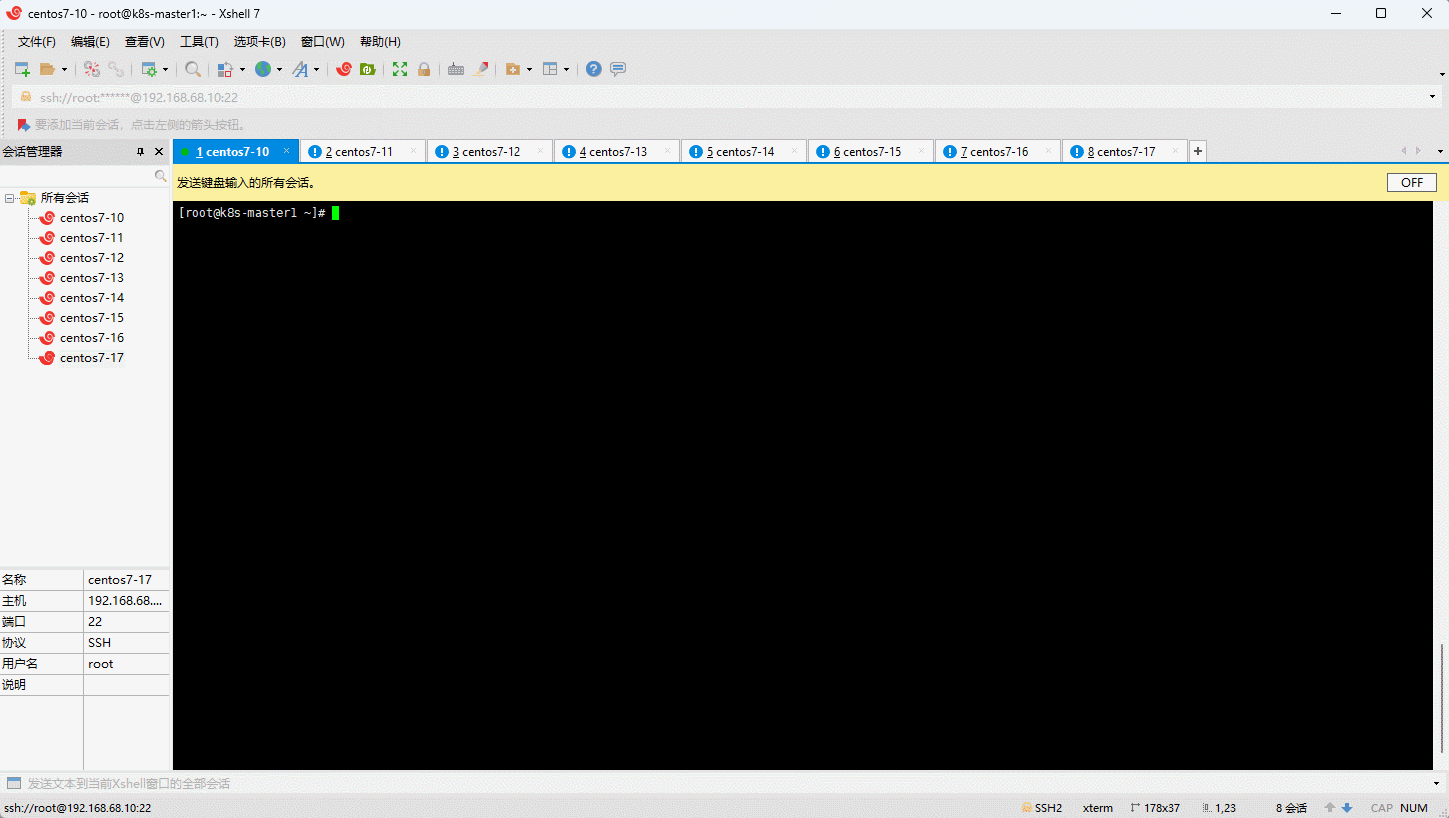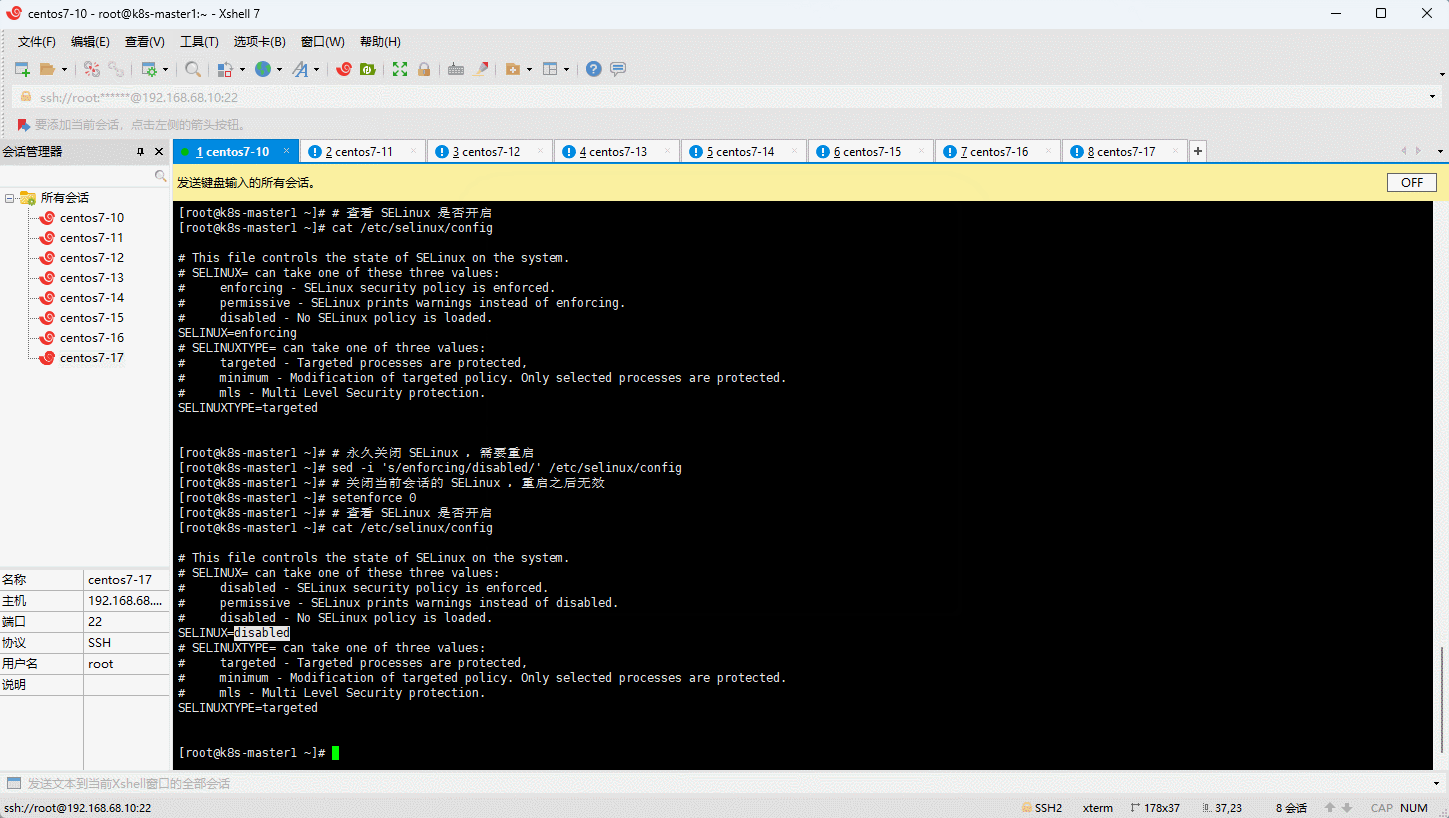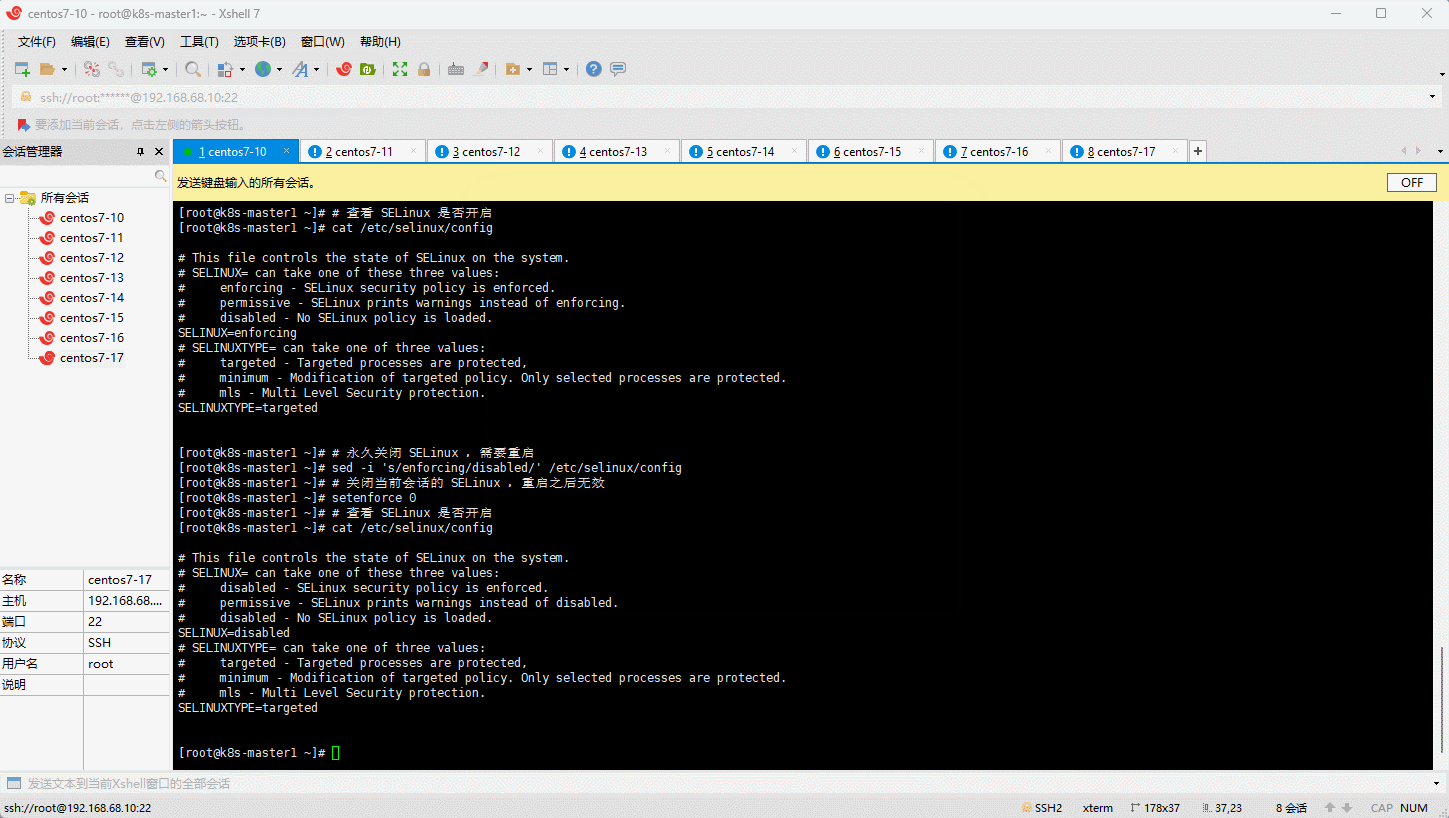
3.5 关闭 SELinux
- 容器虚拟化需要关闭 SELinux:
# 查看 SELinux 是否开启
getenforce
# 查看 SELinux 是否开启
cat /etc/selinux/config
# 永久关闭 SELinux ,需要重启
sed -i 's/enforcing/disabled/' /etc/selinux/config
# 关闭当前会话的 SELinux ,重启之后无效
setenforce 0
# 查看 SELinux 是否开启
cat /etc/selinux/config

3.6 关闭 swap 分区
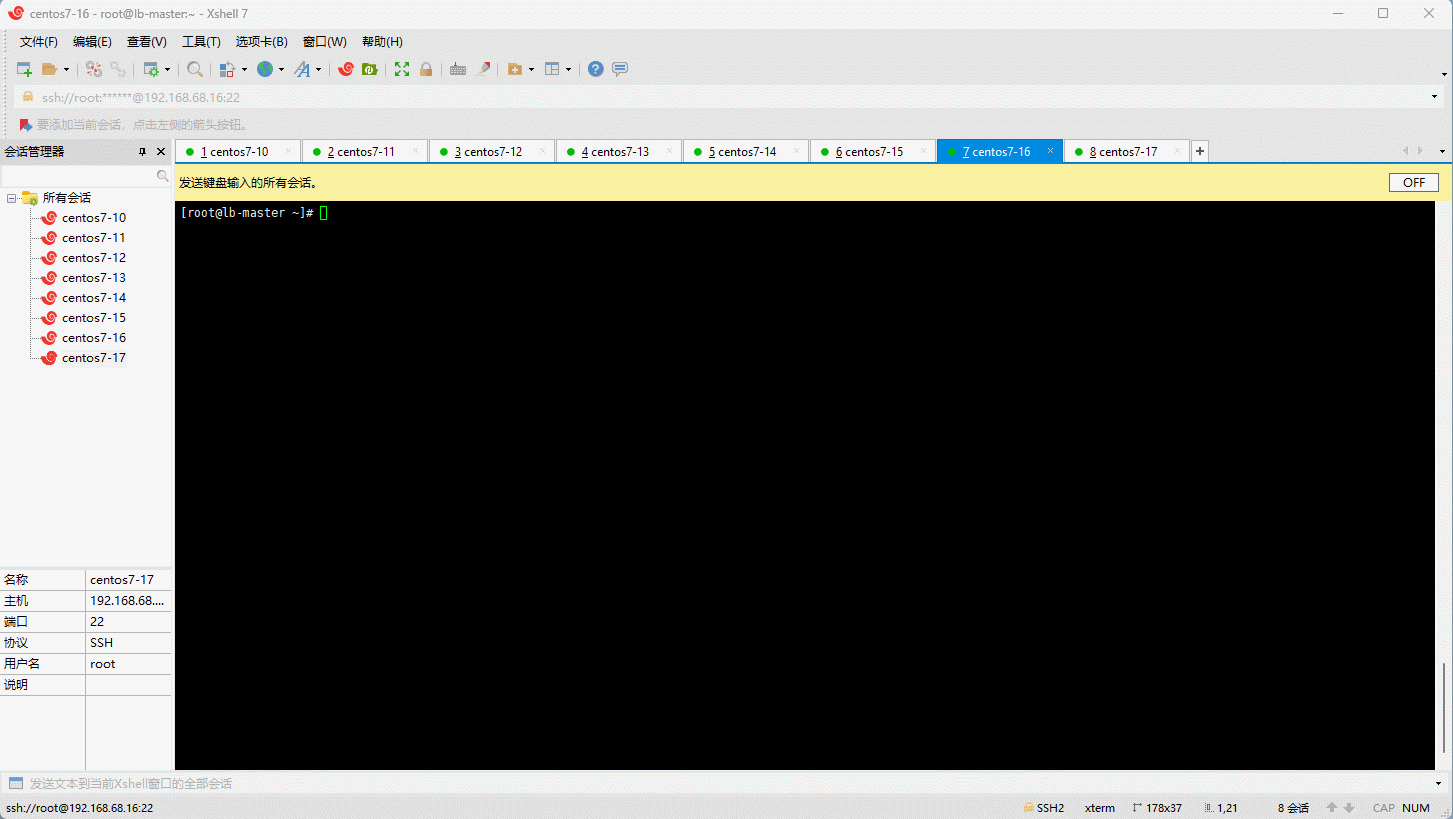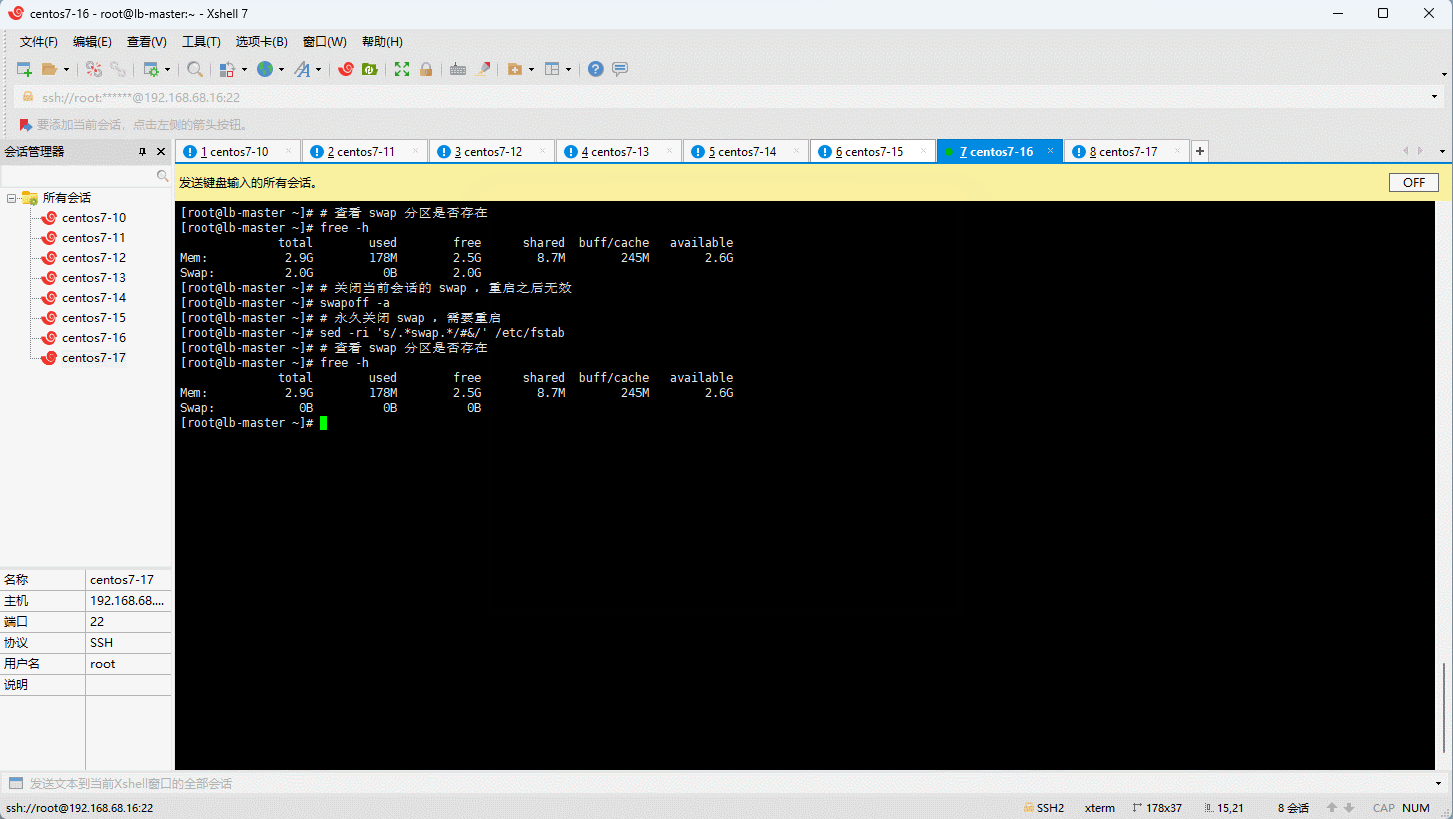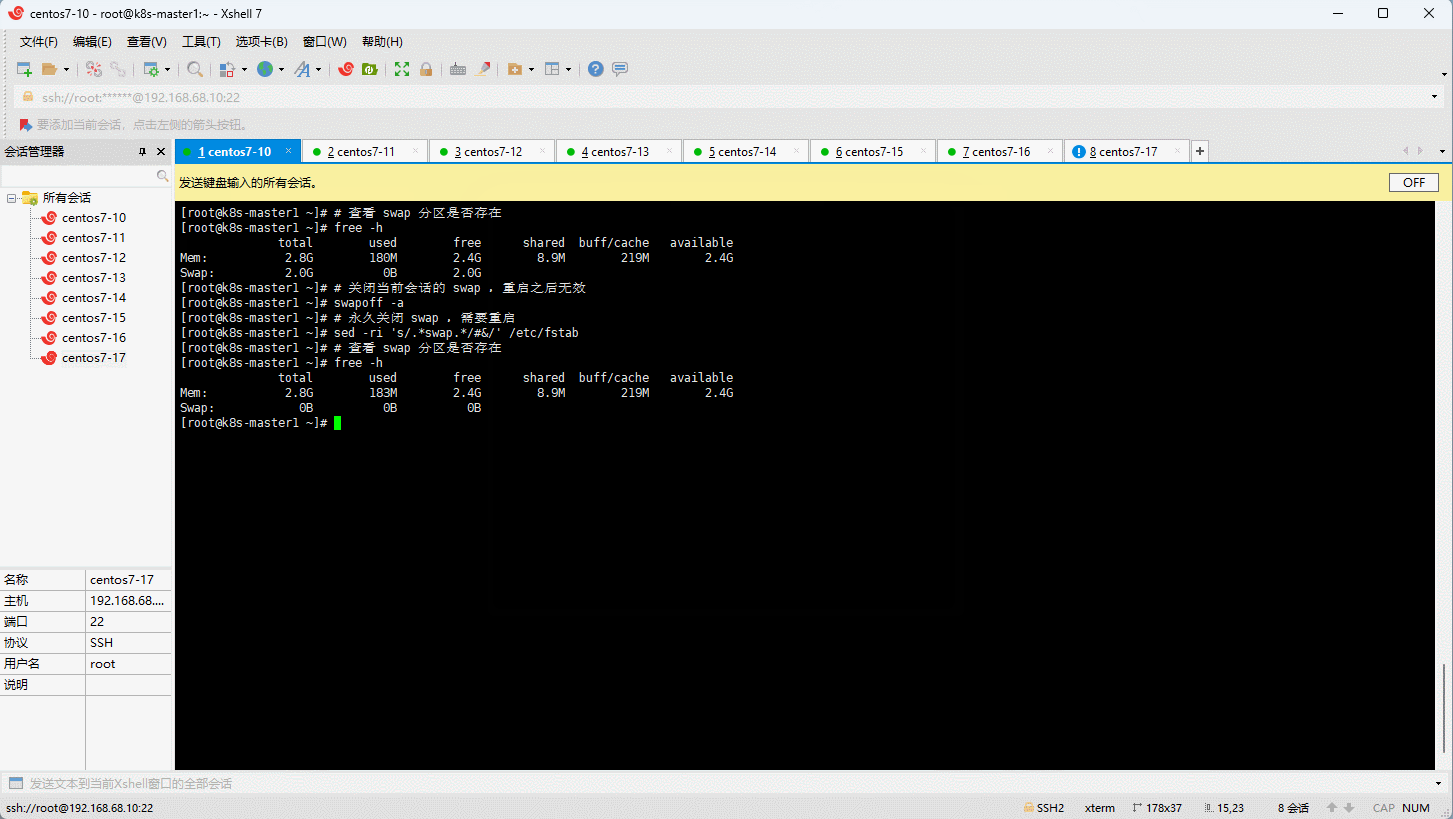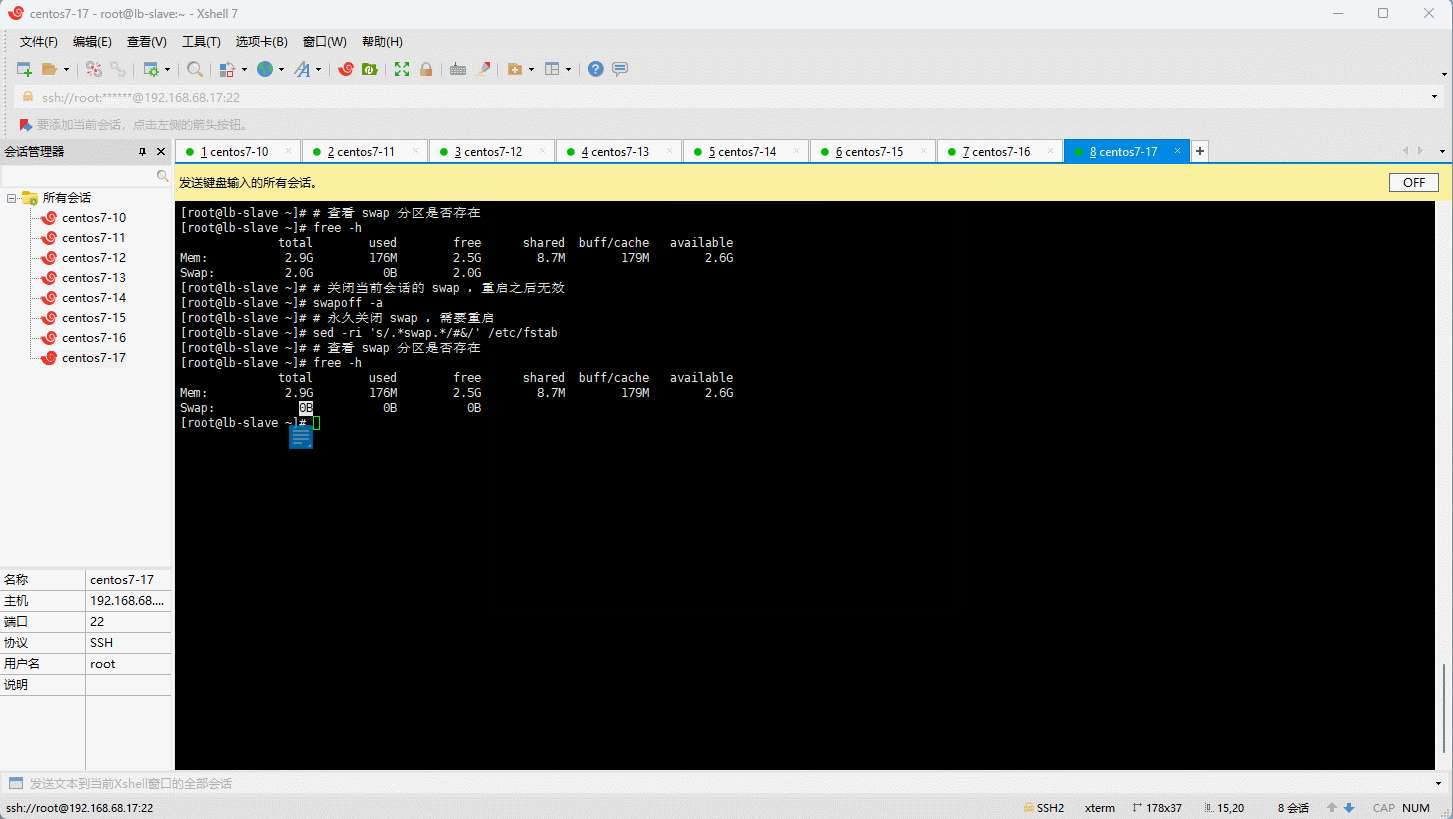
- 容器虚拟化需要关闭 swap 分区:
# 查看 swap 分区是否存在
free -h
# 关闭当前会话的 swap ,重启之后无效
swapoff -a
# 永久关闭 swap ,需要重启
sed -ri 's/.*swap.*/#&/' /etc/fstab
# 查看 swap 分区是否存在
free -h

3.7 将桥接的 IPv4 流量传递到 iptables 的链
- 修改 /etc/sysctl.conf 文件:
# 如果有配置,则修改
sed -i "s#^net.ipv4.ip_forward.*#net.ipv4.ip_forward=1#g" /etc/sysctl.conf
sed -i "s#^net.bridge.bridge-nf-call-ip6tables.*#net.bridge.bridge-nf-call-ip6tables=1#g" /etc/sysctl.conf
sed -i "s#^net.bridge.bridge-nf-call-iptables.*#net.bridge.bridge-nf-call-iptables=1#g" /etc/sysctl.conf
sed -i "s#^net.ipv6.conf.all.disable_ipv6.*#net.ipv6.conf.all.disable_ipv6=1#g" /etc/sysctl.conf
sed -i "s#^net.ipv6.conf.default.disable_ipv6.*#net.ipv6.conf.default.disable_ipv6=1#g" /etc/sysctl.conf
sed -i "s#^net.ipv6.conf.lo.disable_ipv6.*#net.ipv6.conf.lo.disable_ipv6=1#g" /etc/sysctl.conf
sed -i "s#^net.ipv6.conf.all.forwarding.*#net.ipv6.conf.all.forwarding=1#g" /etc/sysctl.conf
# 可能没有,追加
echo "net.ipv4.ip_forward = 1" >> /etc/sysctl.conf
echo "net.bridge.bridge-nf-call-ip6tables = 1" >> /etc/sysctl.conf
echo "net.bridge.bridge-nf-call-iptables = 1" >> /etc/sysctl.conf
echo "net.ipv6.conf.all.disable_ipv6 = 1" >> /etc/sysctl.conf
echo "net.ipv6.conf.default.disable_ipv6 = 1" >> /etc/sysctl.conf
echo "net.ipv6.conf.lo.disable_ipv6 = 1" >> /etc/sysctl.conf
echo "net.ipv6.conf.all.forwarding = 1" >> /etc/sysctl.conf
- 加载 br_netfilter 模块:
- 持久化修改(保留配置包本地文件,重启系统或服务进程仍然有效):

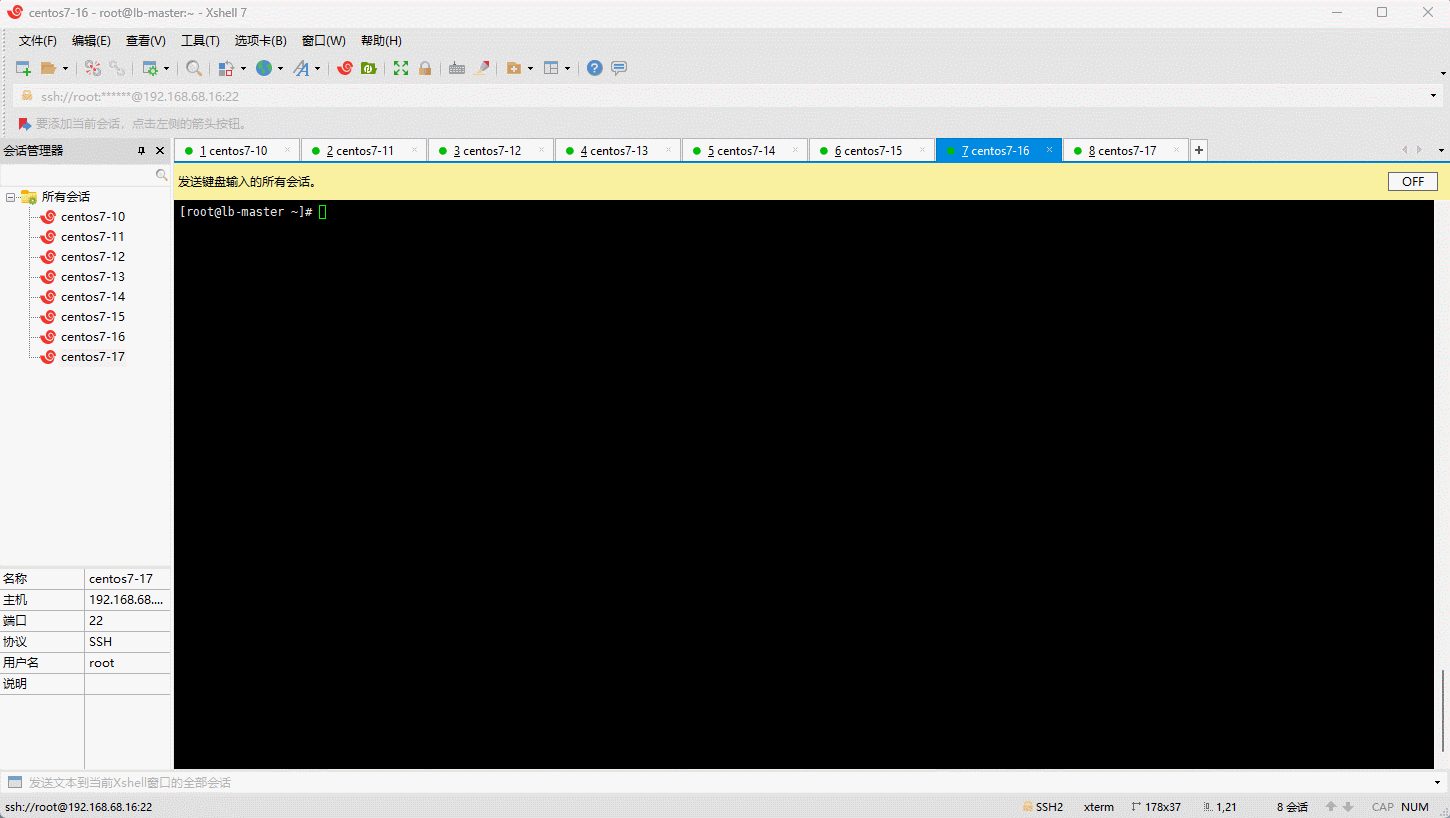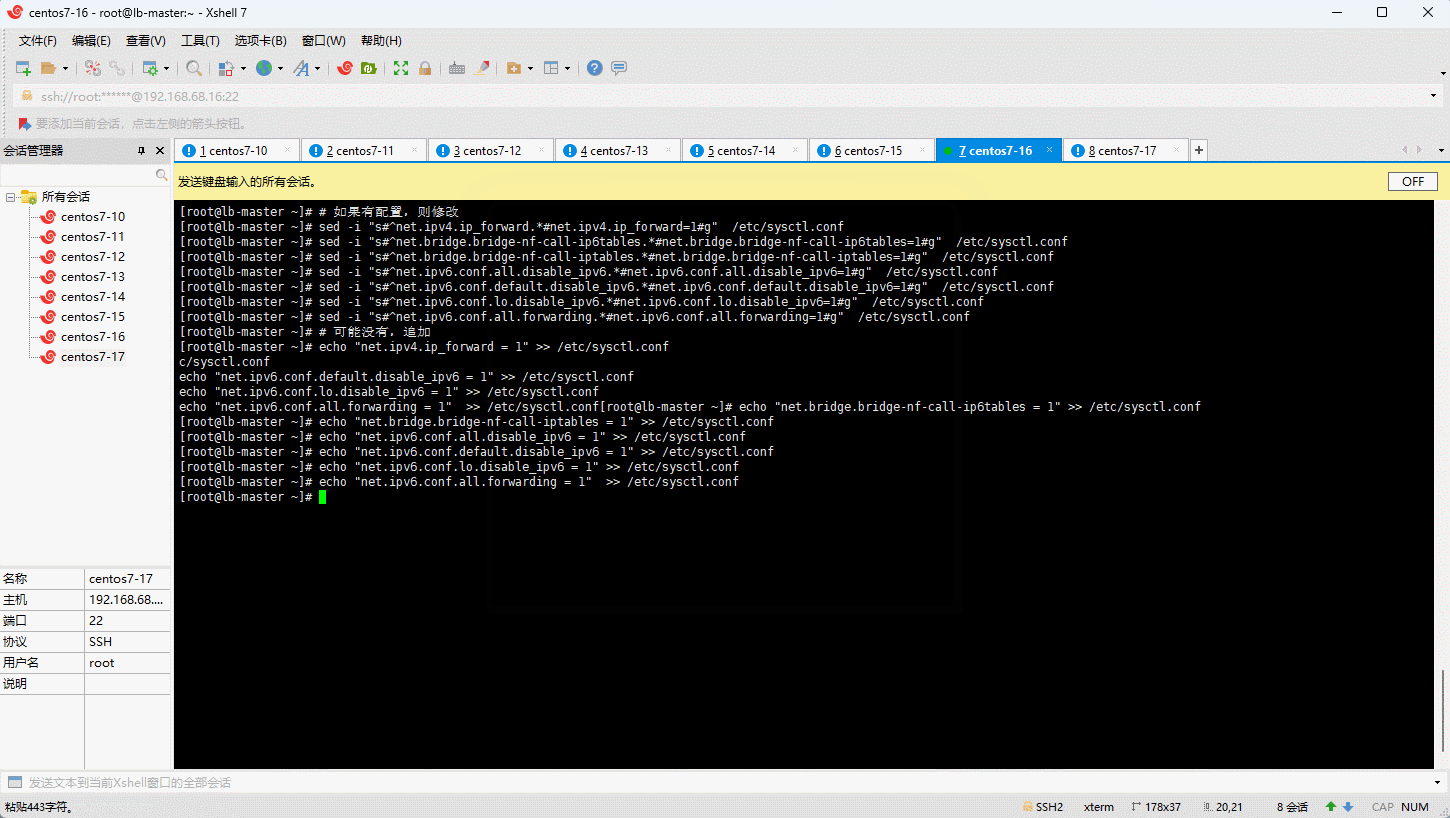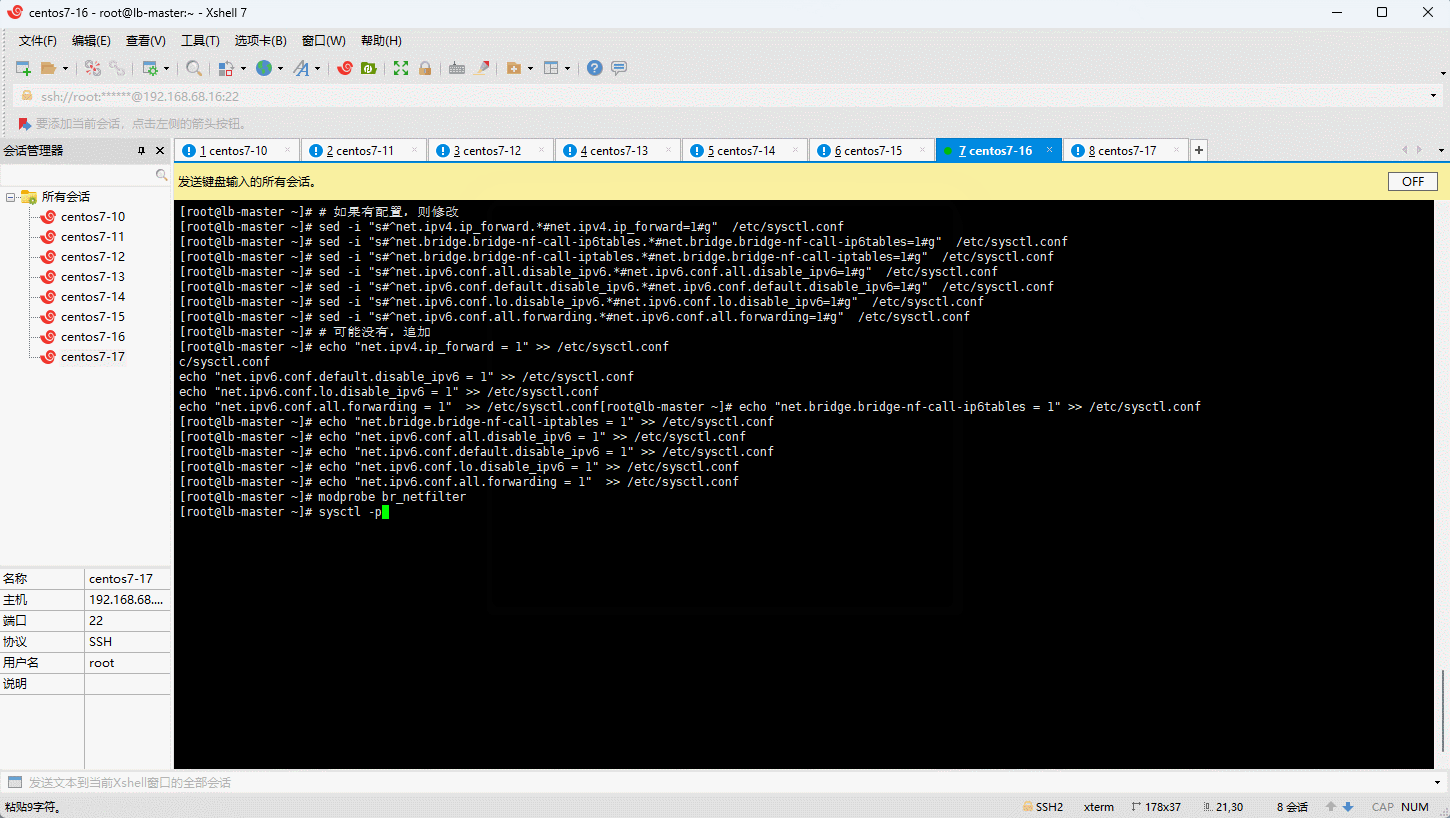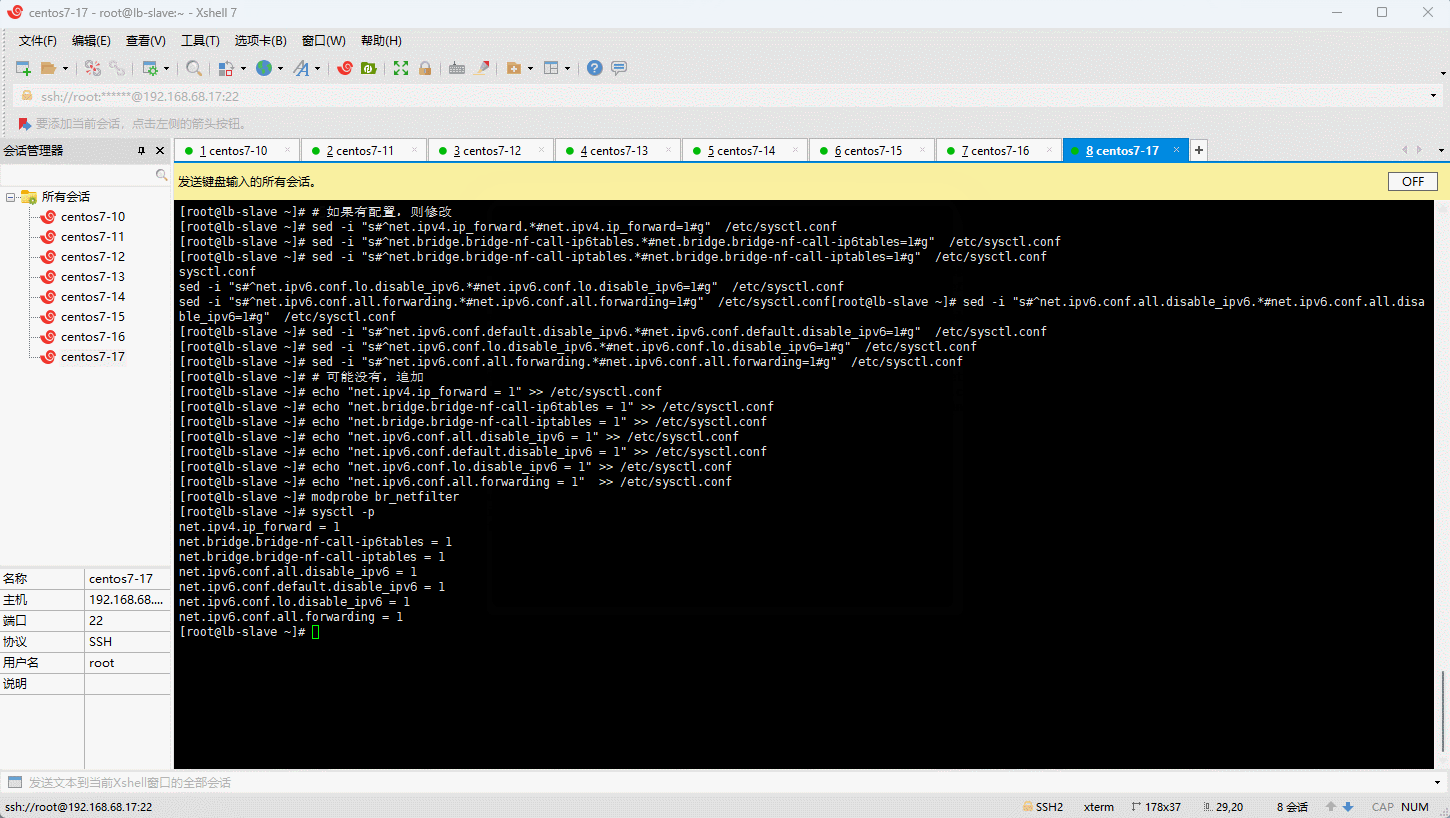
3.8 开启 ipvs
- 在 Kubernetes 中 service 有两种代理模型,一种是基于 iptables ,另一种是基于 ipvs 的。ipvs 的性能要高于 iptables 的,但是如果要使用它,需要手动载入 ipvs 模块。
# 安装 ipset 和 ipvsadm
yum -y install ipset ipvsadm
# 执行如下脚本
cat > /etc/sysconfig/modules/ipvs.modules <<EOF
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack
EOF
# 授权、运行、检查是否加载
chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep -e ip_vs -e nf_conntrack_ipv4

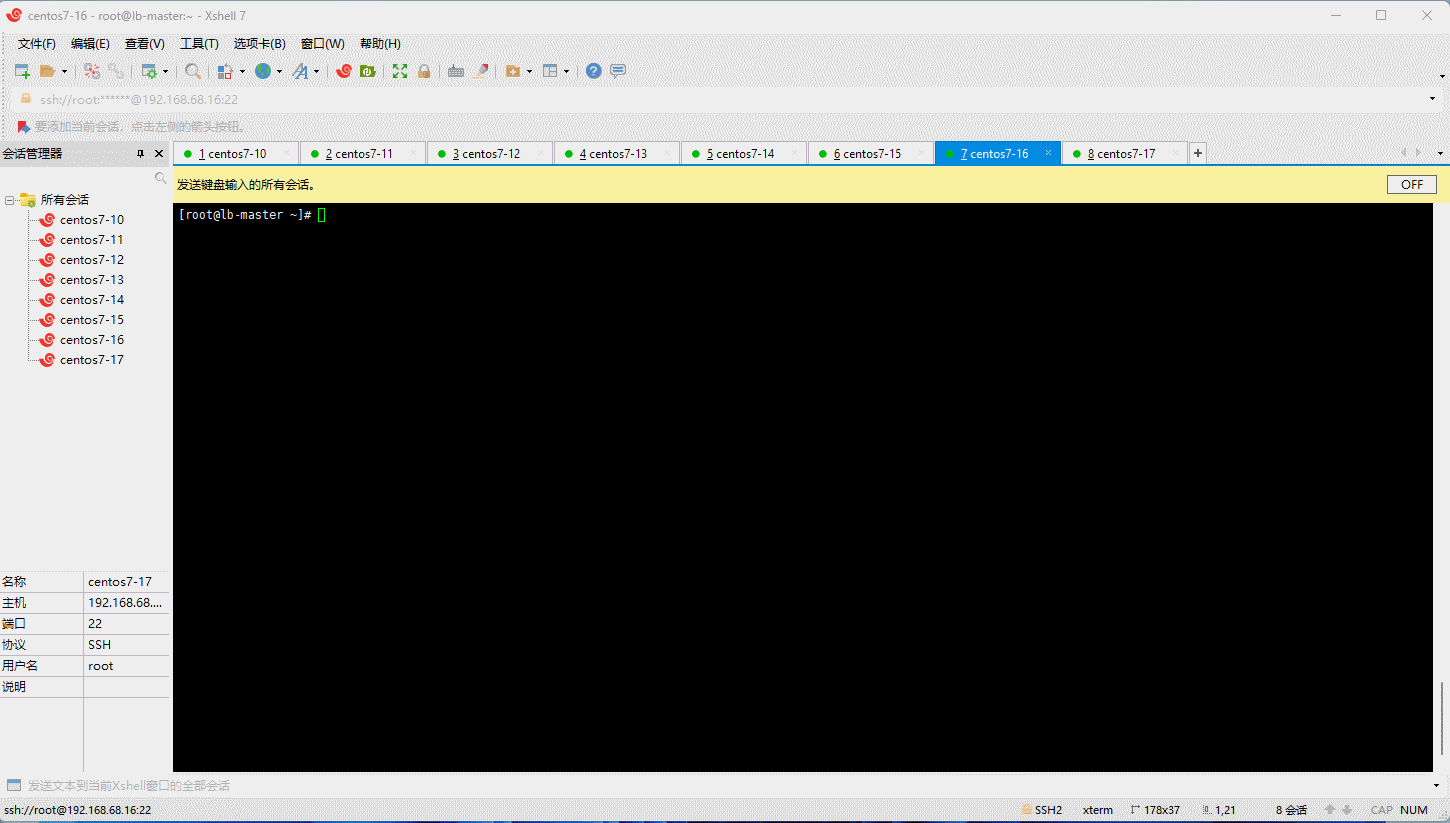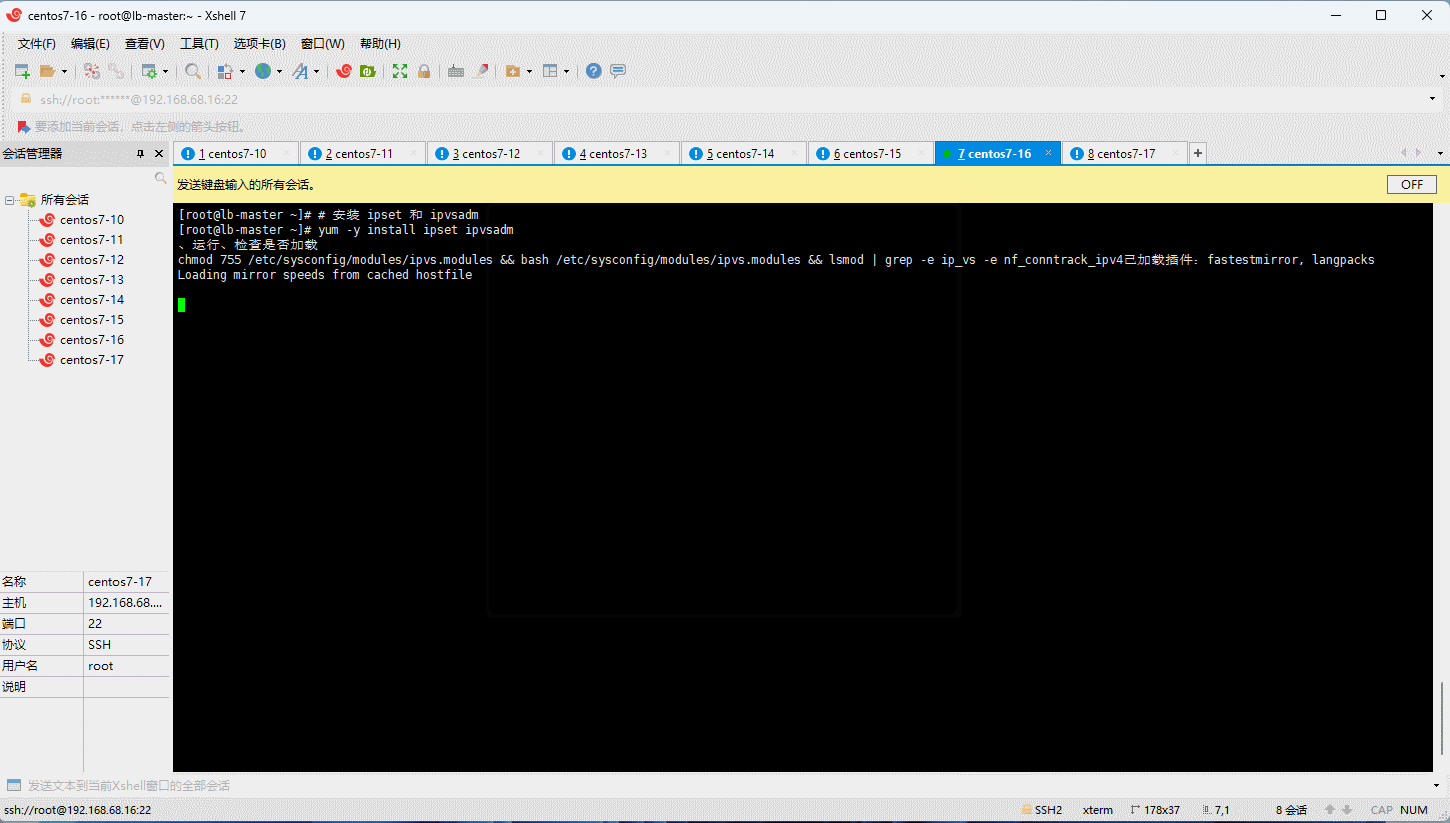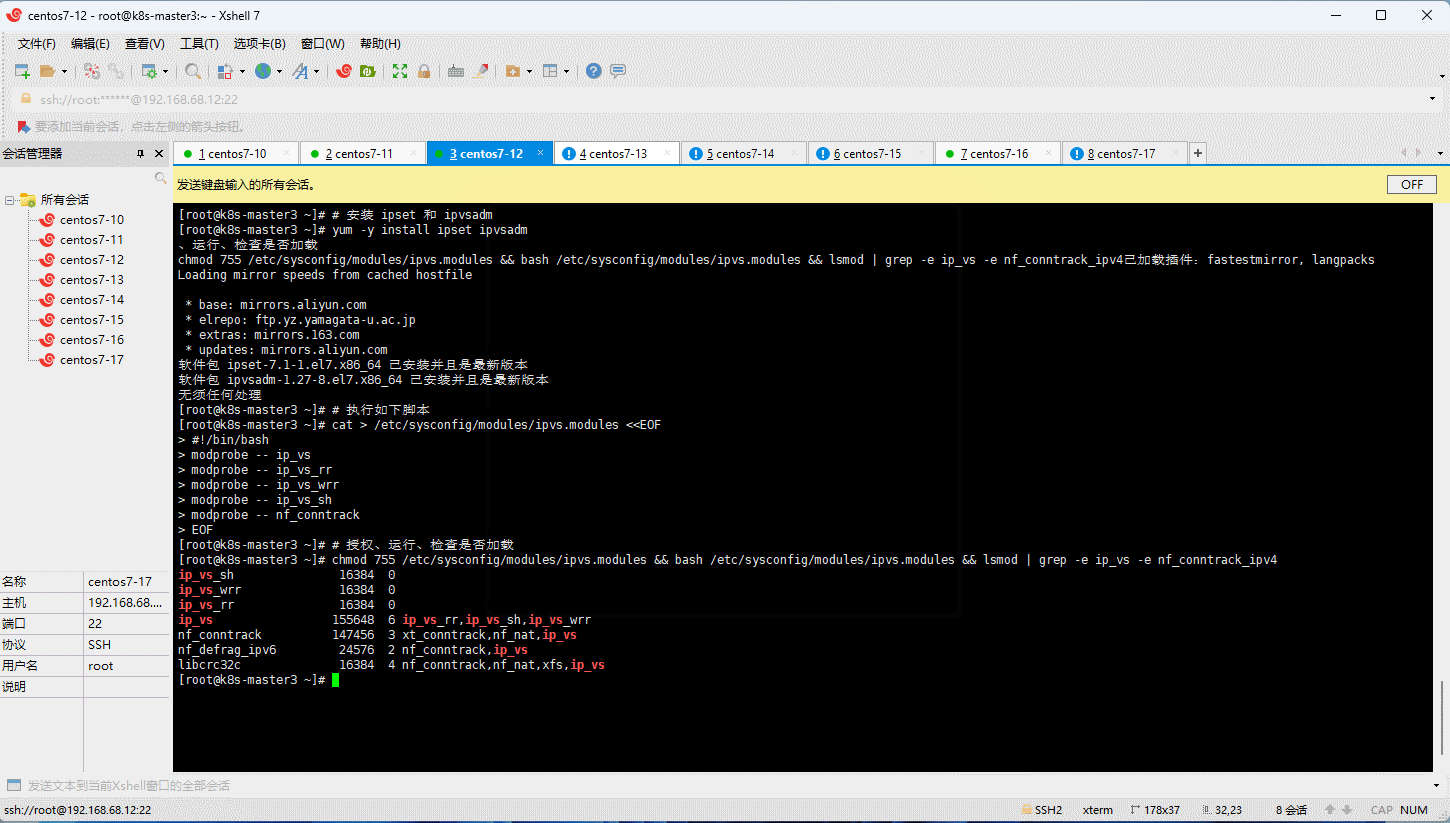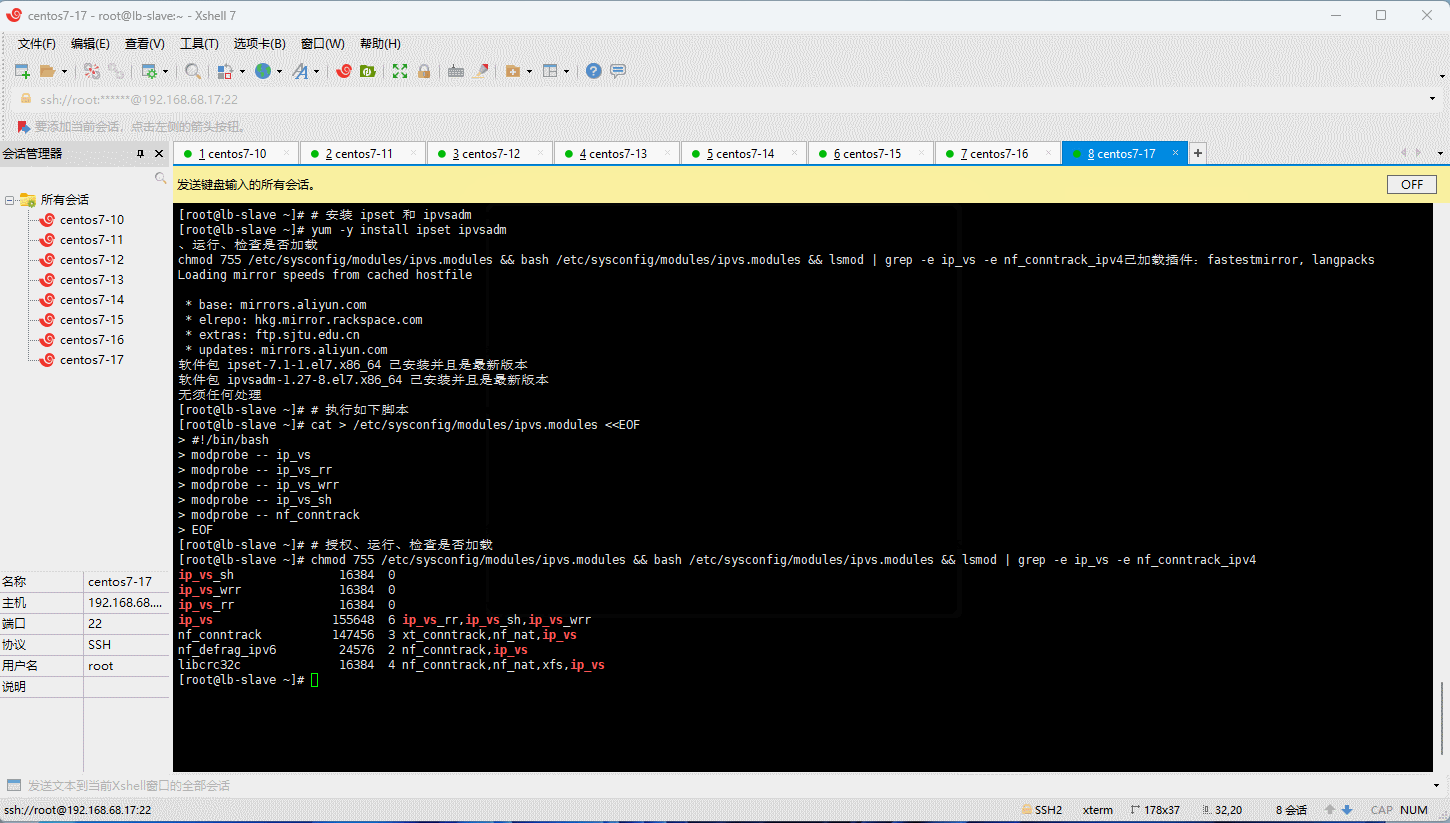
3.9 关闭防火墙
- 学习阶段可以关闭防火墙,并且公有云上也没有防火墙,只有安全组。
# 查看防火墙状态
systemctl status firewalld
# 临时关闭防火墙
systemctl stop firewalld
# 禁止开机自动启动防火墙
systemctl disable firewalld
# 查看防火墙状态
systemctl status firewalld

3.10 重启系统(可选)
- 重启系统,以便永久配置生效(不重启也是可以的,下次开机永久配置自动生效):

第四章:Docker 安装
4.1 概述
- 其实,lb-master 节点和 lb-slave 节点可以不安装 Docker 的,但是为了方便测试 HA ,所以我们还是在所有节点都安装 Docker 。

4.2 Docker 安装
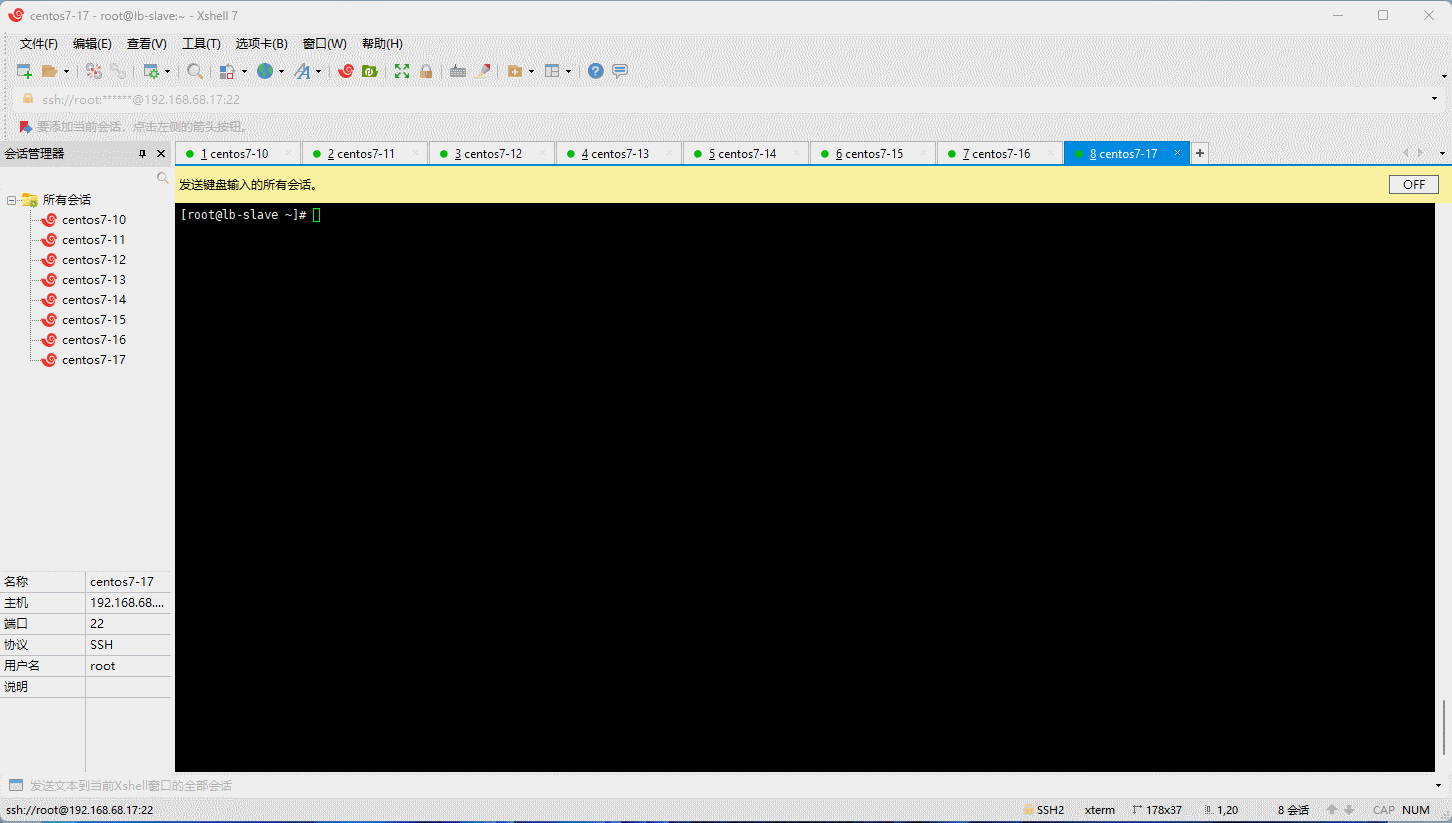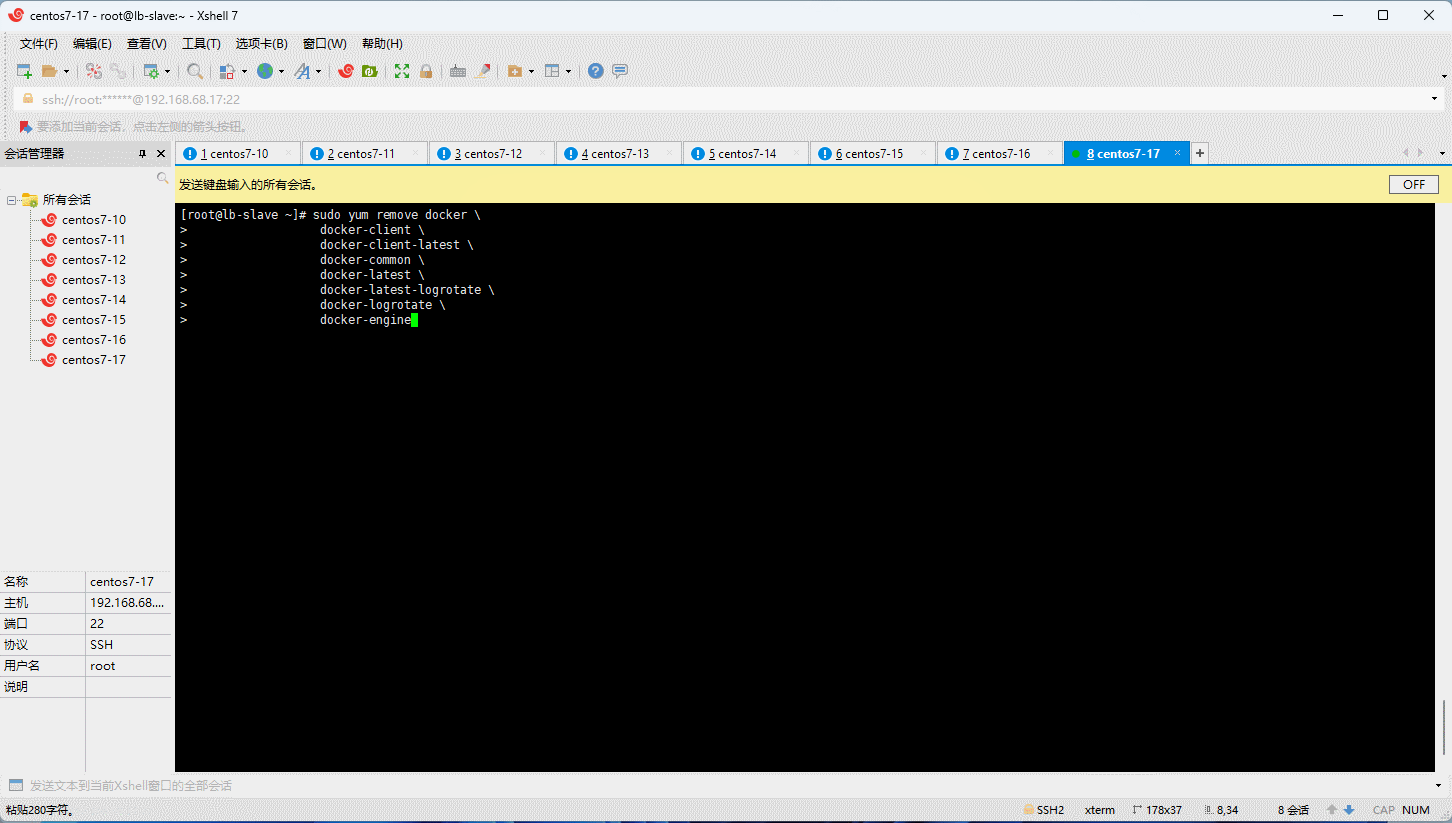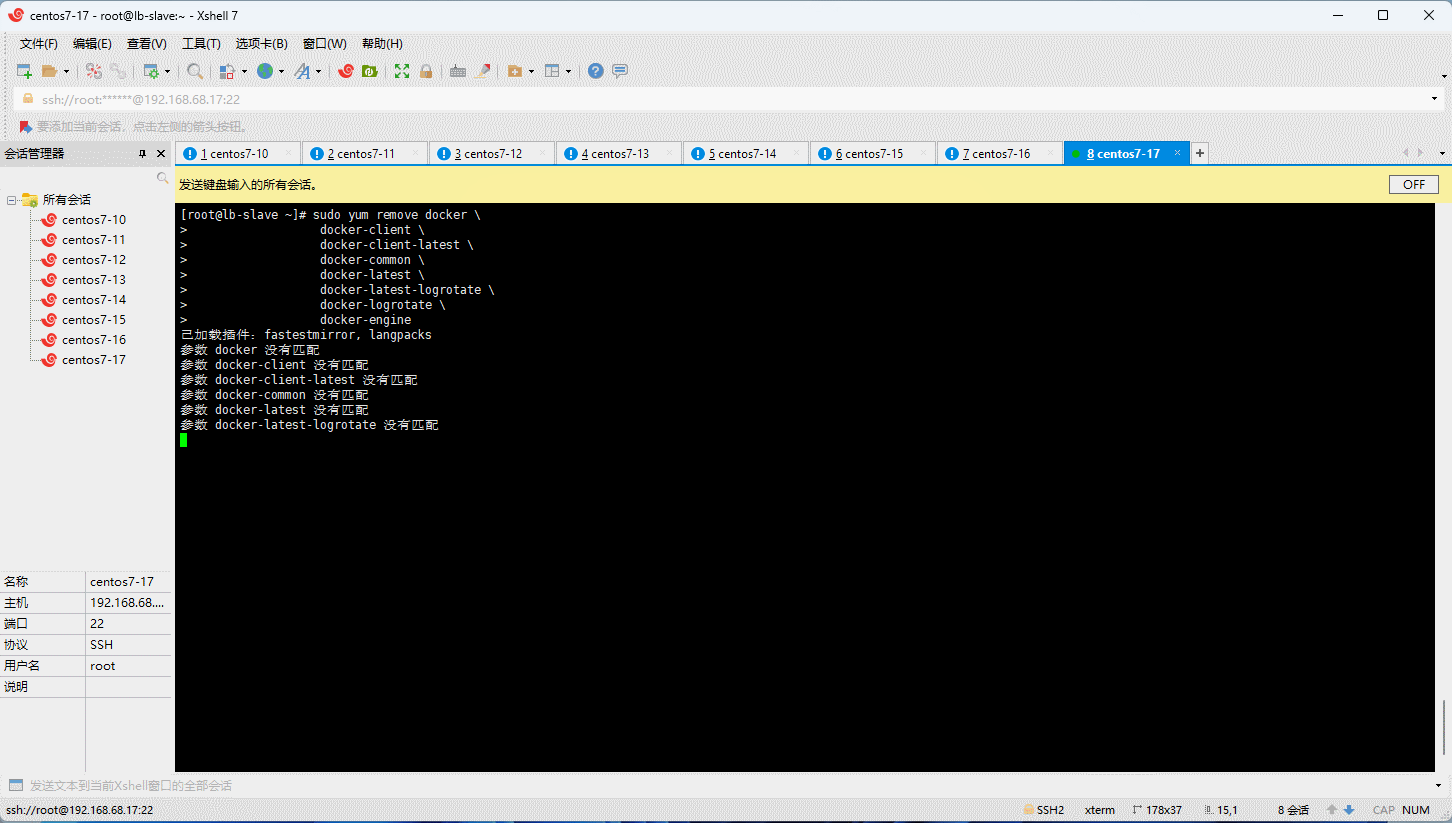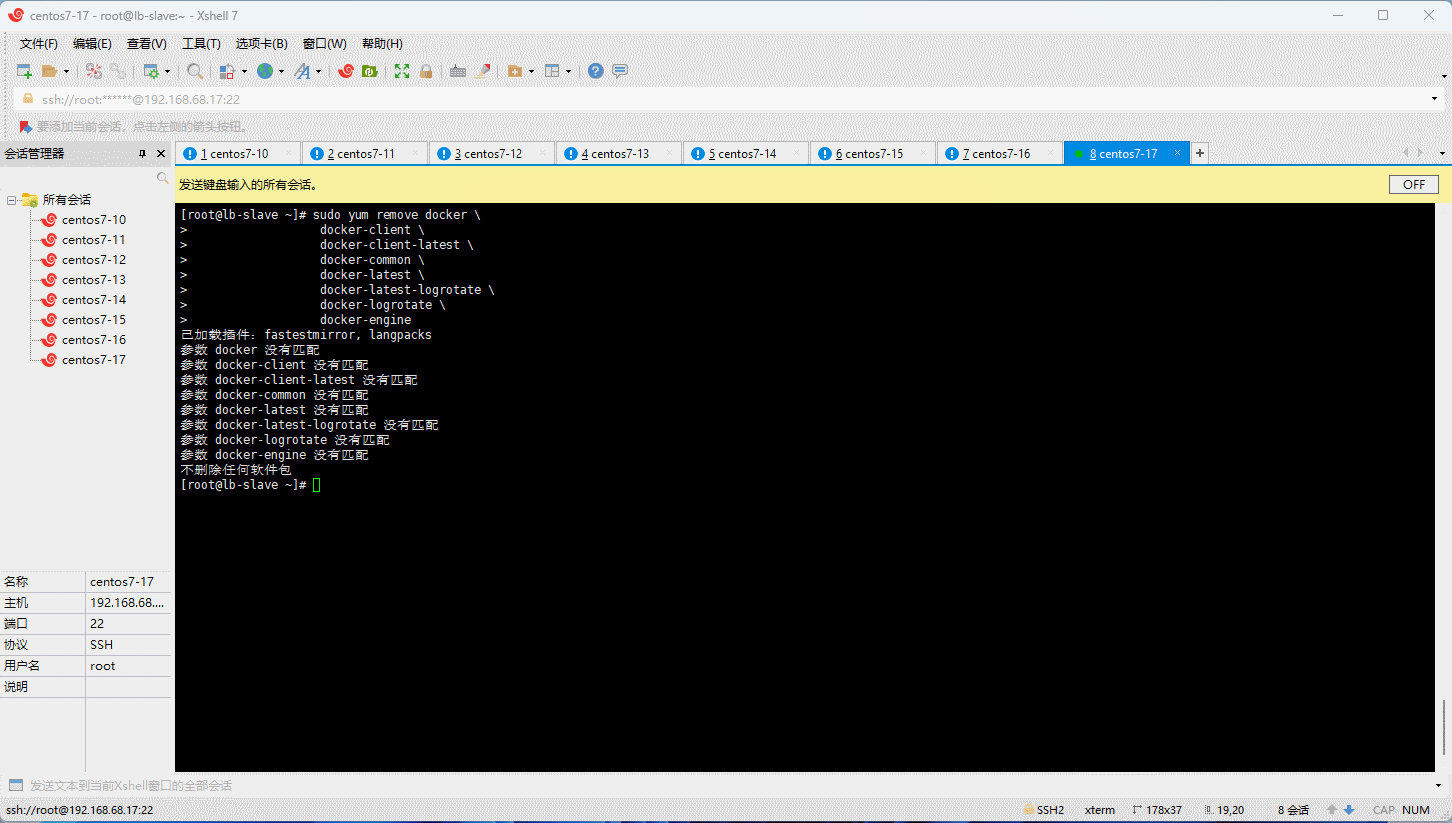
- 卸载旧版本的 Docker :
sudo yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engine

- 安装所需依赖:

- 设置 stable 镜像仓库:

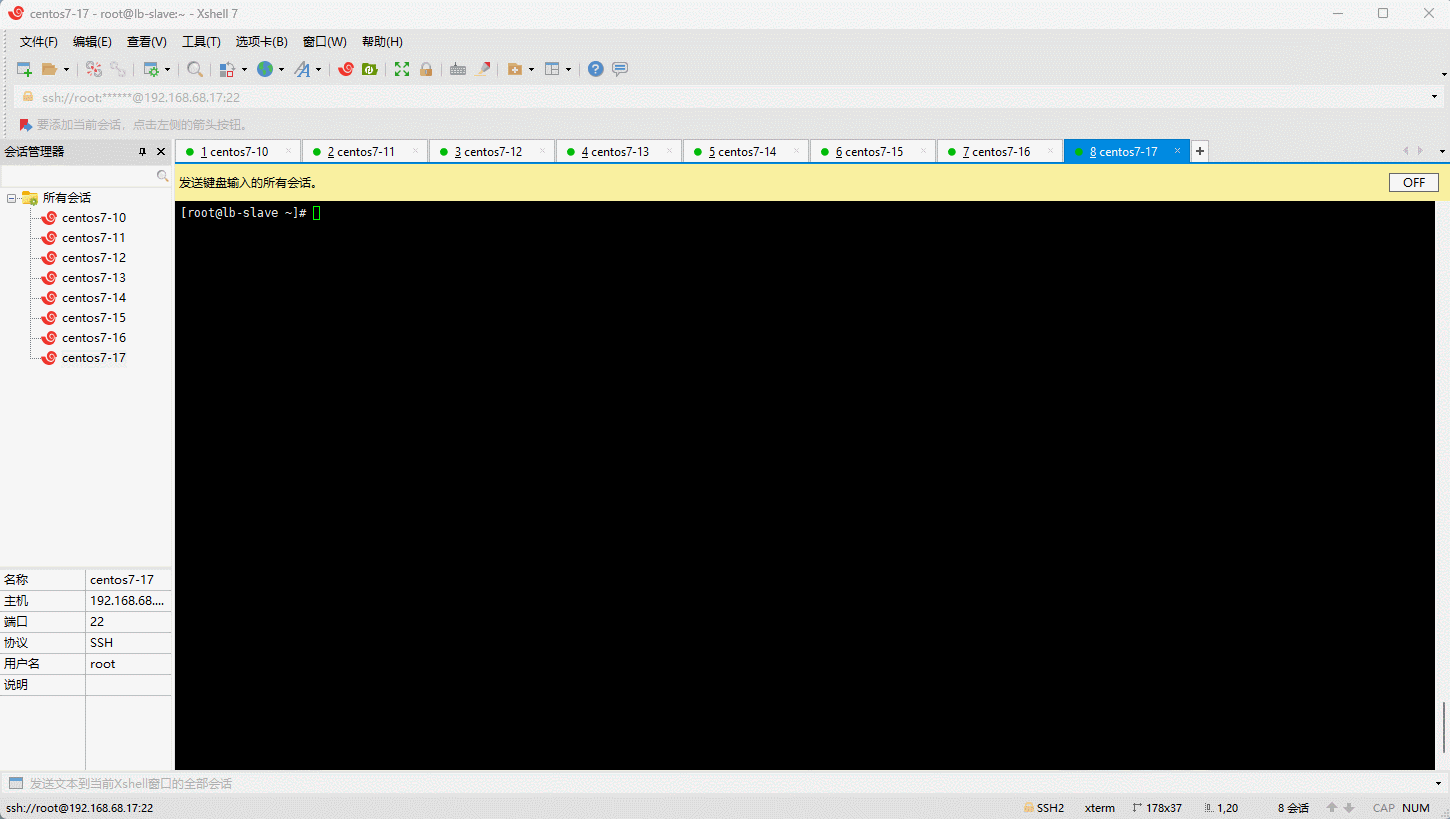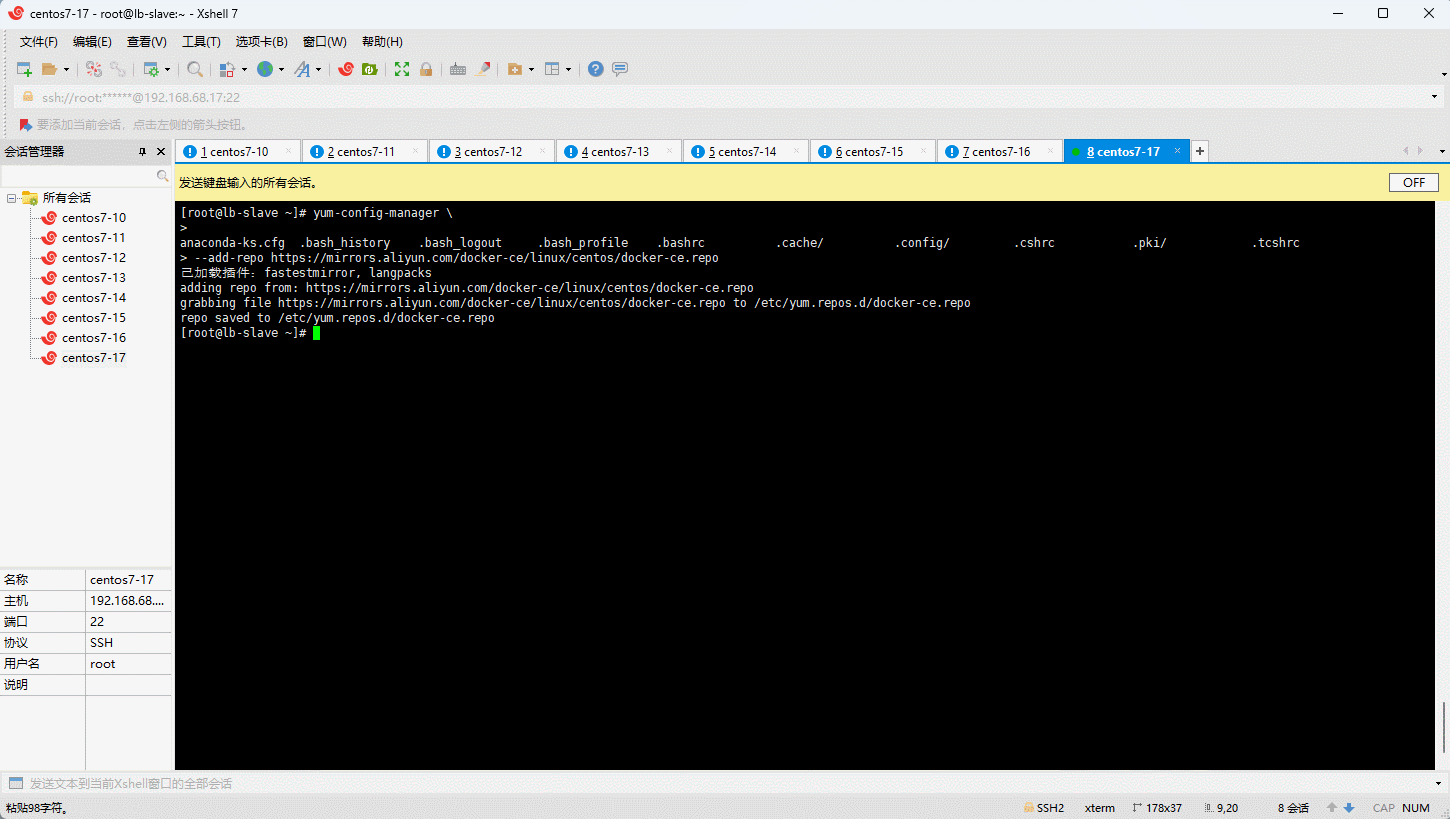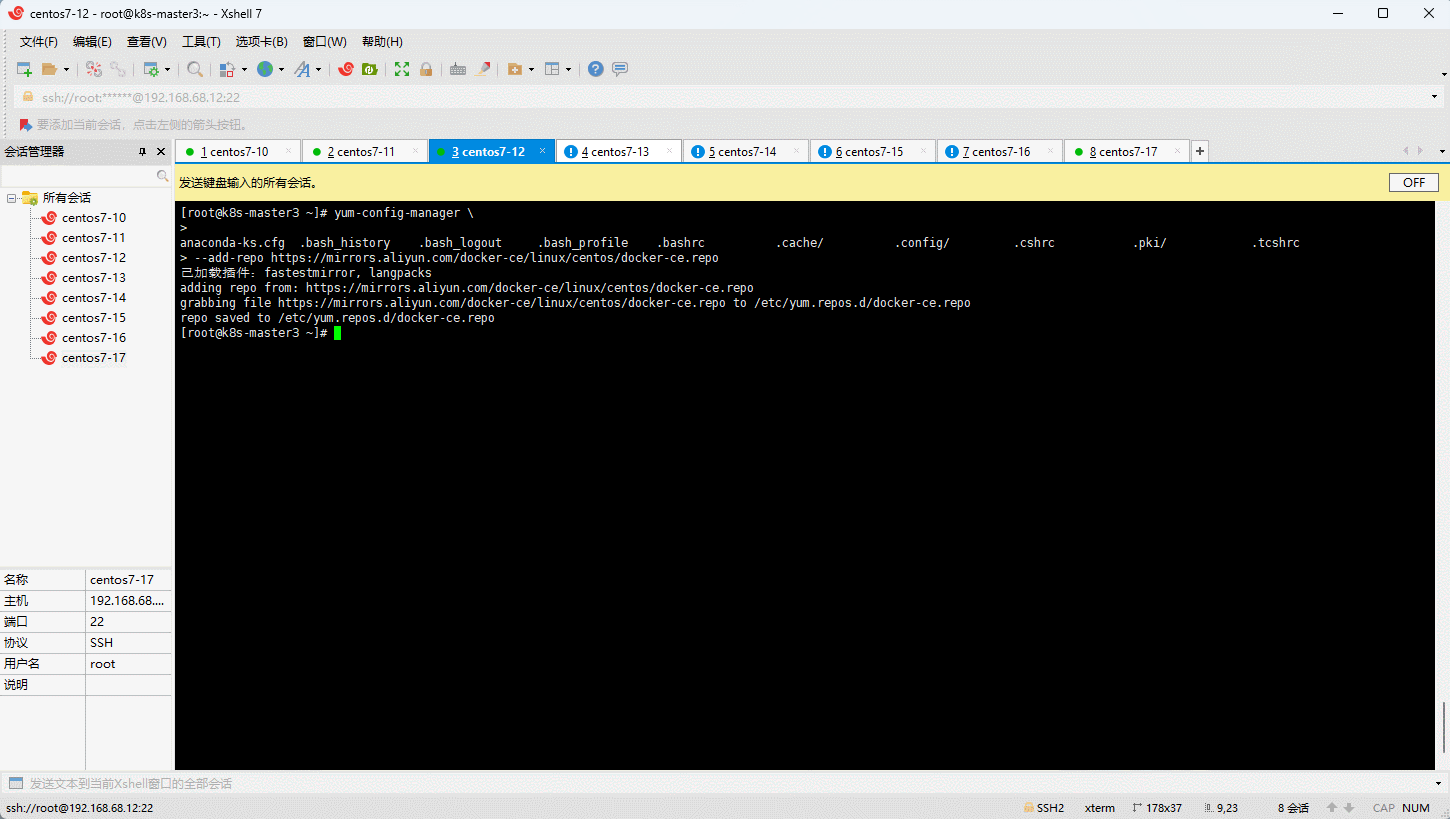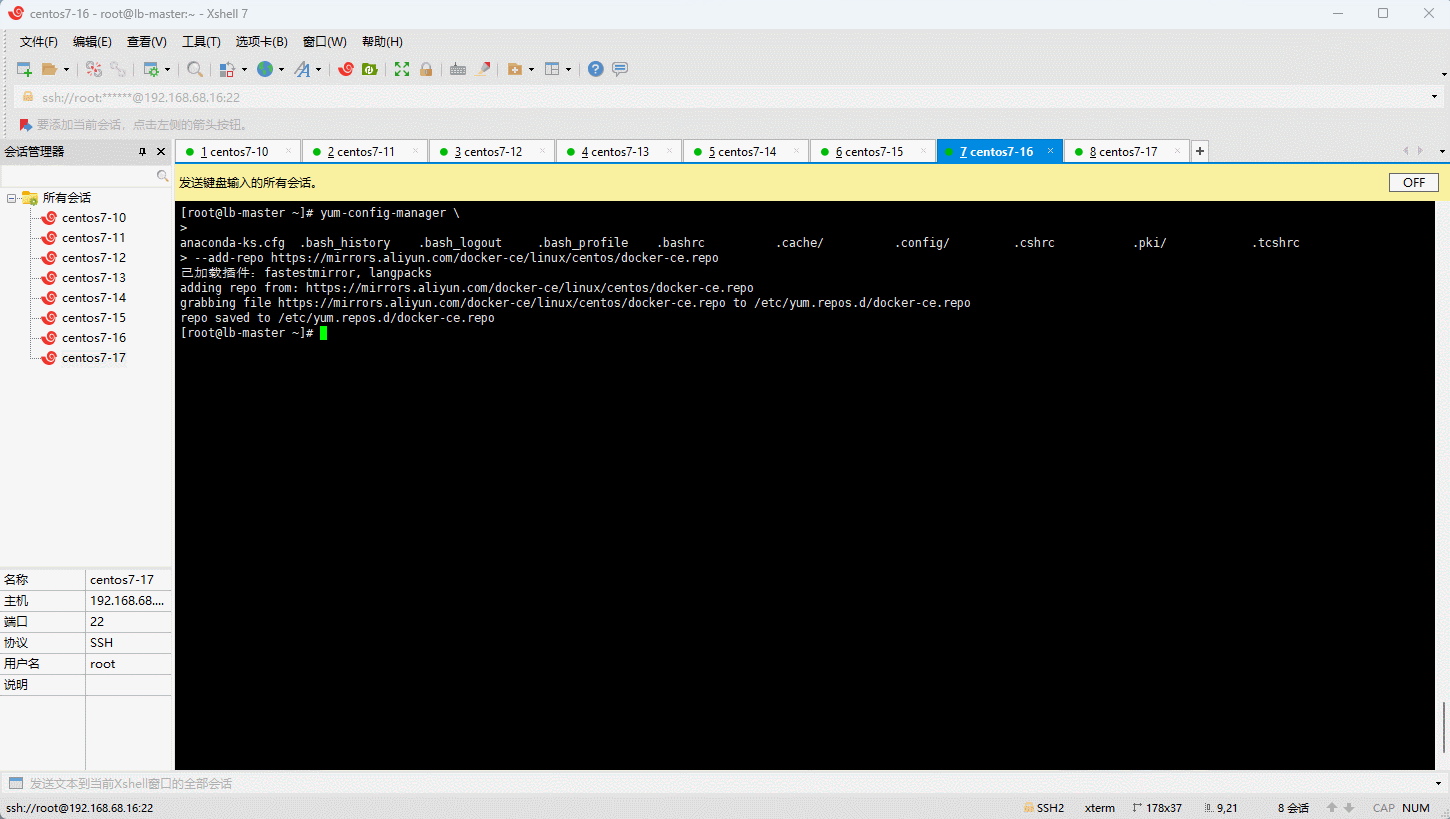
- 更新 yum 软件包索引:

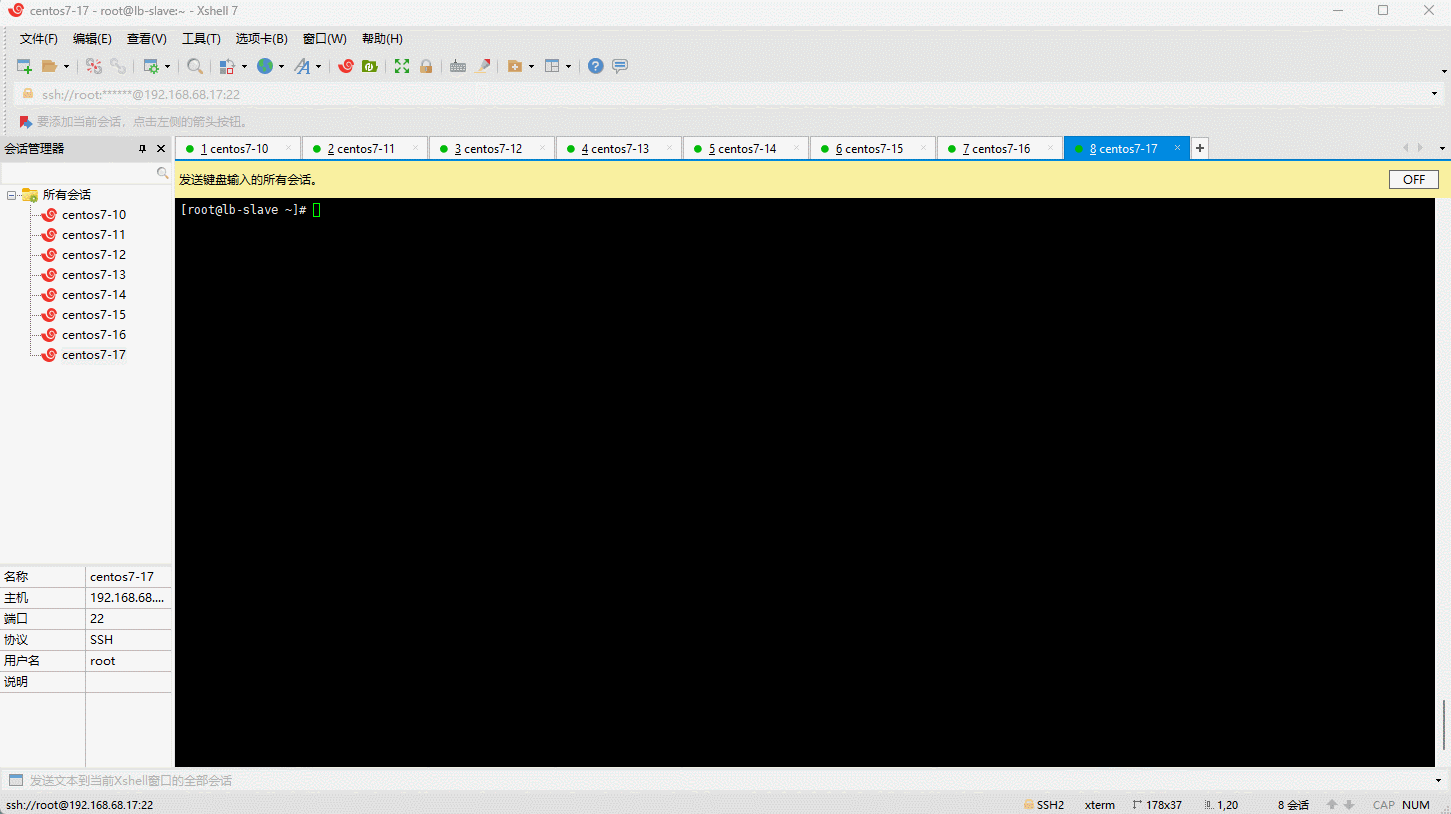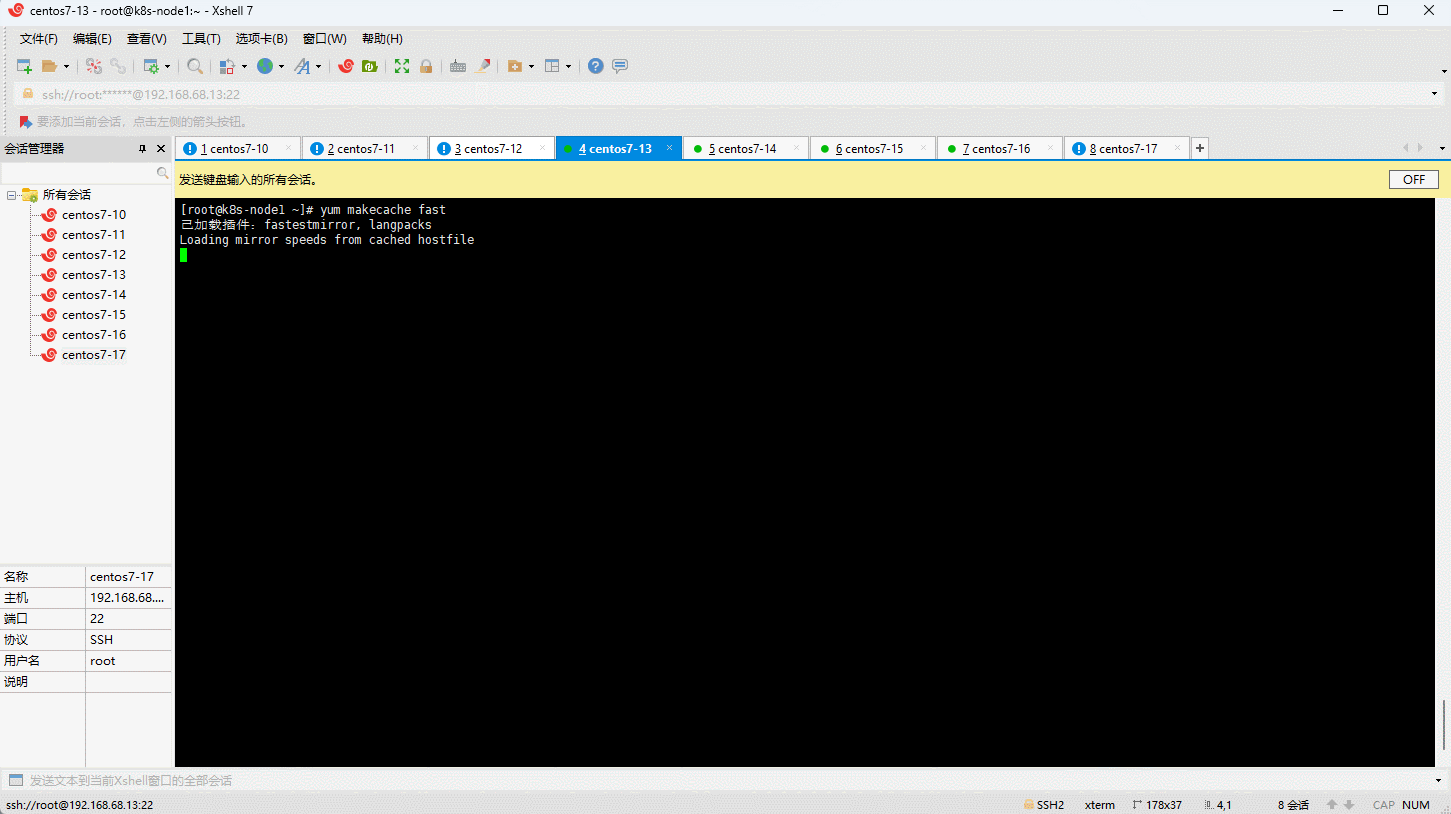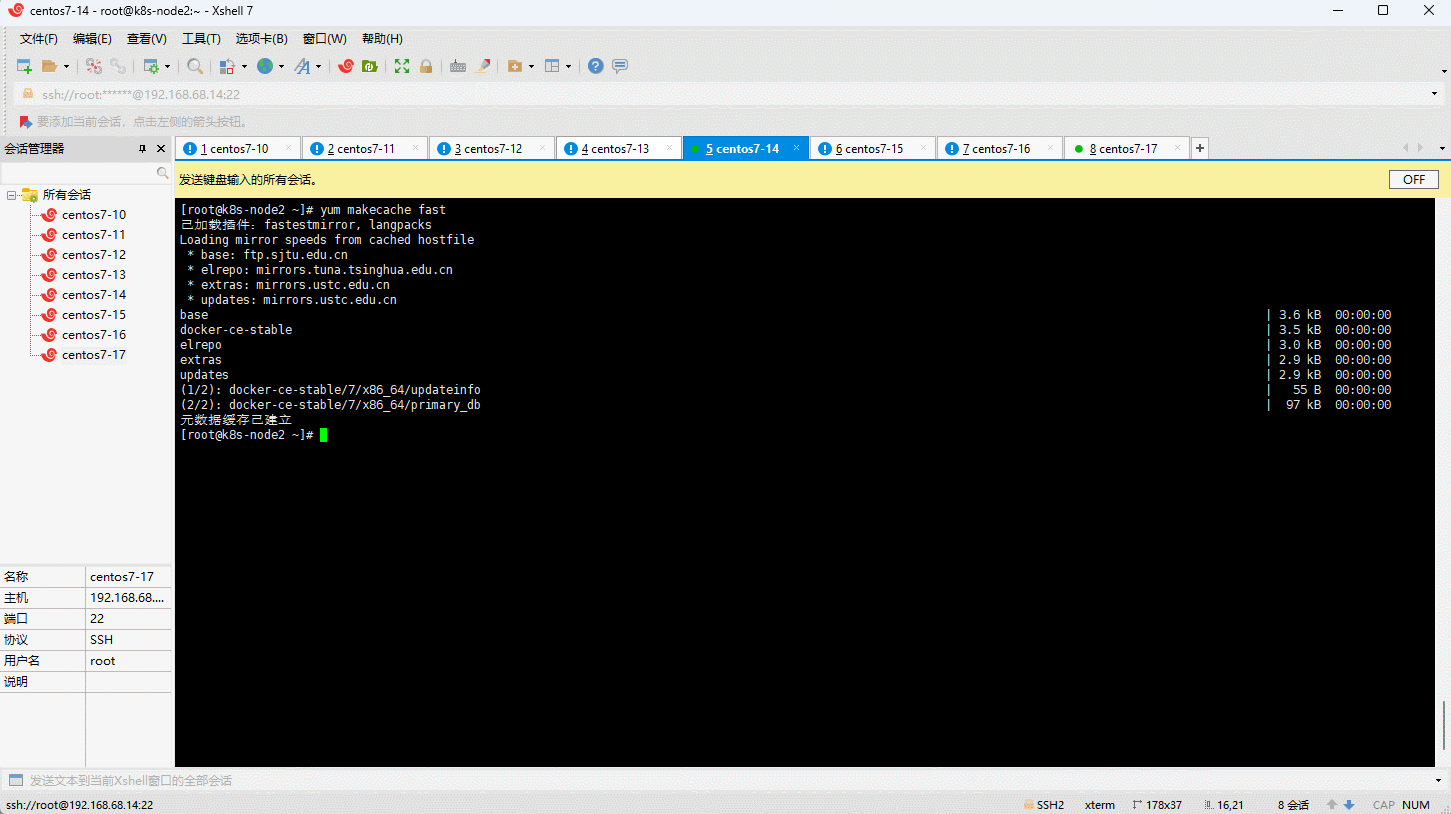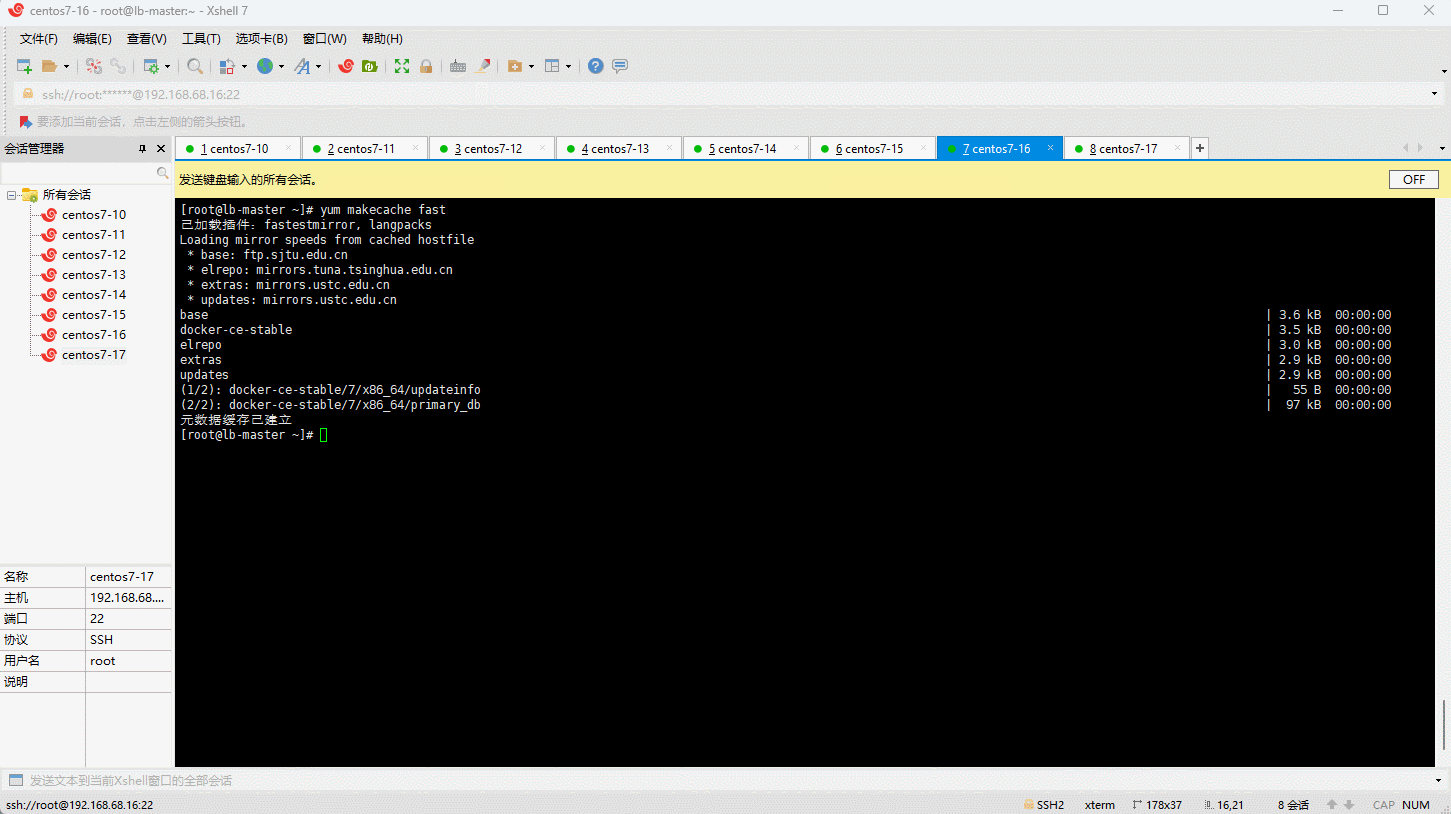
- 安装最新版本的 Docker :

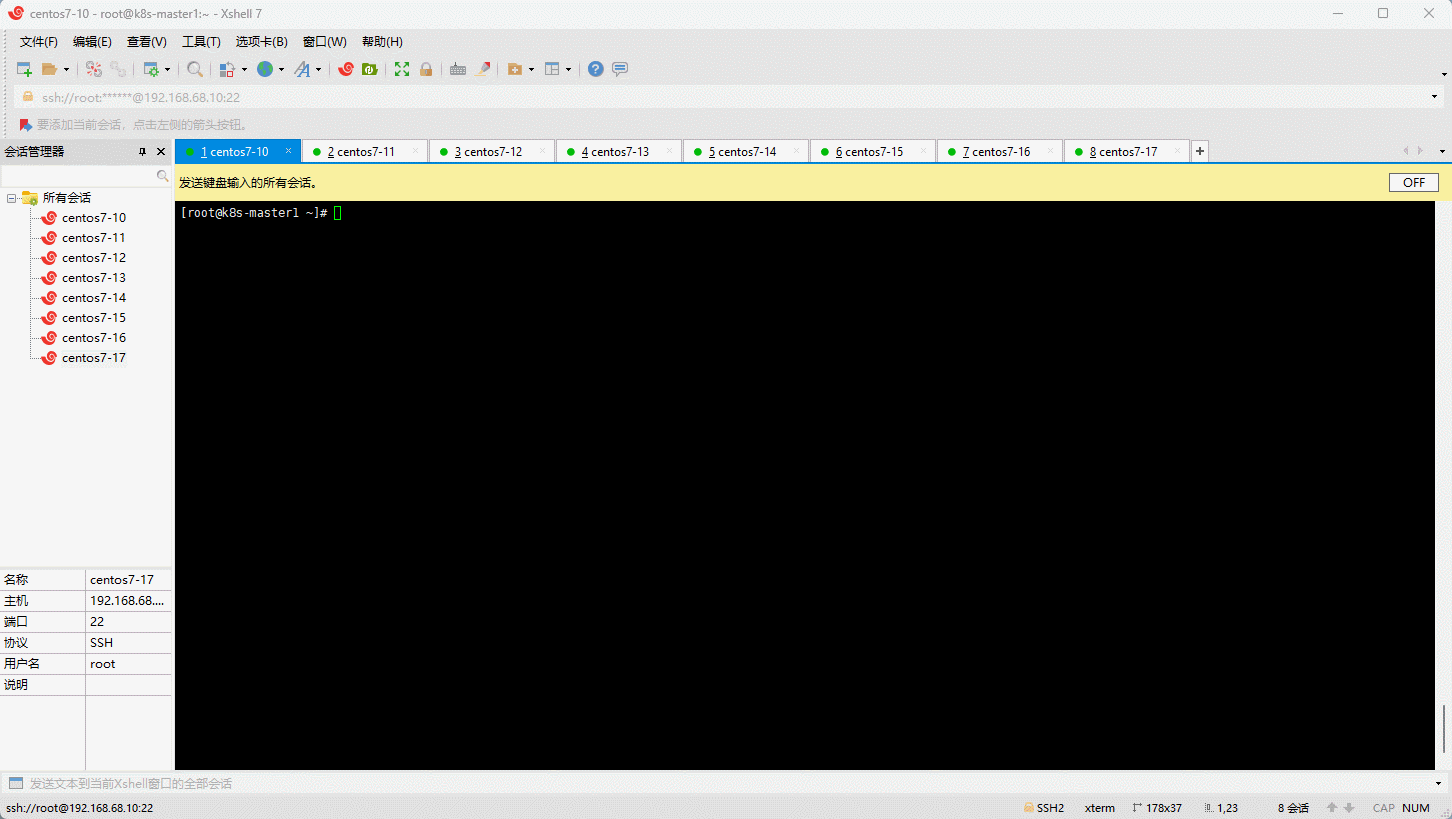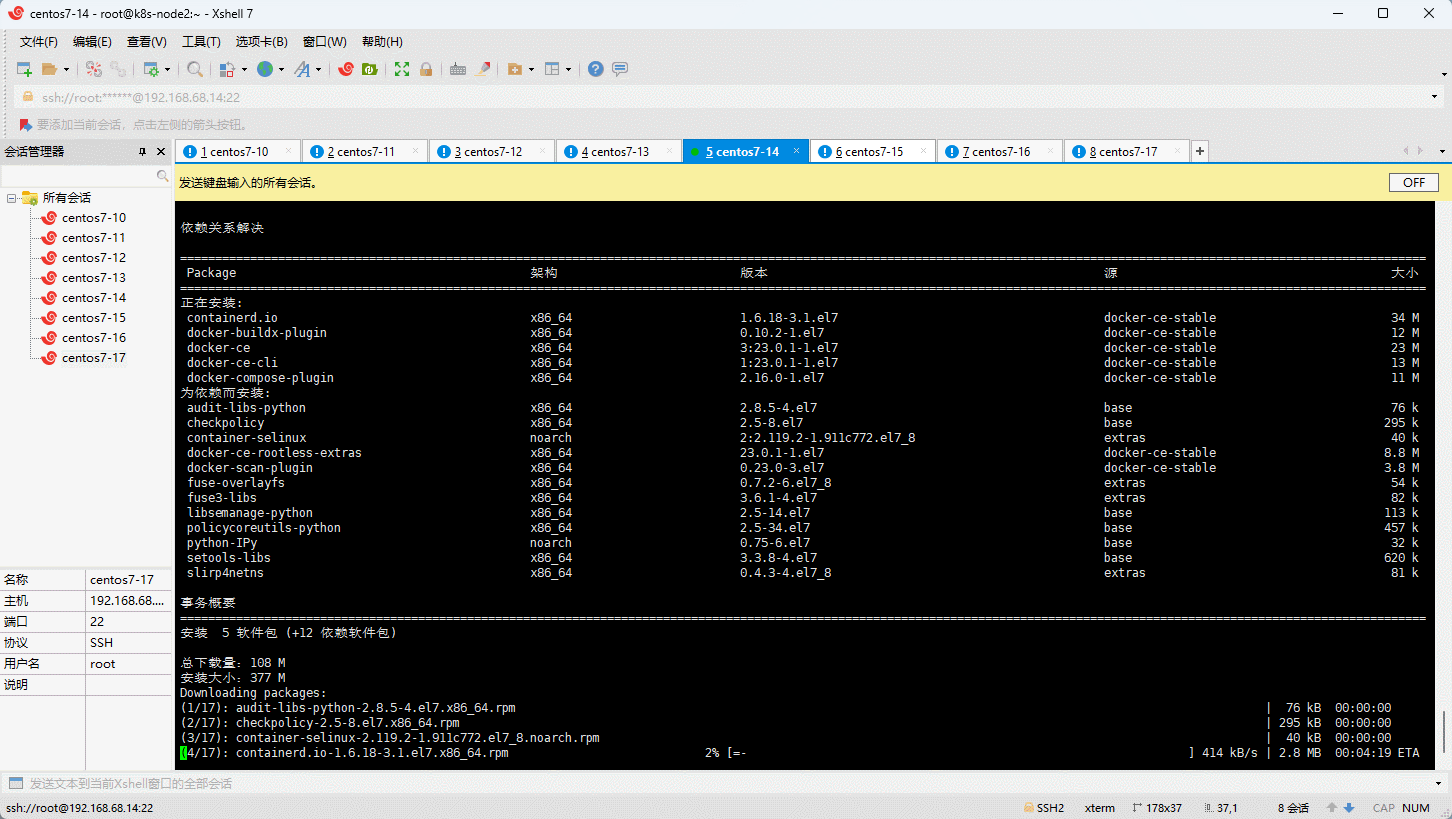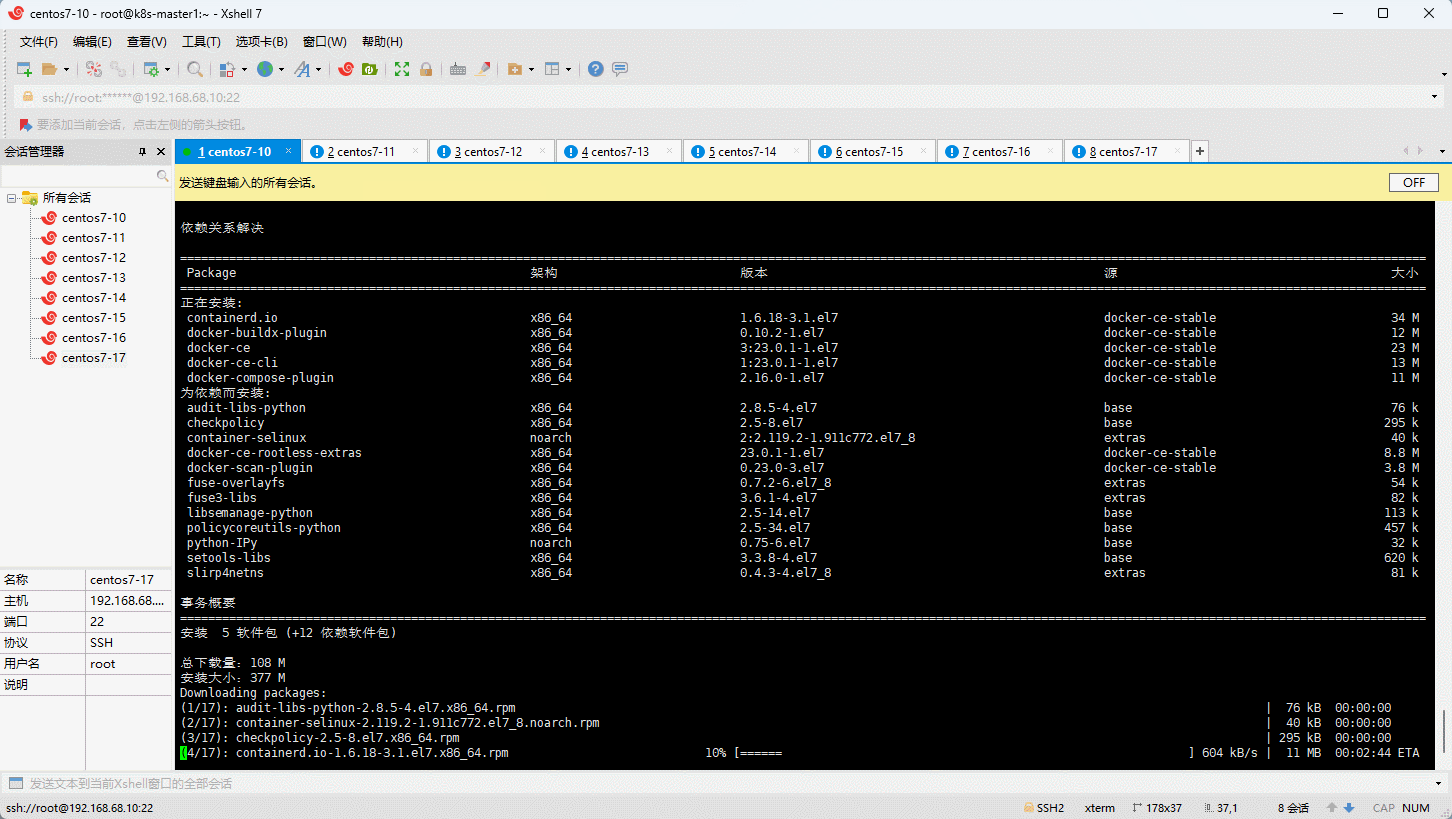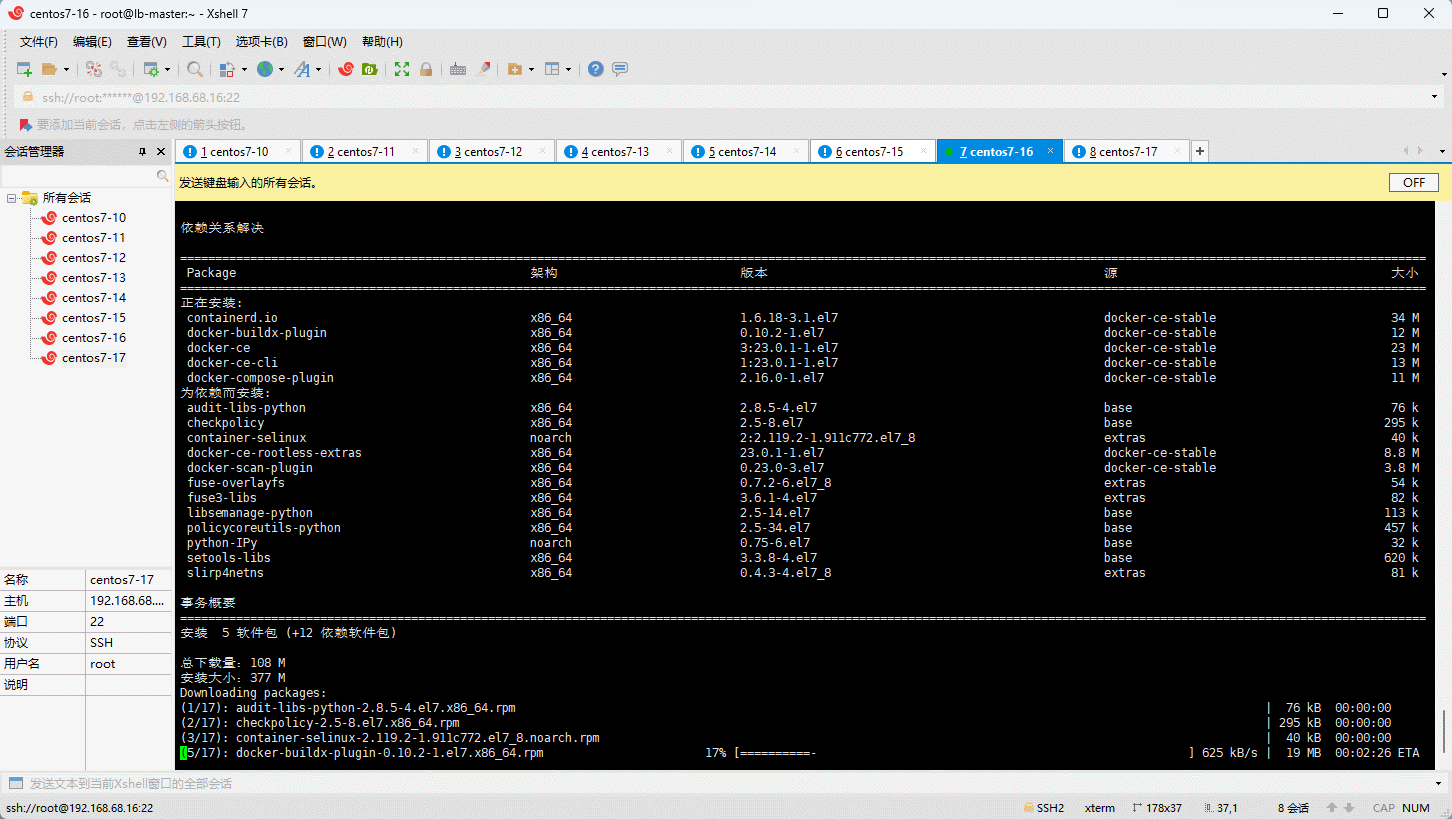
- 启动 Docker :

- 验证 Docker 是否安装成功:

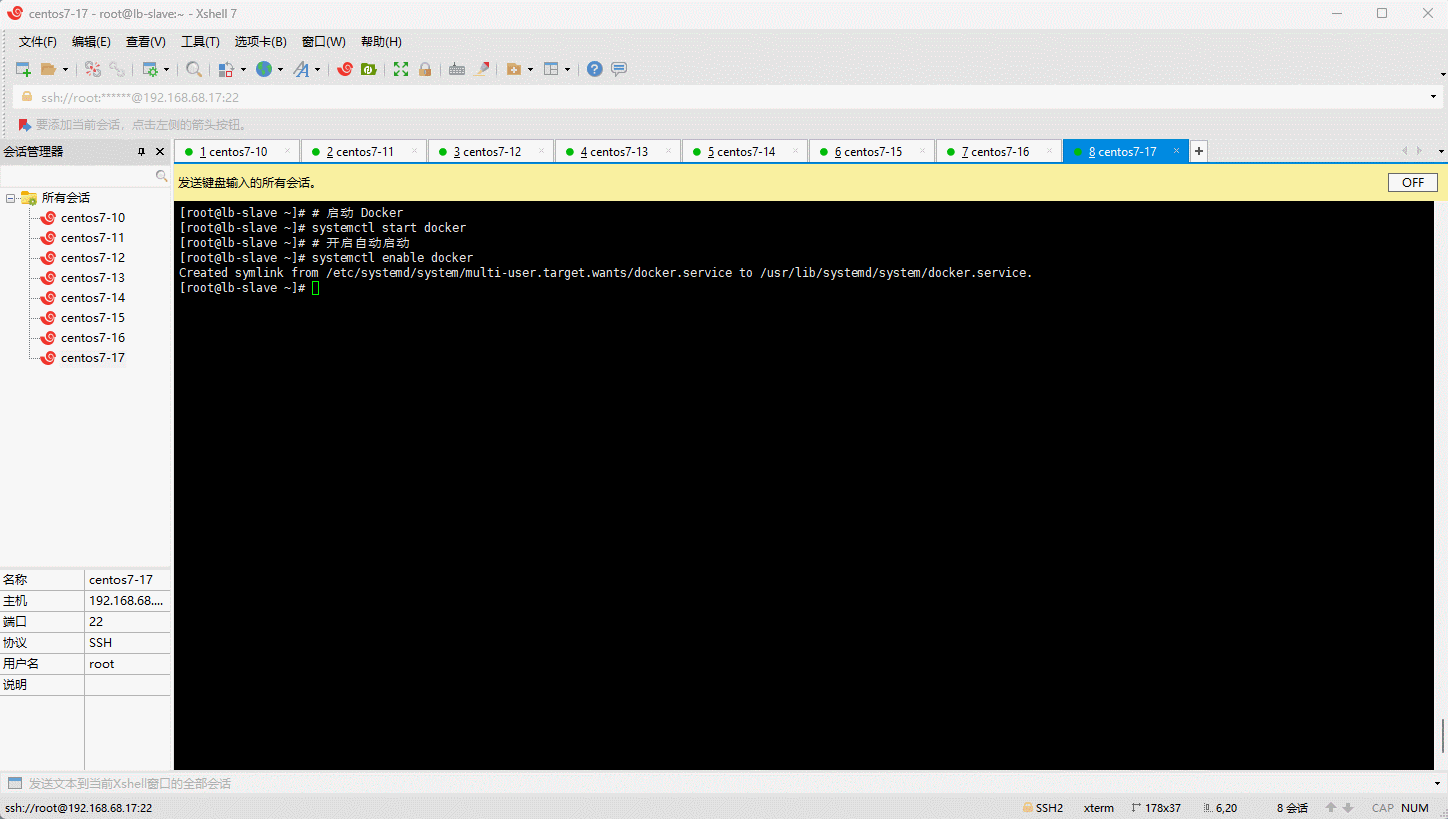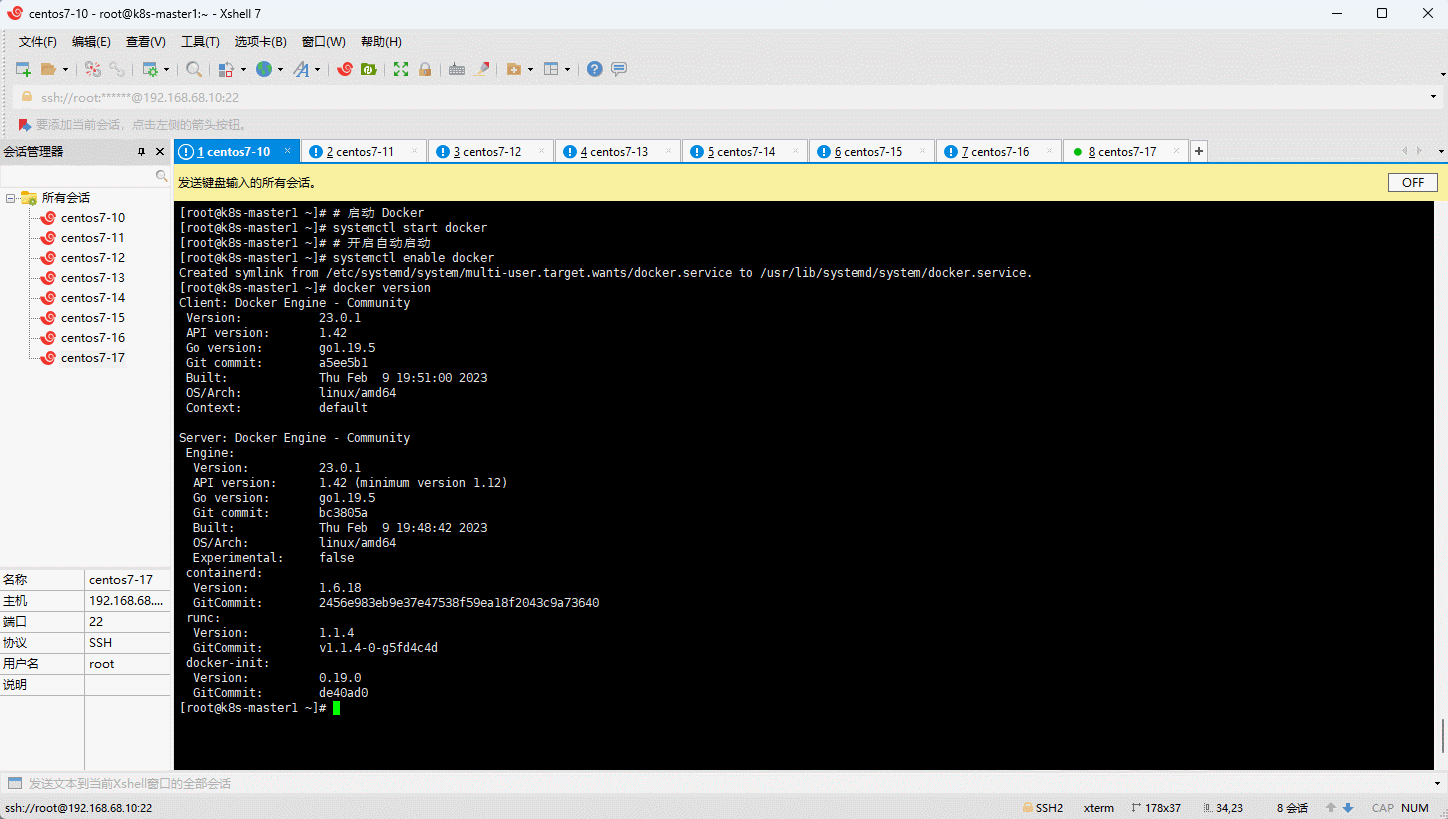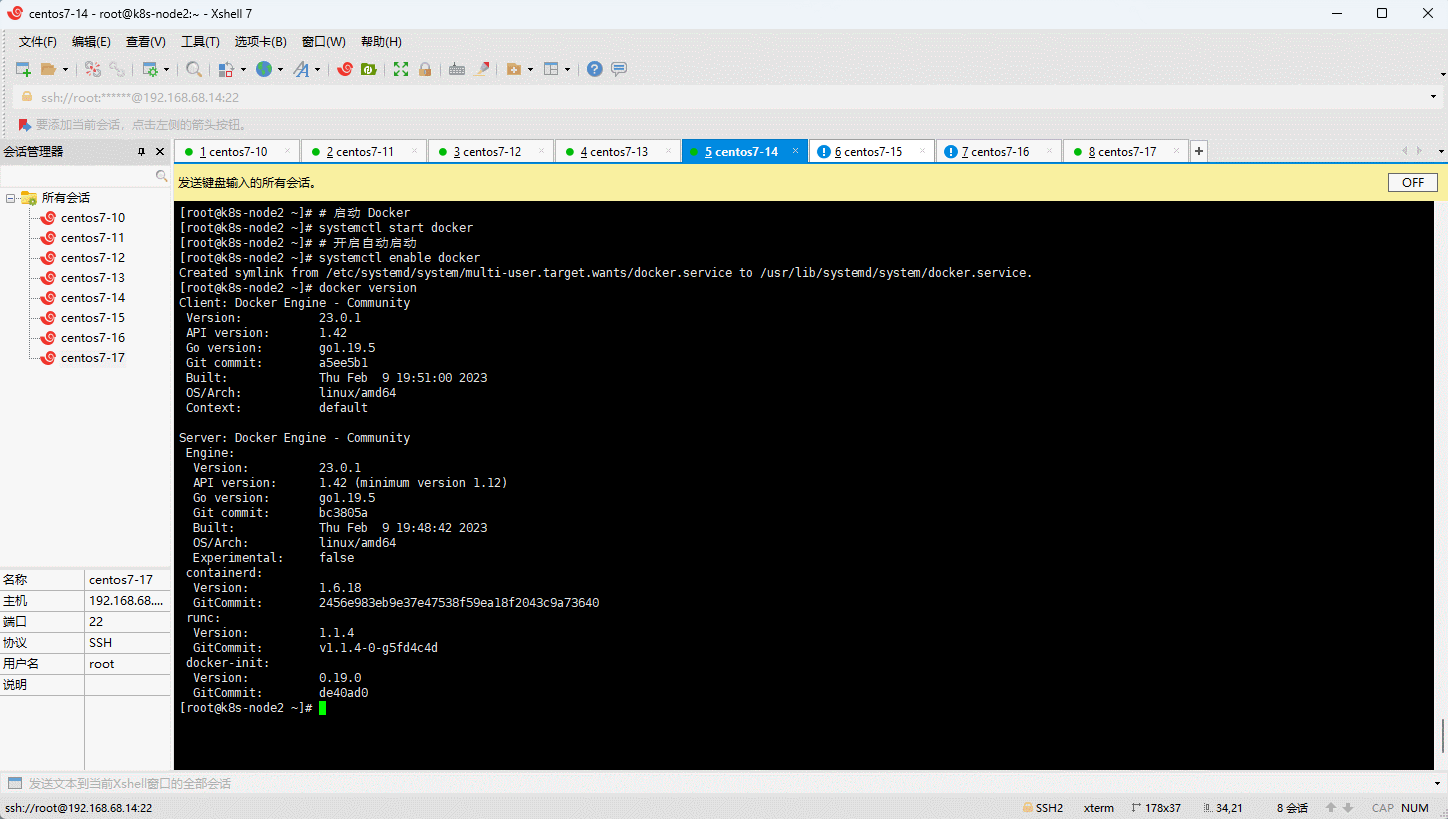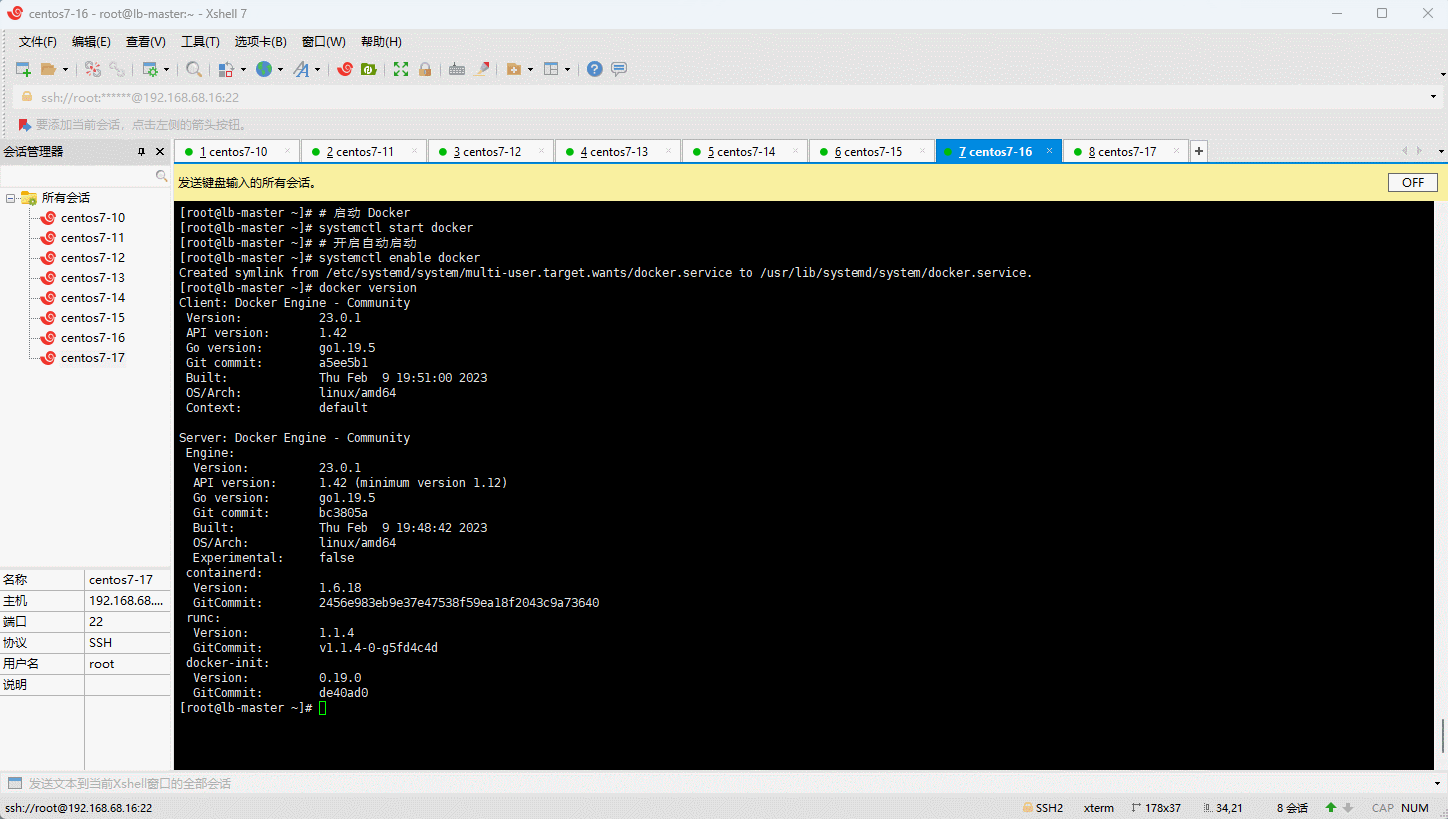
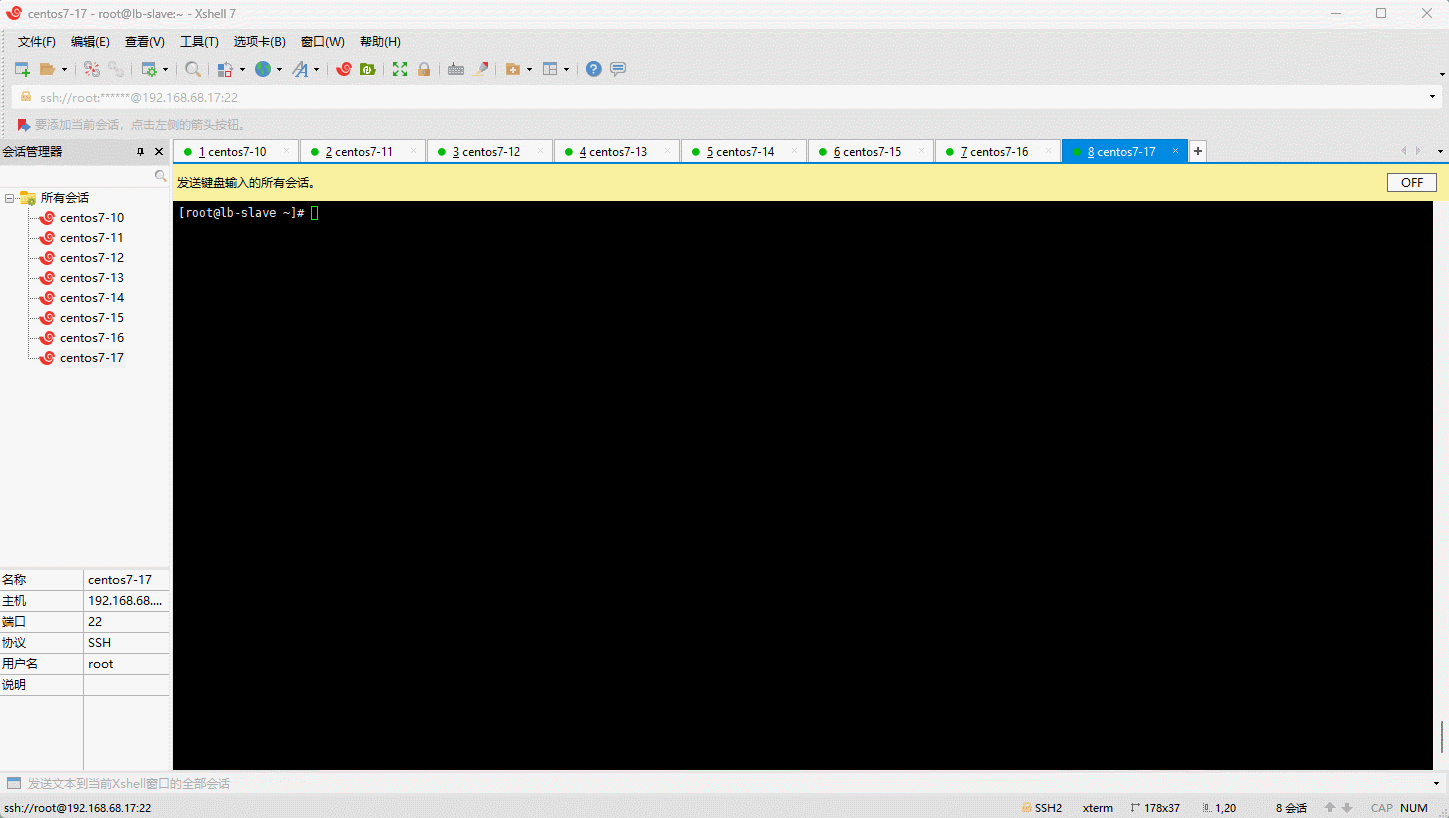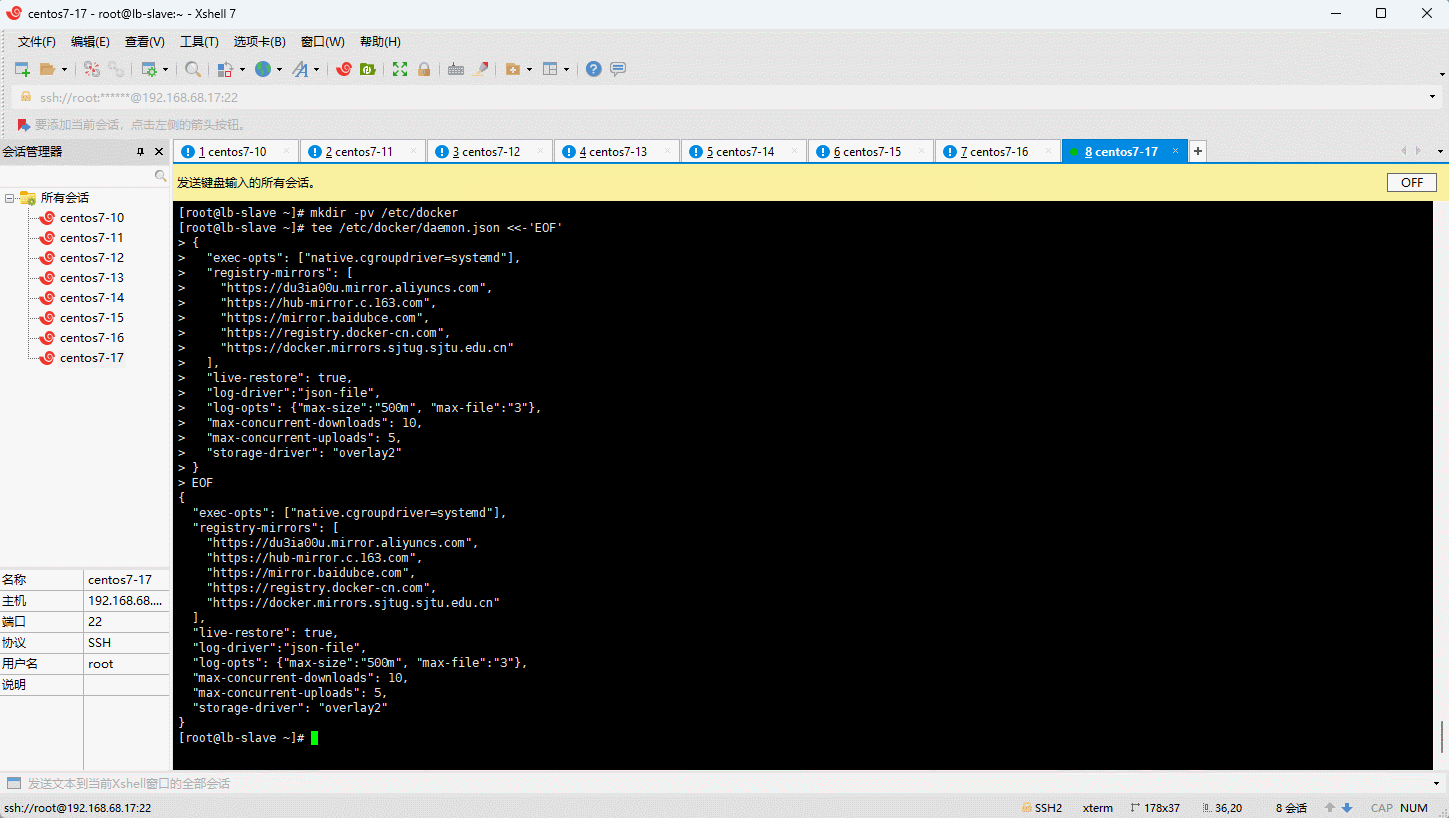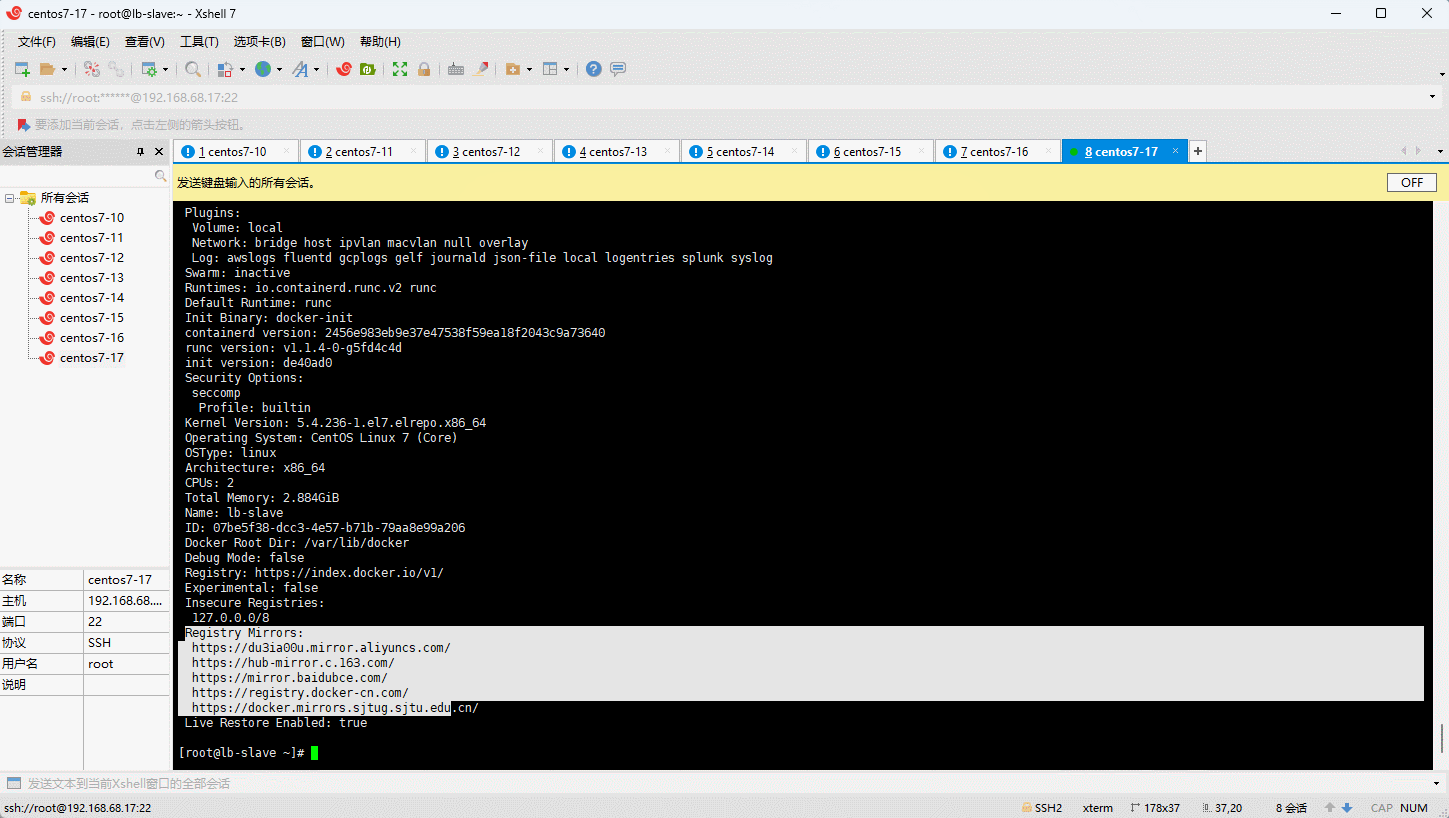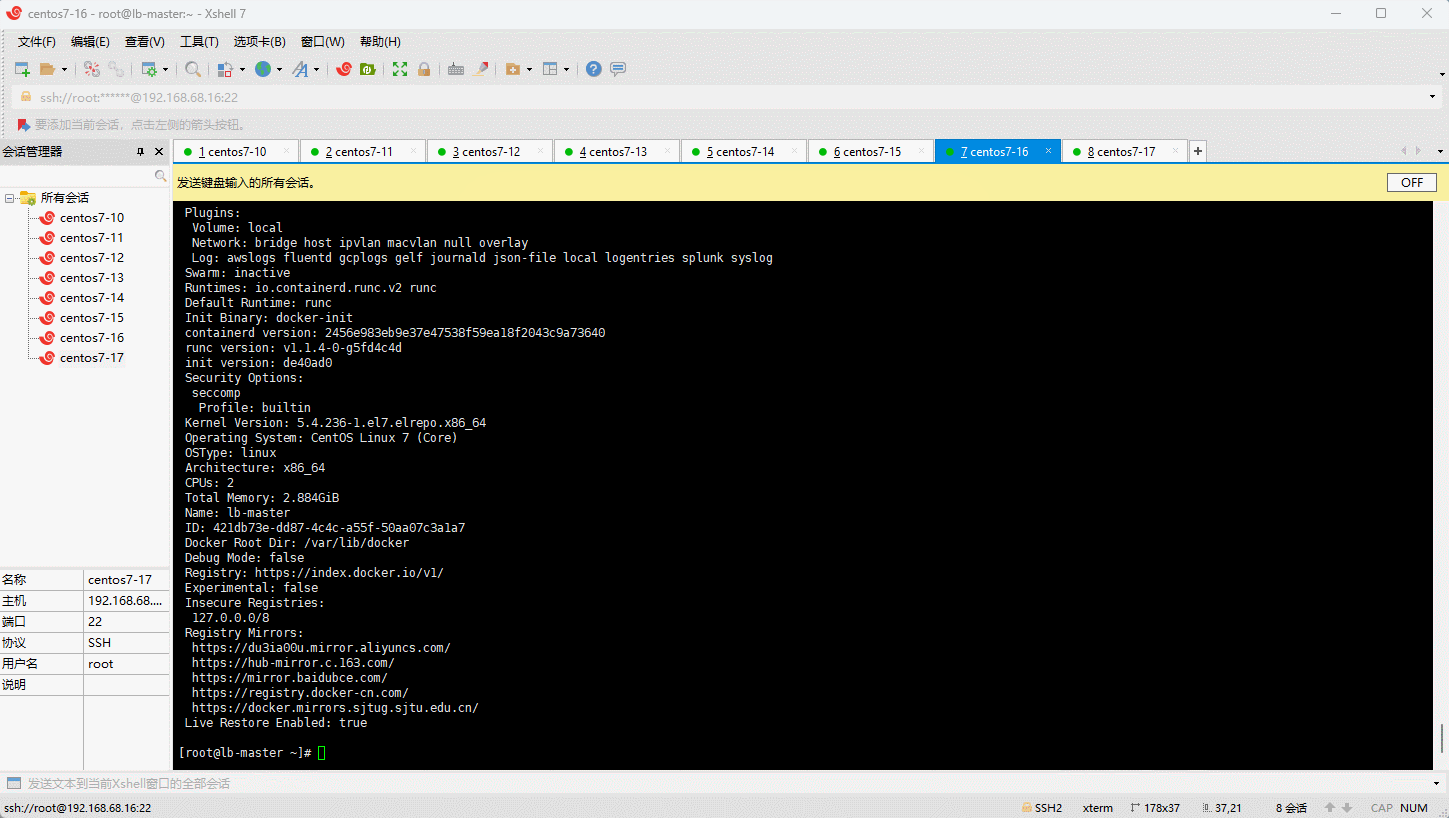
- 阿里云镜像加速:
tee /etc/docker/daemon.json <<-'EOF'
{
"exec-opts": ["native.cgroupdriver=systemd"],
"registry-mirrors": [
"https://du3ia00u.mirror.aliyuncs.com",
"https://docker.lixd.xyz"
],
"live-restore": true,
"log-driver":"json-file",
"log-opts": {"max-size":"500m", "max-file":"3"},
"max-concurrent-downloads": 10,
"max-concurrent-uploads": 5,
"storage-driver": "overlay2"
}
EOF

第五章:配置 VIP(可选)
5.1 概述
- 之所以要配置 VIP,是为了实现 Kubernetes 集群高可用,其实就是为了让 master 实现高可用;当然,在公有云(如:阿里云等)上就需要购买云厂商提供的负载均衡器。

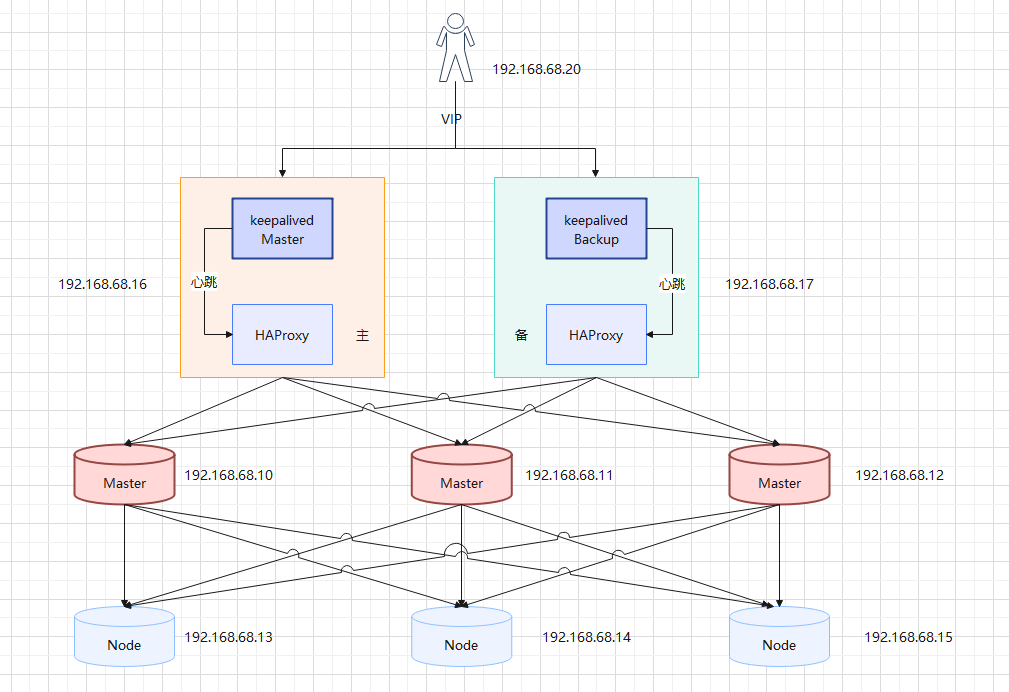
说明:haproxy 相当于 nginx ,是个负载均衡器,而 keepalive 是用来实现 VIP。
5.2 基于 yum 配置 VIP
5.2.1 安装和配置 Haproxy
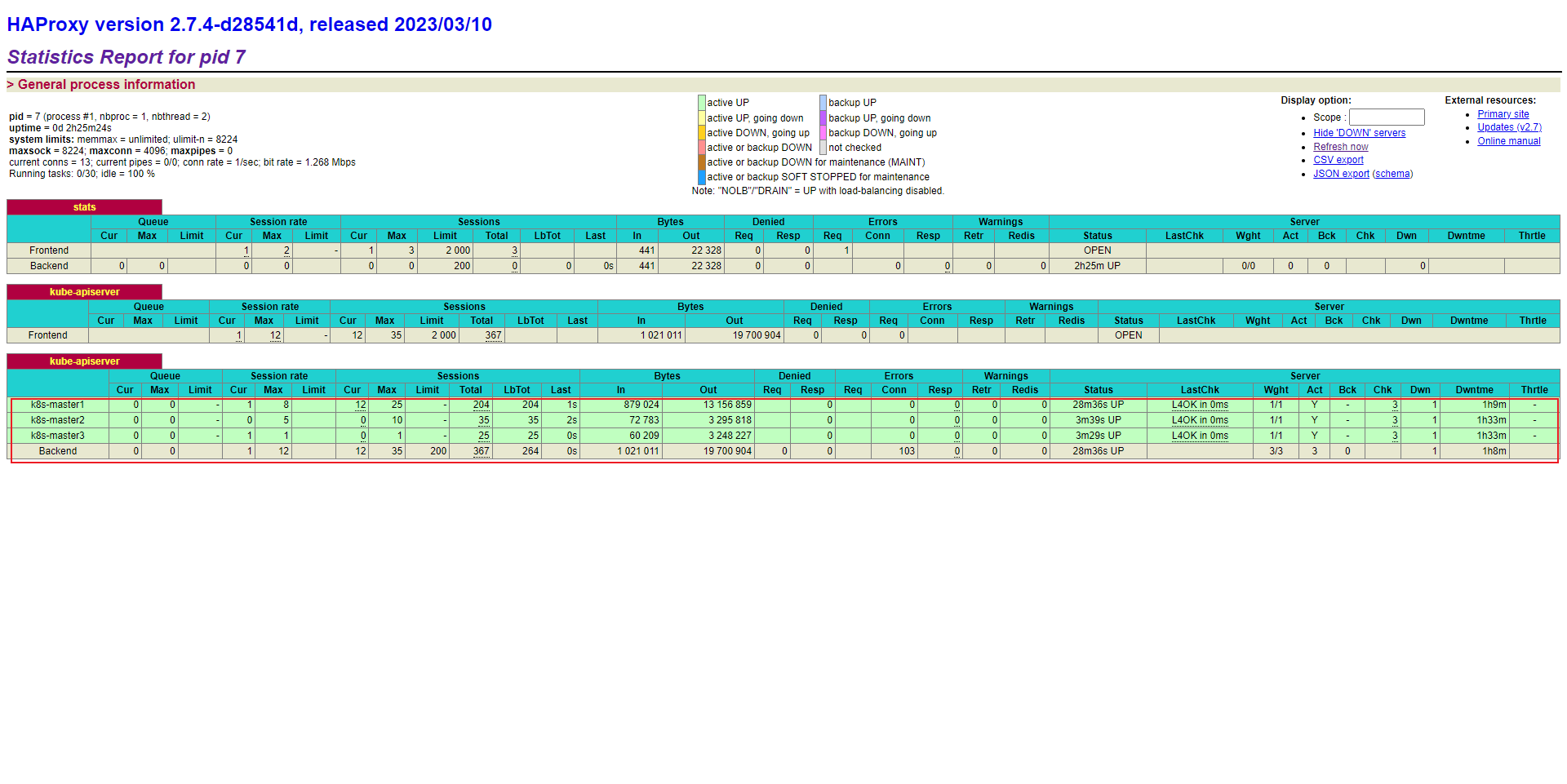
- 我们利用 Haproxy 来实现 Kubernetes 的 api-server 的负载均衡 :
# lb-master(192.168.68.16) 和 lb-slave (192.168.68.17)修改配置文件
cat > /etc/haproxy/haproxy.cfg <<EOF
global
log 127.0.0.1 local0 info
maxconn 4096
daemon
defaults
log global
mode tcp
option tcplog
option dontlognull
retries 3
maxconn 2000
timeout connect 5s
timeout client 120s
timeout server 120s
listen stats
mode http
bind 0.0.0.0:8888 # 这边可以修改
stats enable
log global
stats uri /status
stats auth admin:123456
frontend kube-apiserver
mode tcp
bind *:6443
option tcplog
default_backend kube-apiserver
backend kube-apiserver
mode tcp
balance roundrobin
# 下面是反向代理的 k8s-master 的 api-server 的 ip 和端口,可以修改
server k8s-master1 192.168.68.10:6443 check inter 3s fall 3 rise 3
server k8s-master2 192.168.68.11:6443 check inter 3s fall 3 rise 3
server k8s-master3 192.168.68.12:6443 check inter 3s fall 3 rise 3
EOF

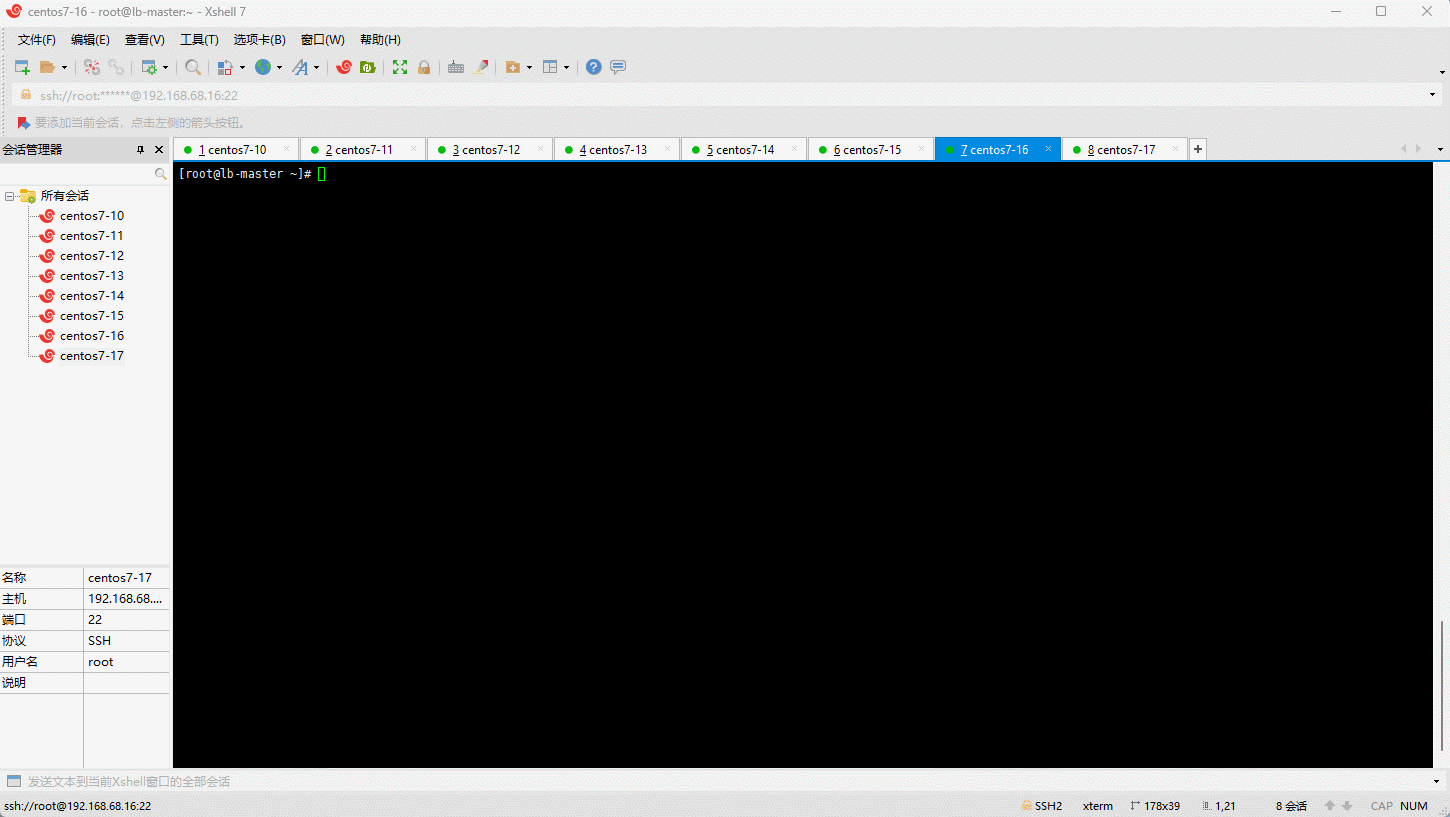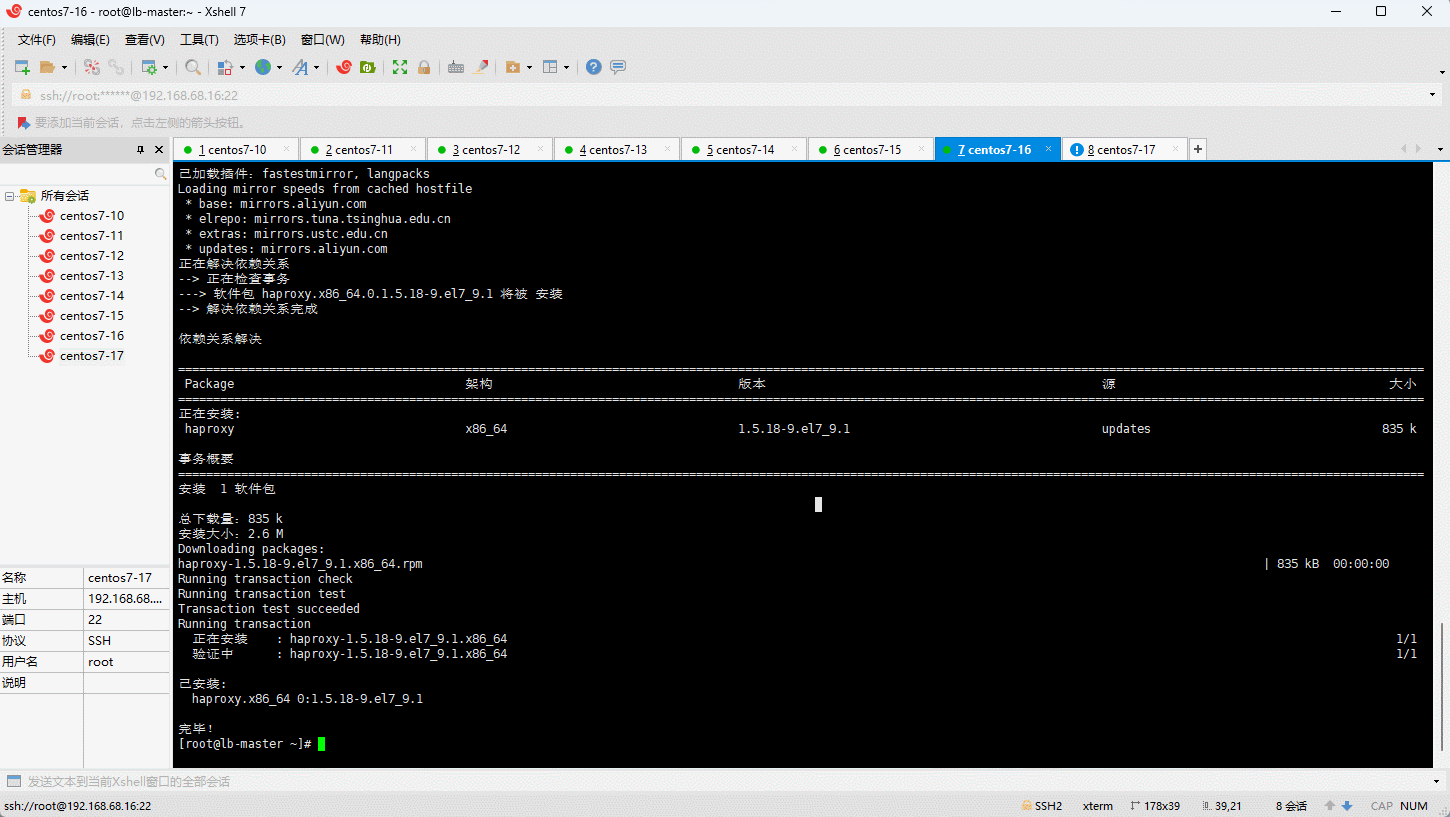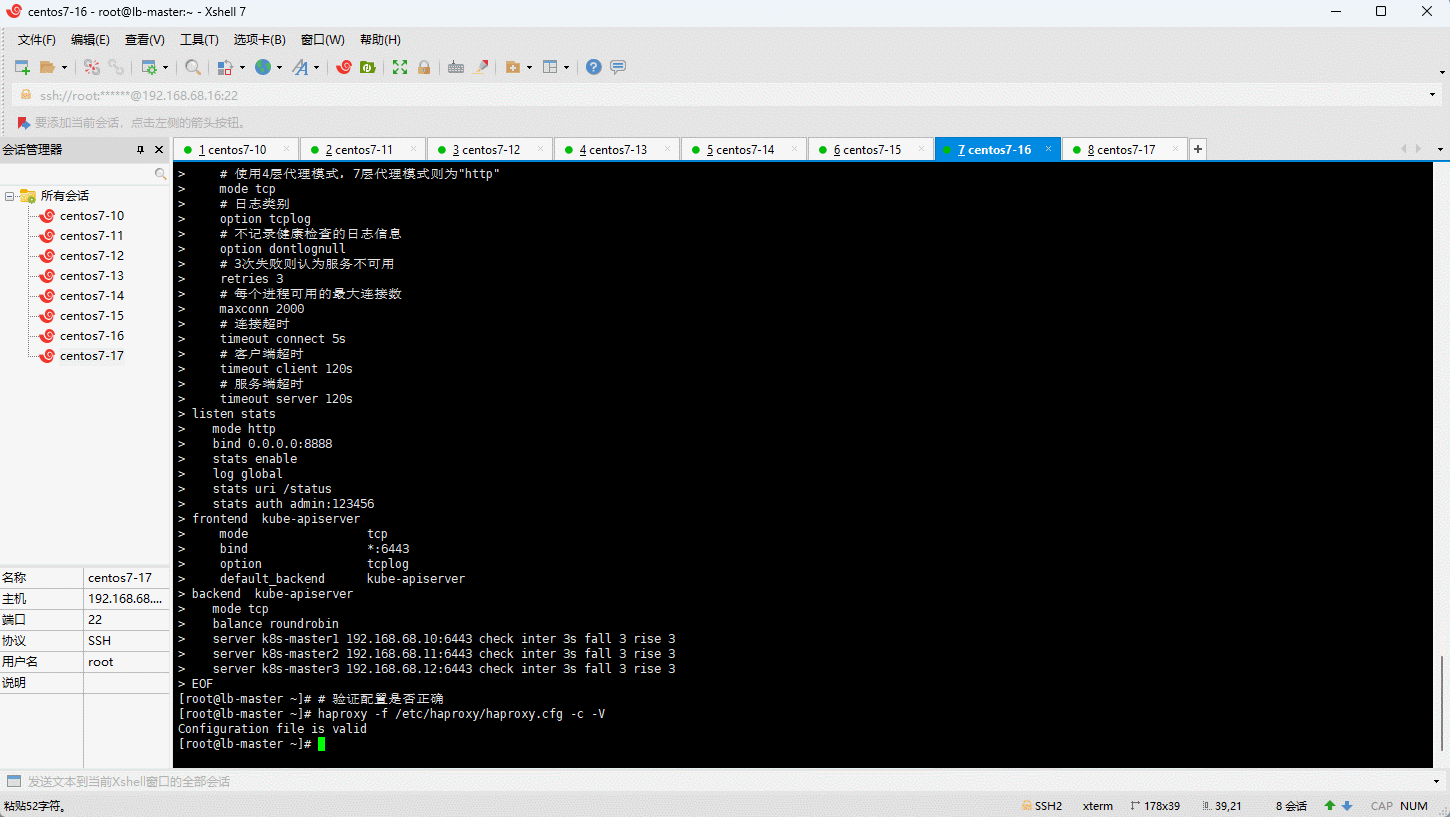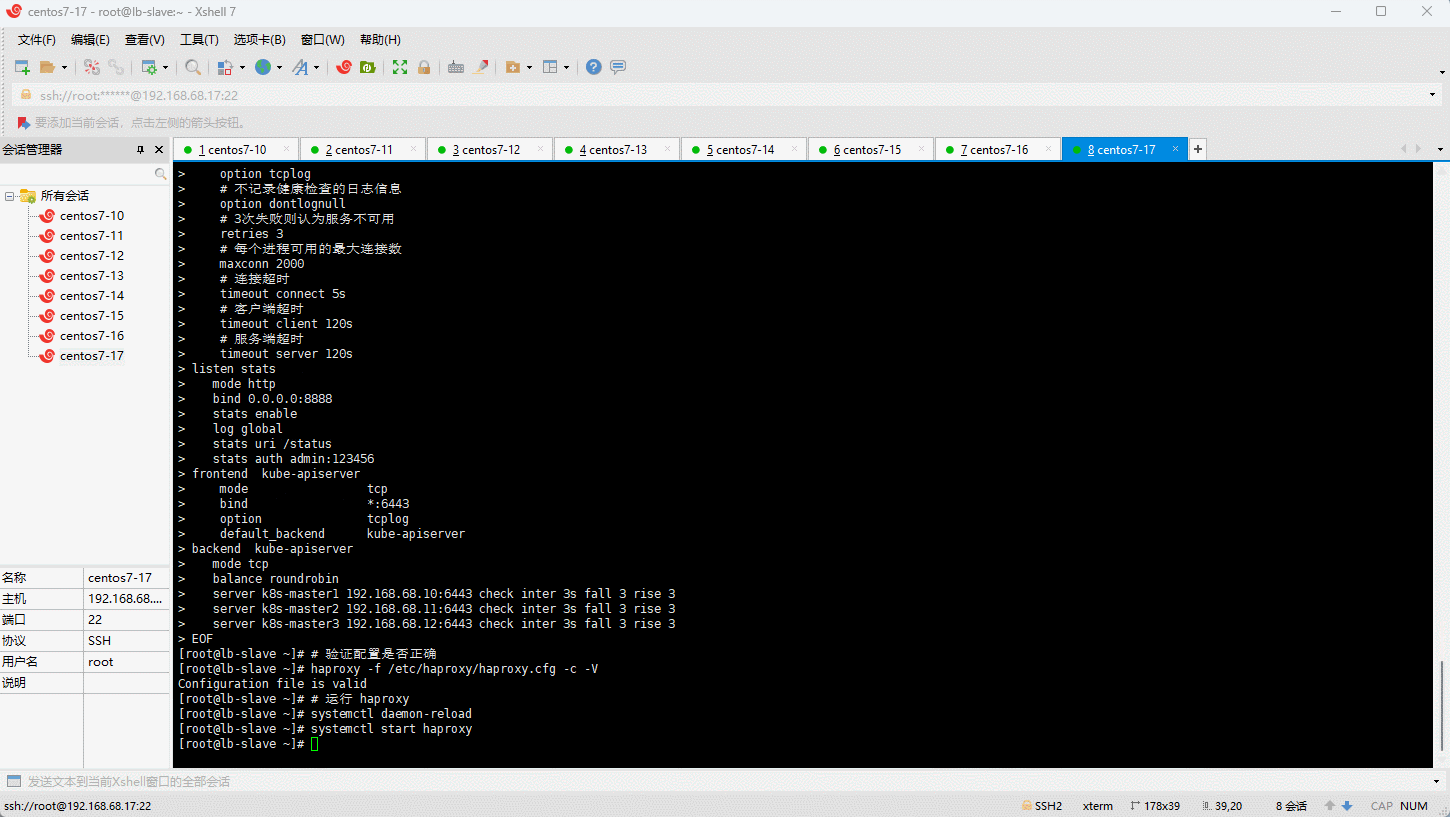
- 通过浏览器访问:

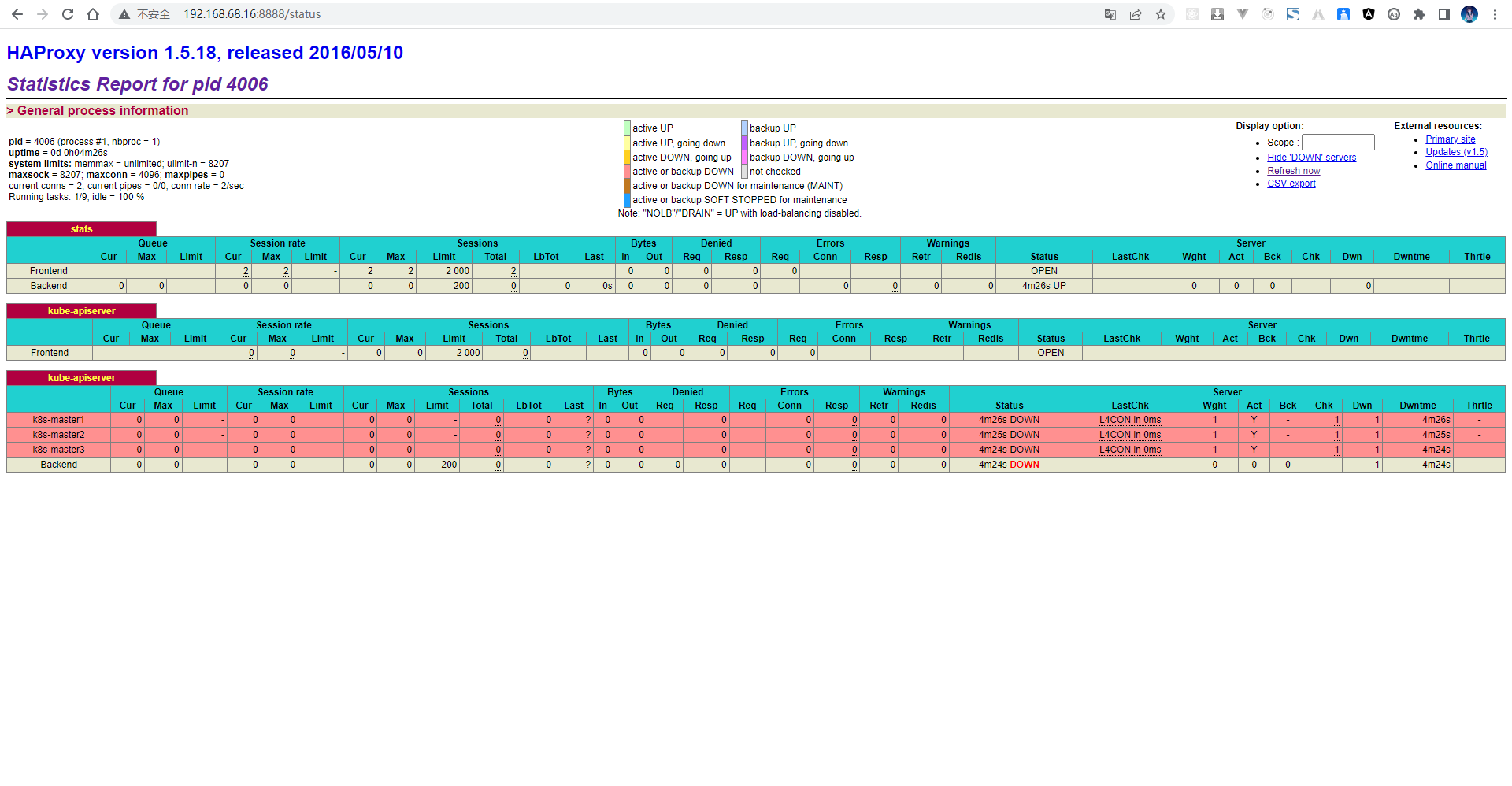
- 在 k8s-master1(192.168.10) 、k8s-master2(192.168.11) 和 k8s-master3(192.168.12)分别部署 nginx 来进行测试:
# k8s-master1(192.168.10)
docker run --restart=always -itd \
--privileged=true \
-p 6443:80 \
-v /etc/localtime:/etc/localtime \
--name nginx nginx:1.23.1
# k8s-master2(192.168.11)
docker run --restart=always -itd \
--privileged=true \
-p 6443:80 \
-v /etc/localtime:/etc/localtime \
--name nginx nginx:1.23.2
# k8s-master3(192.168.12)
docker run --restart=always -itd \
--privileged=true \
-p 6443:80 \
-v /etc/localtime:/etc/localtime \
--name nginx nginx:1.23.3

- 再次通过浏览器来查看:

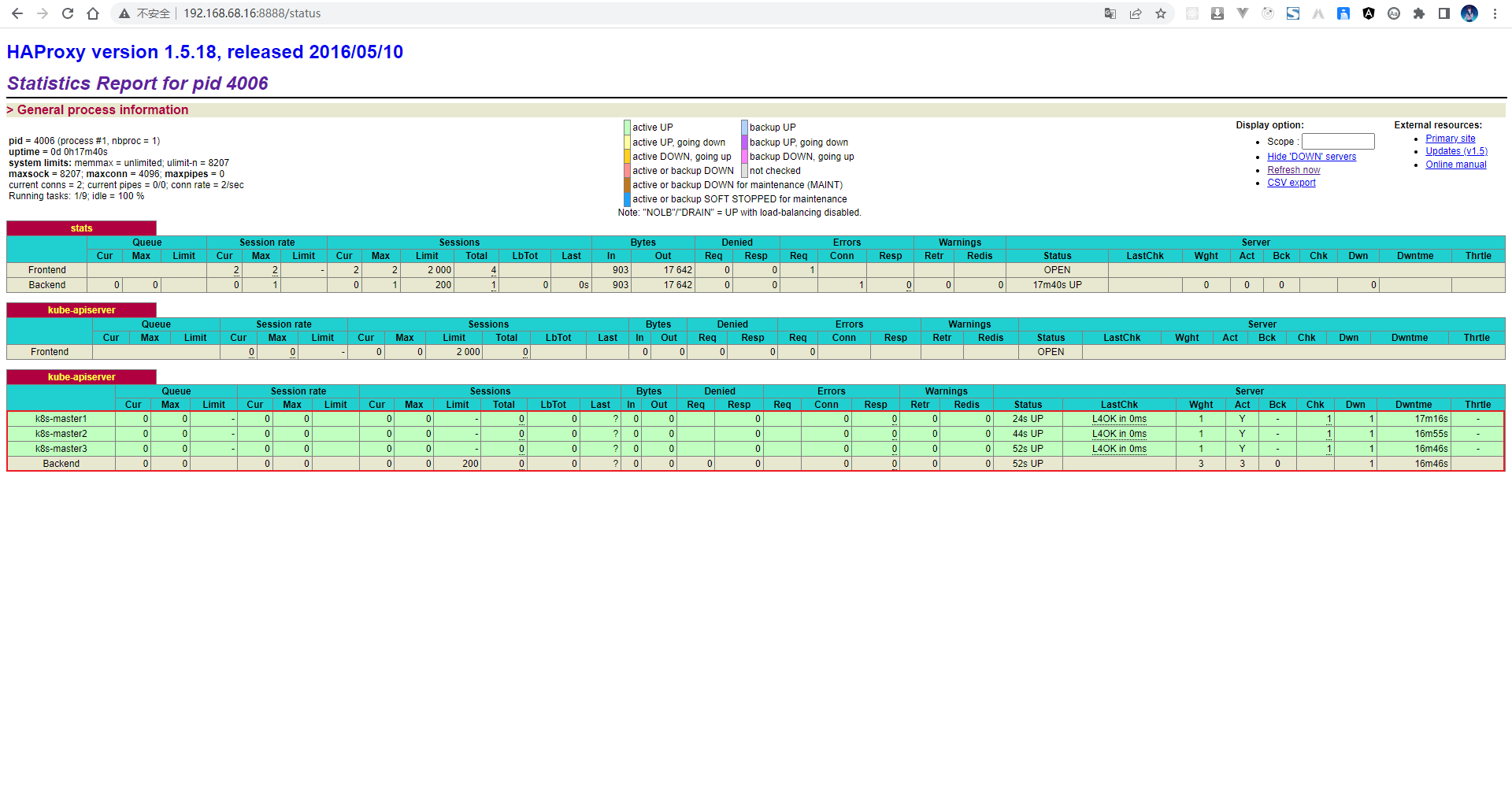
注意:测试完毕之后,需要将 k8s-master1、k8s-master2 以及 k8s-master3 上的容器删除,防止影响后面的操作:
docker rm -f $(docker ps -qa)
5.2.2 安装和配置 keepalived
- 我们利用 keepalived来实现 VIP :
# lb-master(192.168.68.16)执行
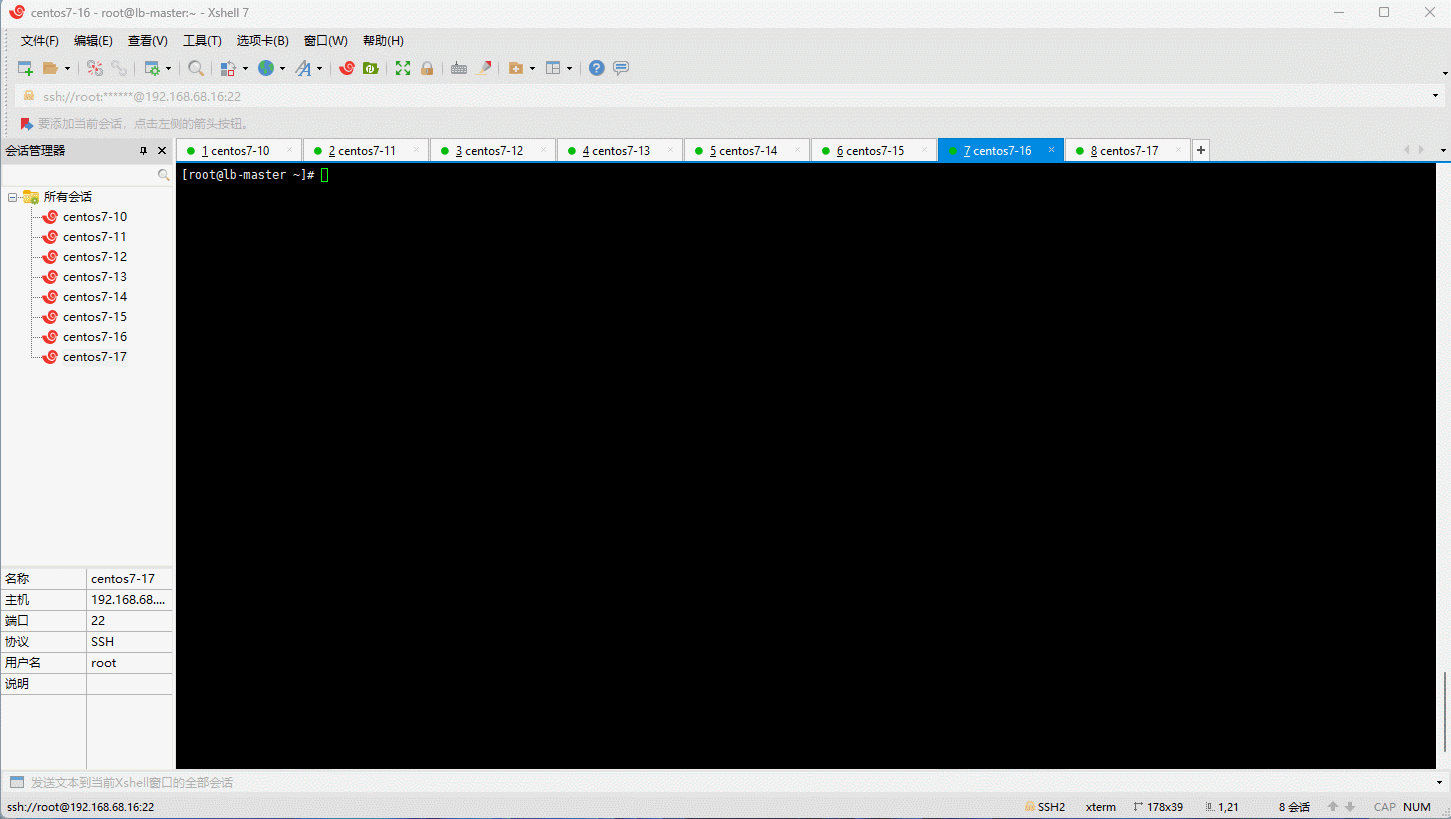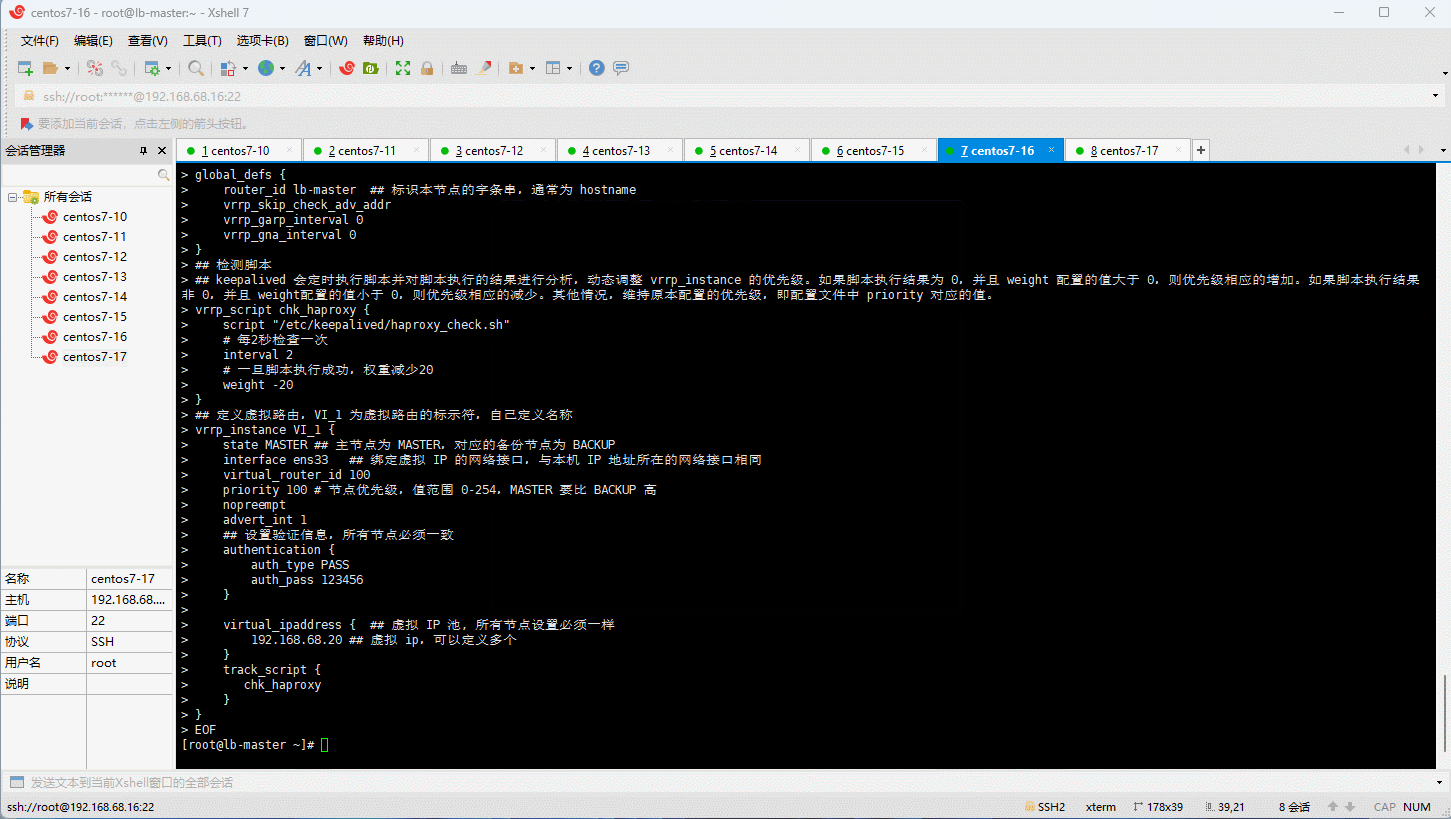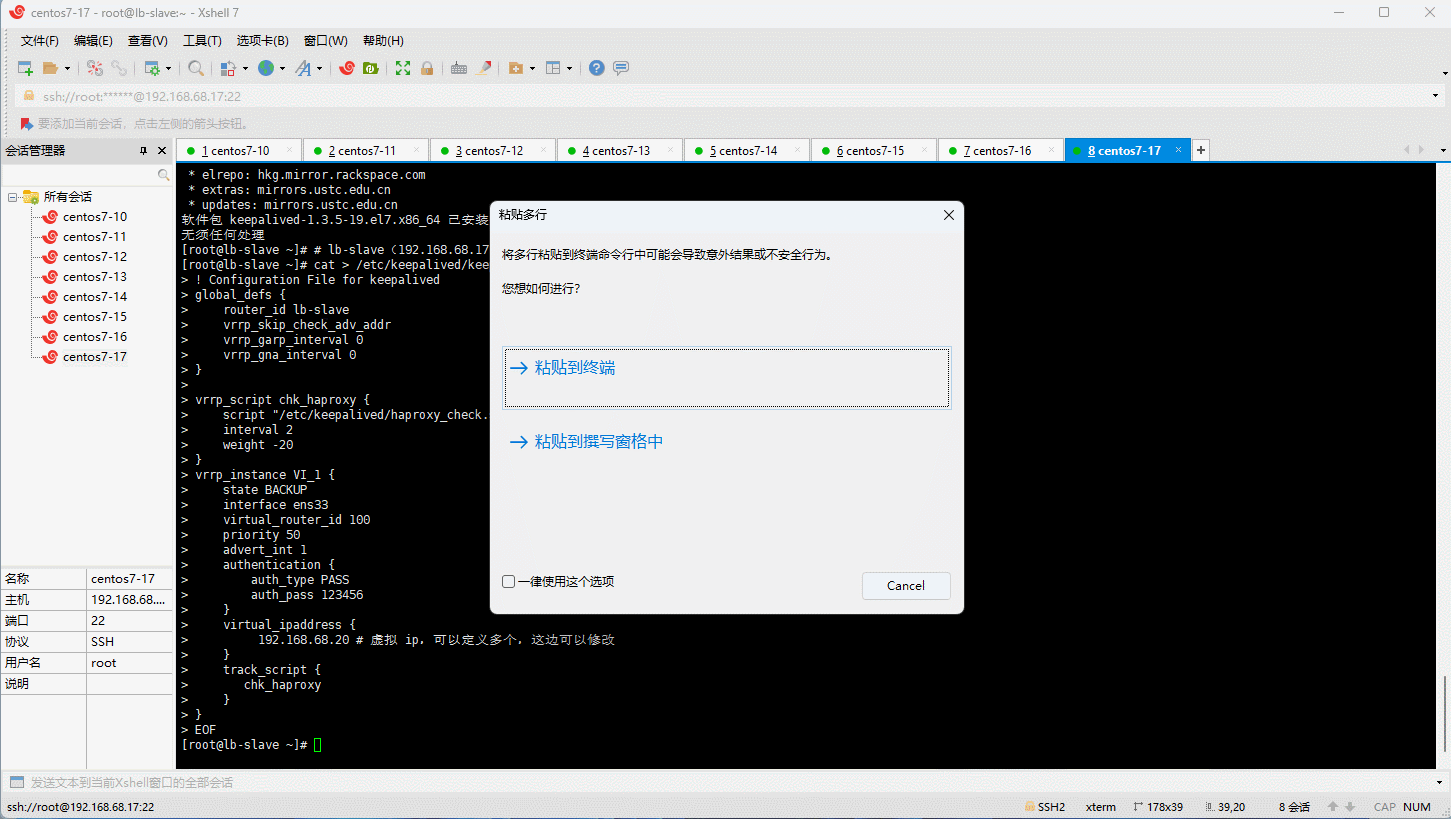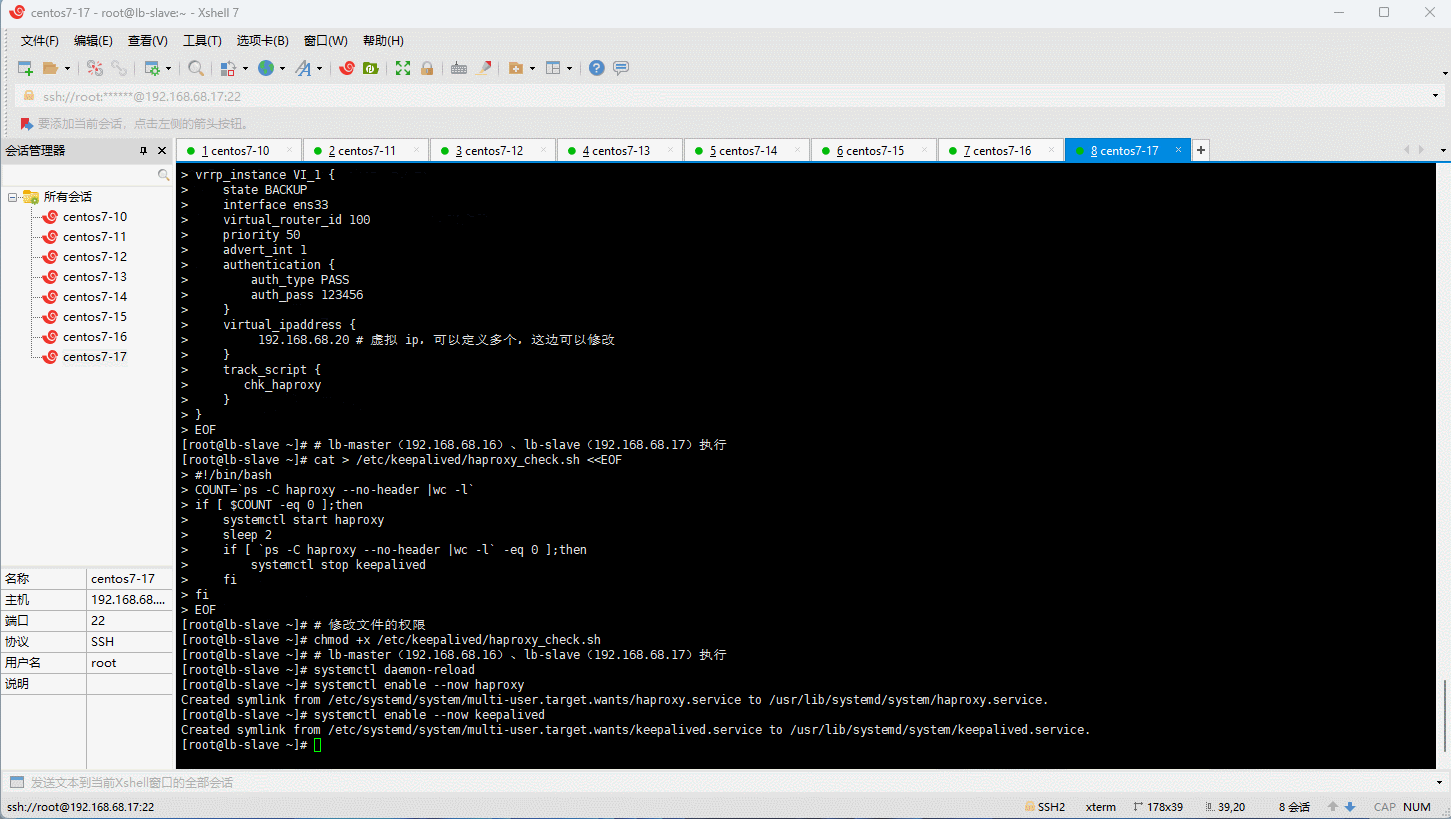
cat > /etc/keepalived/keepalived.conf <<EOF
! Configuration File for keepalived
global_defs {
router_id lb-master ## 标识本节点的字条串,通常为 hostname
vrrp_skip_check_adv_addr
vrrp_garp_interval 0
vrrp_gna_interval 0
}
## 检测脚本
## keepalived 会定时执行脚本并对脚本执行的结果进行分析,动态调整 vrrp_instance 的优先级。如果脚本执行结果为 0,并且 weight 配置的值大于 0,则优先级相应的增加。如果脚本执行结果非 0,并且 weight配置的值小于 0,则优先级相应的减少。其他情况,维持原本配置的优先级,即配置文件中 priority 对应的值。
vrrp_script chk_haproxy {
script "/etc/keepalived/haproxy_check.sh"
# 每2秒检查一次
interval 2
# 一旦脚本执行成功,权重减少20
weight -20
}
## 定义虚拟路由,VI_1 为虚拟路由的标示符,自己定义名称
vrrp_instance VI_1 {
state MASTER ## 主节点为 MASTER,对应的备份节点为 BACKUP
interface ens33 ## 绑定虚拟 IP 的网络接口,与本机 IP 地址所在的网络接口相同
virtual_router_id 100
priority 100 # 节点优先级,值范围 0-254,MASTER 要比 BACKUP 高
nopreempt
advert_int 1
## 设置验证信息,所有节点必须一致
authentication {
auth_type PASS
auth_pass 123456
}
virtual_ipaddress { ## 虚拟 IP 池, 所有节点设置必须一样
192.168.68.20 ## 虚拟 ip,可以定义多个
}
track_script {
chk_haproxy
}
}
EOF
# lb-slave(192.168.68.17)执行
cat > /etc/keepalived/keepalived.conf <<EOF
! Configuration File for keepalived
global_defs {
router_id lb-slave
vrrp_skip_check_adv_addr
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_script chk_haproxy {
script "/etc/keepalived/haproxy_check.sh"
interval 2
weight -20
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
virtual_router_id 100
priority 50
advert_int 1
authentication {
auth_type PASS
auth_pass 123456
}
virtual_ipaddress {
192.168.68.20 # 虚拟 ip,可以定义多个,这边可以修改
}
track_script {
chk_haproxy
}
}
EOF
# lb-master(192.168.68.16)、lb-slave(192.168.68.17)执行
cat > /etc/keepalived/haproxy_check.sh <<EOF
#!/bin/bash
COUNT=`ps -C haproxy --no-header |wc -l`
if [ $COUNT -eq 0 ];then
systemctl start haproxy
sleep 2
if [ `ps -C haproxy --no-header |wc -l` -eq 0 ];then
systemctl stop keepalived
fi
fi
EOF
# 修改文件的权限
chmod +x /etc/keepalived/haproxy_check.sh
# lb-master(192.168.68.16)、lb-slave(192.168.68.17)执行
systemctl daemon-reload
systemctl enable --now haproxy
systemctl enable --now keepalived

- 测试:

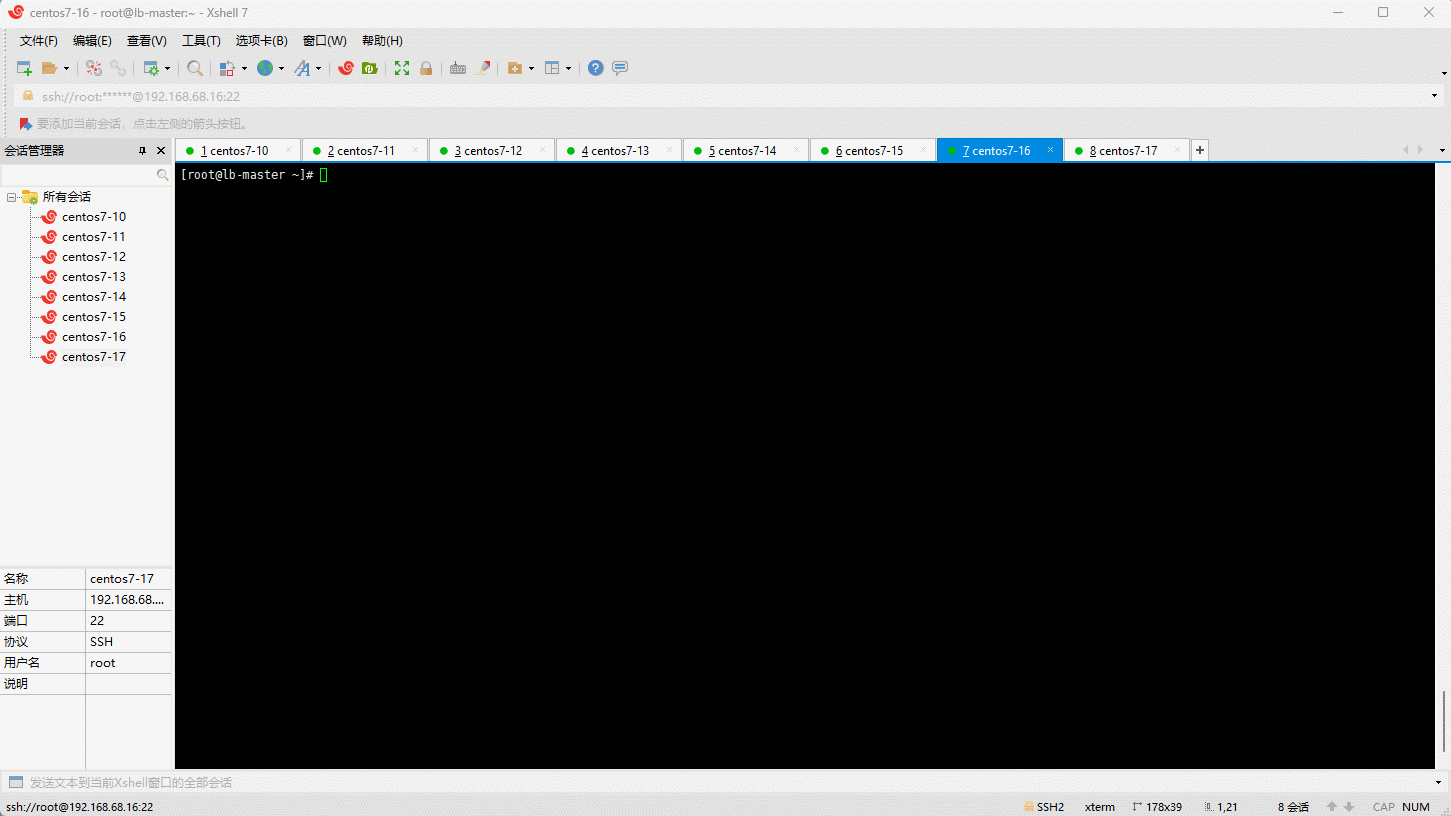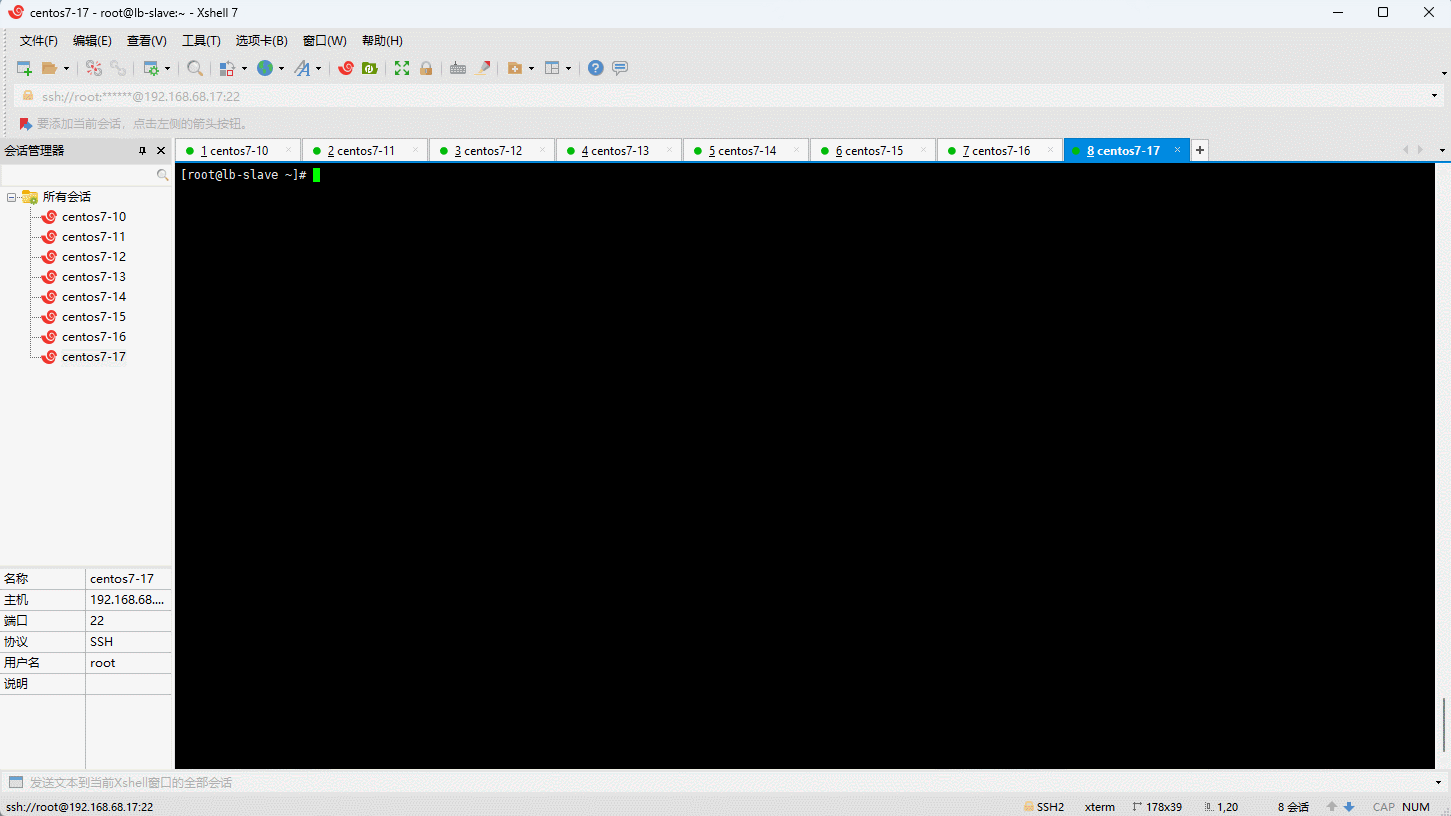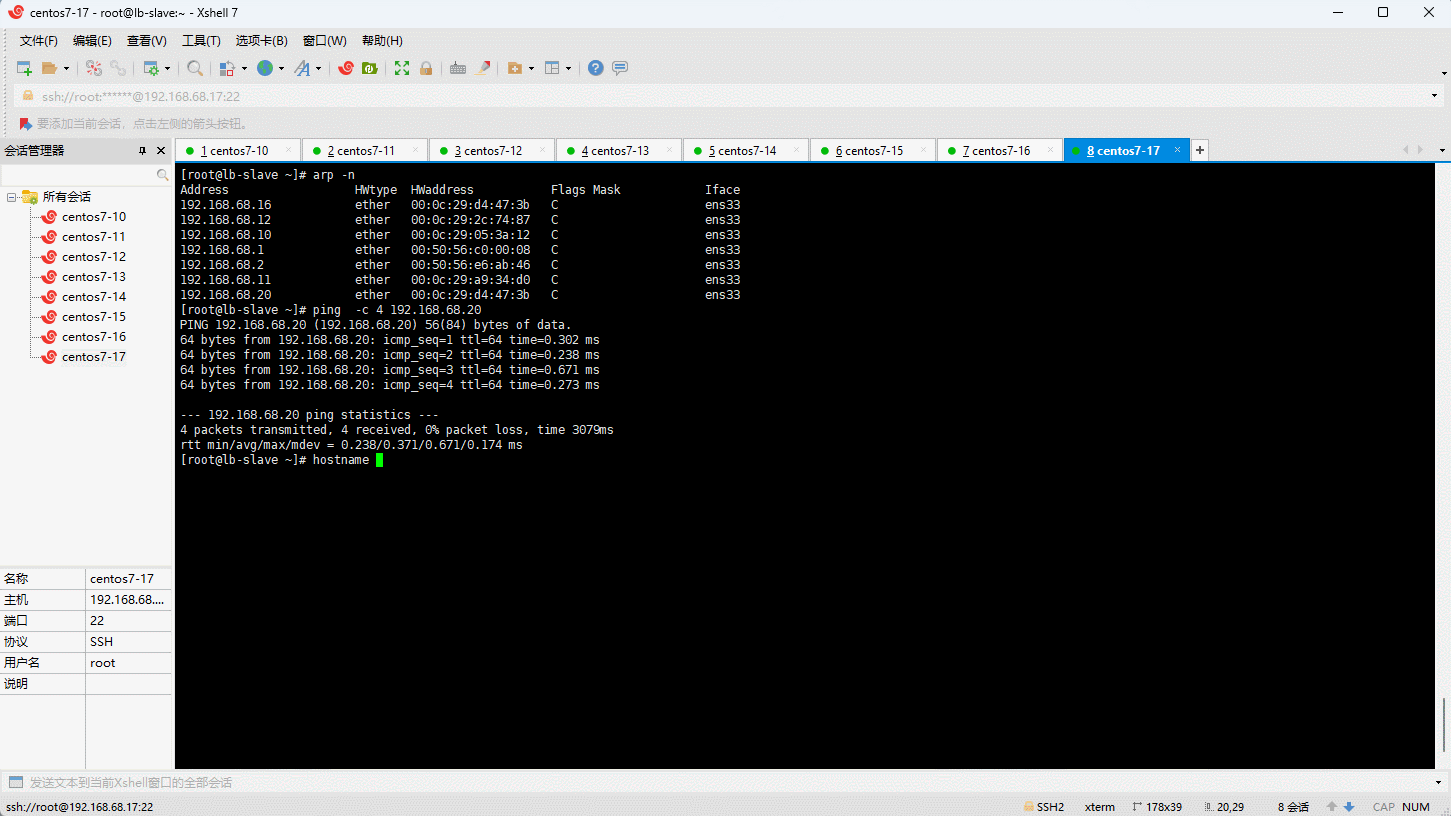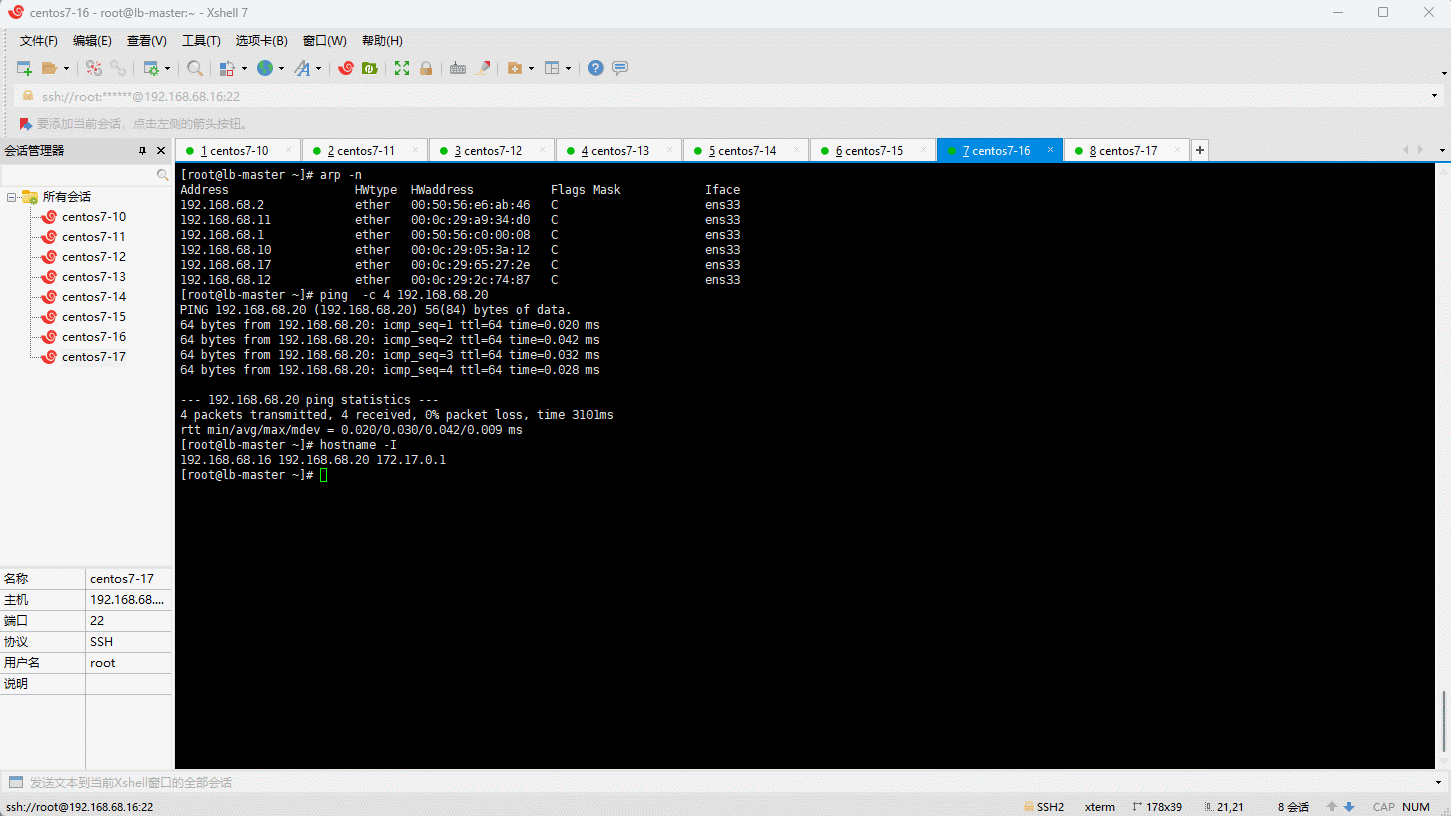
- 通过浏览器查看:

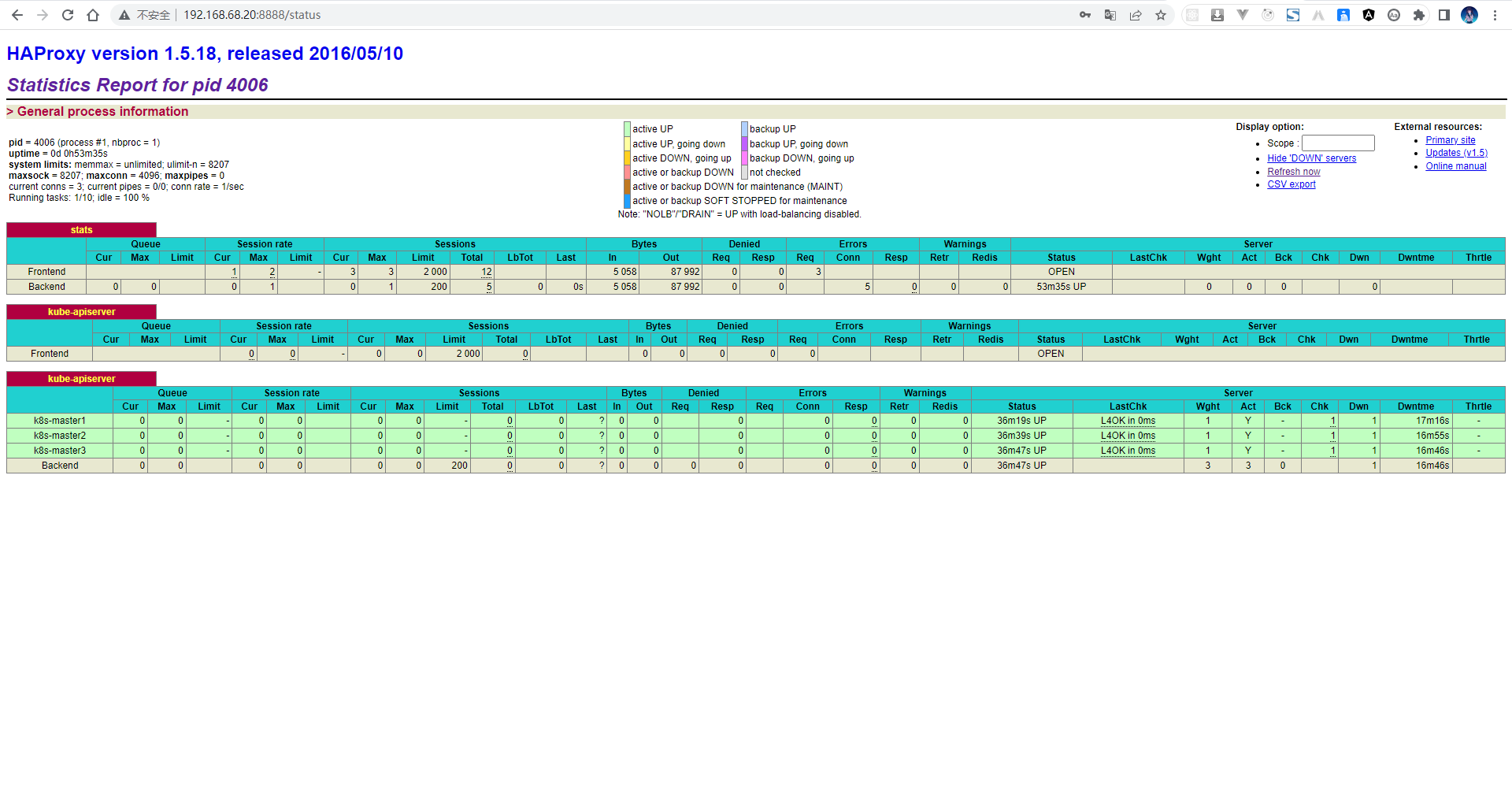
5.3 基于 Docker 配置 VIP
5.3.1 安装和配置 Haproxy
- 我们利用 Haproxy 来实现 Kubernetes 的 api-server 的负载均衡 ::
# lb-master(192.168.68.16) 和 lb-slave (192.168.68.17)修改配置文件
mkdir -pv /etc/haproxy/
cat > /etc/haproxy/haproxy.cfg <<EOF
global
log 127.0.0.1 local0 info
maxconn 4096
daemon
defaults
log global
mode tcp
option tcplog
option dontlognull
retries 3
maxconn 2000
timeout connect 5s
timeout client 120s
timeout server 120s
listen stats
mode http
bind 0.0.0.0:8888 # 这边可以修改
stats enable
log global
stats uri /status
stats auth admin:123456
frontend kube-apiserver
mode tcp
bind *:6443
option tcplog
default_backend kube-apiserver
backend kube-apiserver
mode tcp
balance roundrobin
# 下面是反向代理的 k8s-master 的 api-server 的 ip 和端口,可以修改
server k8s-master1 192.168.68.10:6443 check inter 3s fall 3 rise 3
server k8s-master2 192.168.68.11:6443 check inter 3s fall 3 rise 3
server k8s-master3 192.168.68.12:6443 check inter 3s fall 3 rise 3
EOF
docker run -d \
--name k8s-haproxy \
--net=host \
--restart=always \
-v /etc/haproxy/haproxy.cfg:/usr/local/etc/haproxy/haproxy.cfg:ro \
haproxy:2.7.4

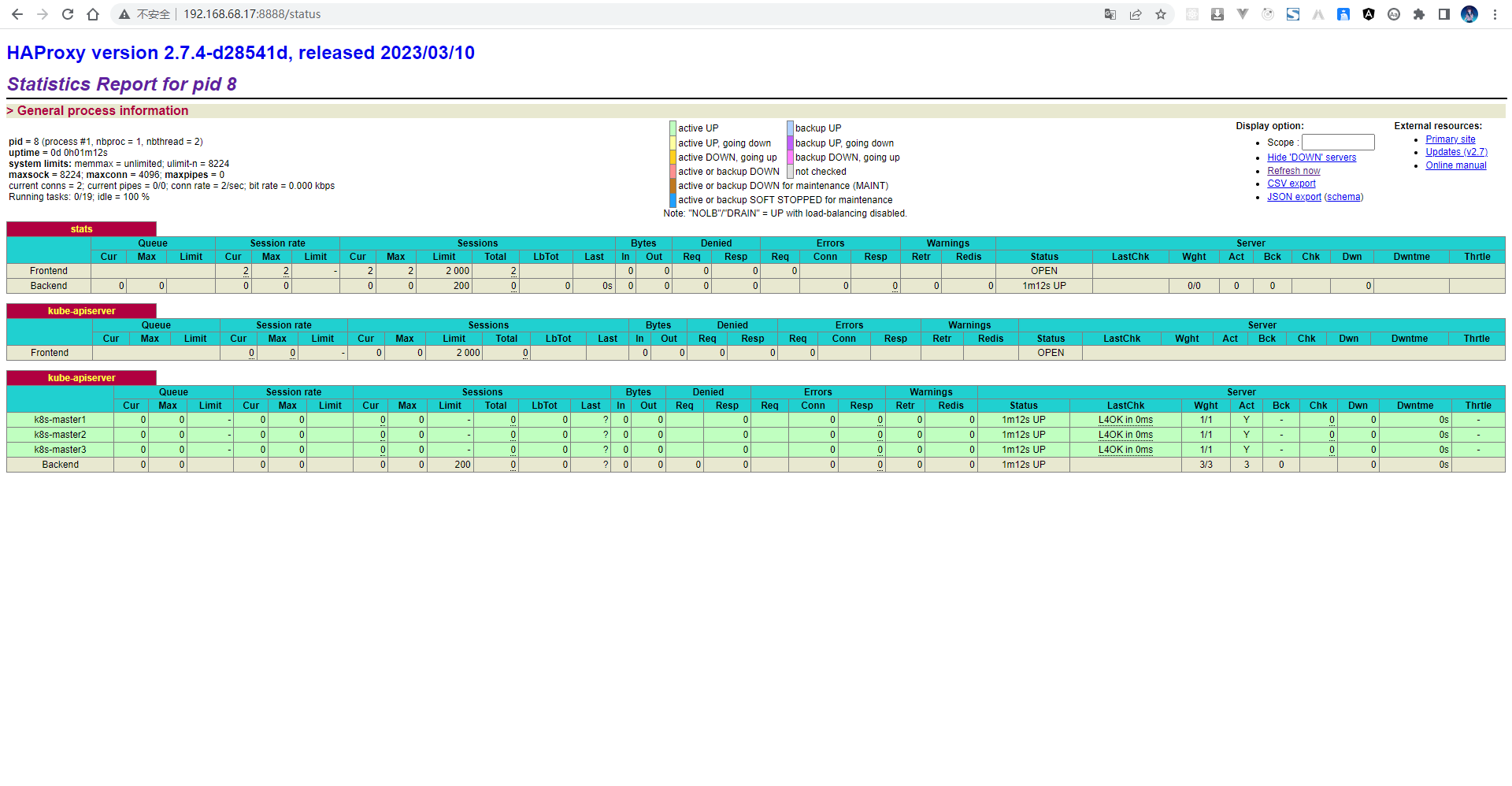
- 通过浏览器访问:

5.3.2 安装和配置 keepalived
- 在 lb-master(192.168.68.16)节点配置 keepalived:
# lb-master(192.168.68.16)执行
mkdir -pv /etc/keepalived/
cat > /etc/keepalived/keepalived.conf <<EOF
! Configuration File for keepalived
global_defs {
router_id lb-master ## 标识本节点的字条串,通常为 hostname
vrrp_skip_check_adv_addr
vrrp_garp_interval 0
vrrp_gna_interval 0
}
## 检测脚本
## keepalived 会定时执行脚本并对脚本执行的结果进行分析,动态调整 vrrp_instance 的优先级。如果脚本执行结果为 0,并且 weight 配置的值大于 0,则优先级相应的增加。如果脚本执行结果非 0,并且 weight配置的值小于 0,则优先级相应的减少。其他情况,维持原本配置的优先级,即配置文件中 priority 对应的值。
vrrp_script chk_haproxy {
script "/etc/keepalived/haproxy_check.sh"
# 每2秒检查一次
interval 2
# 一旦脚本执行成功,权重减少20
weight -20
}
## 定义虚拟路由,VI_1 为虚拟路由的标示符,自己定义名称
vrrp_instance VI_1 {
state MASTER ## 主节点为 MASTER,对应的备份节点为 BACKUP
interface ens33 ## 绑定虚拟 IP 的网络接口,与本机 IP 地址所在的网络接口相同
virtual_router_id 100
priority 100 # 节点优先级,值范围 0-254,MASTER 要比 BACKUP 高
nopreempt
advert_int 1
## 设置验证信息,所有节点必须一致
authentication {
auth_type PASS
auth_pass 123456
}
virtual_ipaddress { ## 虚拟 IP 池, 所有节点设置必须一样
192.168.68.20 ## 虚拟 ip,可以定义多个
}
track_script {
chk_haproxy
}
}
EOF
# lb-master(192.168.68.16)、lb-slave(192.168.68.17)执行
mkdir -pv /etc/keepalived/
cat > /etc/keepalived/haproxy_check.sh <<EOF
#!/bin/bash
COUNT=`ps -C haproxy --no-header |wc -l`
if [ $COUNT -eq 0 ];then
systemctl start haproxy
sleep 2
if [ `ps -C haproxy --no-header |wc -l` -eq 0 ];then
systemctl stop keepalived
fi
fi
EOF
# 修改文件的权限
chmod +x /etc/keepalived/haproxy_check.sh
docker run -d \
--name k8s-keepalived \
--restart=always \
--net=host \
--cap-add=NET_ADMIN \
--cap-add=NET_BROADCAST \
--cap-add=NET_RAW \
-v /etc/keepalived/keepalived.conf:/container/service/keepalived/assets/keepalived.conf \
-v /etc/keepalived/haproxy_check.sh:/usr/bin/check-haproxy.sh \
osixia/keepalived:2.0.20 \
--copy-service


- 在 lb-slave(192.168.68.17)节点配置 keepalived:
# lb-slave(192.168.68.17)执行
mkdir -pv /etc/keepalived/
cat > /etc/keepalived/keepalived.conf <<EOF
! Configuration File for keepalived
global_defs {
router_id lb-slave
vrrp_skip_check_adv_addr
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_script chk_haproxy {
script "/etc/keepalived/haproxy_check.sh"
interval 2
weight -20
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
virtual_router_id 100
priority 50
advert_int 1
authentication {
auth_type PASS
auth_pass 123456
}
virtual_ipaddress {
192.168.68.20 # 虚拟 ip,可以定义多个,这边可以修改
}
track_script {
chk_haproxy
}
}
EOF
# lb-master(192.168.68.16)、lb-slave(192.168.68.17)执行
mkdir -pv /etc/keepalived/
cat > /etc/keepalived/haproxy_check.sh <<EOF
#!/bin/bash
COUNT=`ps -C haproxy --no-header |wc -l`
if [ $COUNT -eq 0 ];then
systemctl start haproxy
sleep 2
if [ `ps -C haproxy --no-header |wc -l` -eq 0 ];then
systemctl stop keepalived
fi
fi
EOF
# 修改文件的权限
chmod +x /etc/keepalived/haproxy_check.sh
docker run -d \
--name k8s-keepalived \
--restart=always \
--net=host \
--cap-add=NET_ADMIN \
--cap-add=NET_BROADCAST \
--cap-add=NET_RAW \
-v /etc/keepalived/keepalived.conf:/container/service/keepalived/assets/keepalived.conf \
-v /etc/keepalived/haproxy_check.sh:/usr/bin/check-haproxy.sh \
osixia/keepalived:2.0.20 \
--copy-service

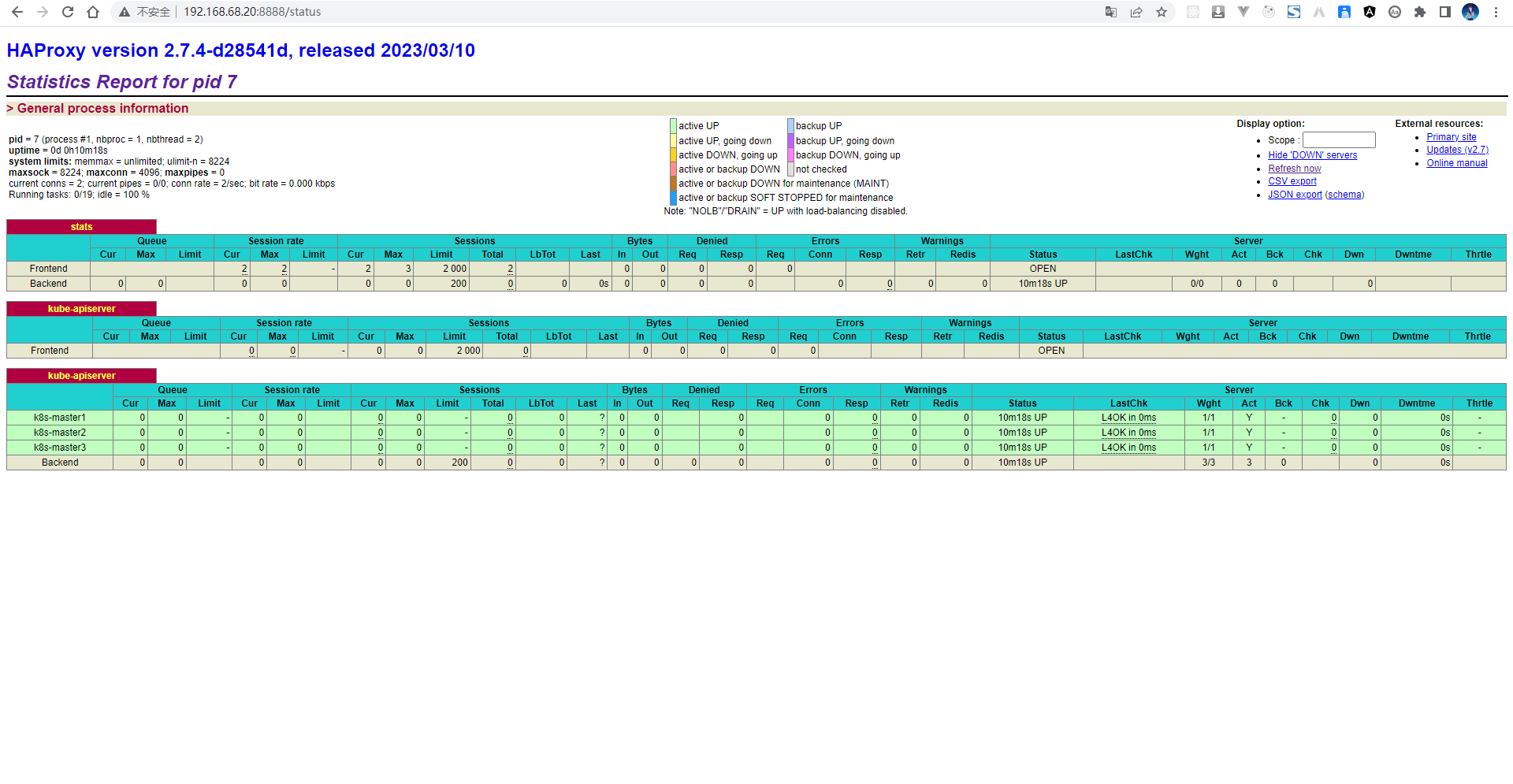
- 通过浏览器测试:

第六章:安装 Kubernetes
6.1 添加阿里云的 Kubernetes 的 YUM 源
- 由于 Kubernetes 的镜像源在国外,非常慢,这里切换成国内的阿里云镜像源(三主三从机器均需执行下面命令):
cat > /etc/yum.repos.d/kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF

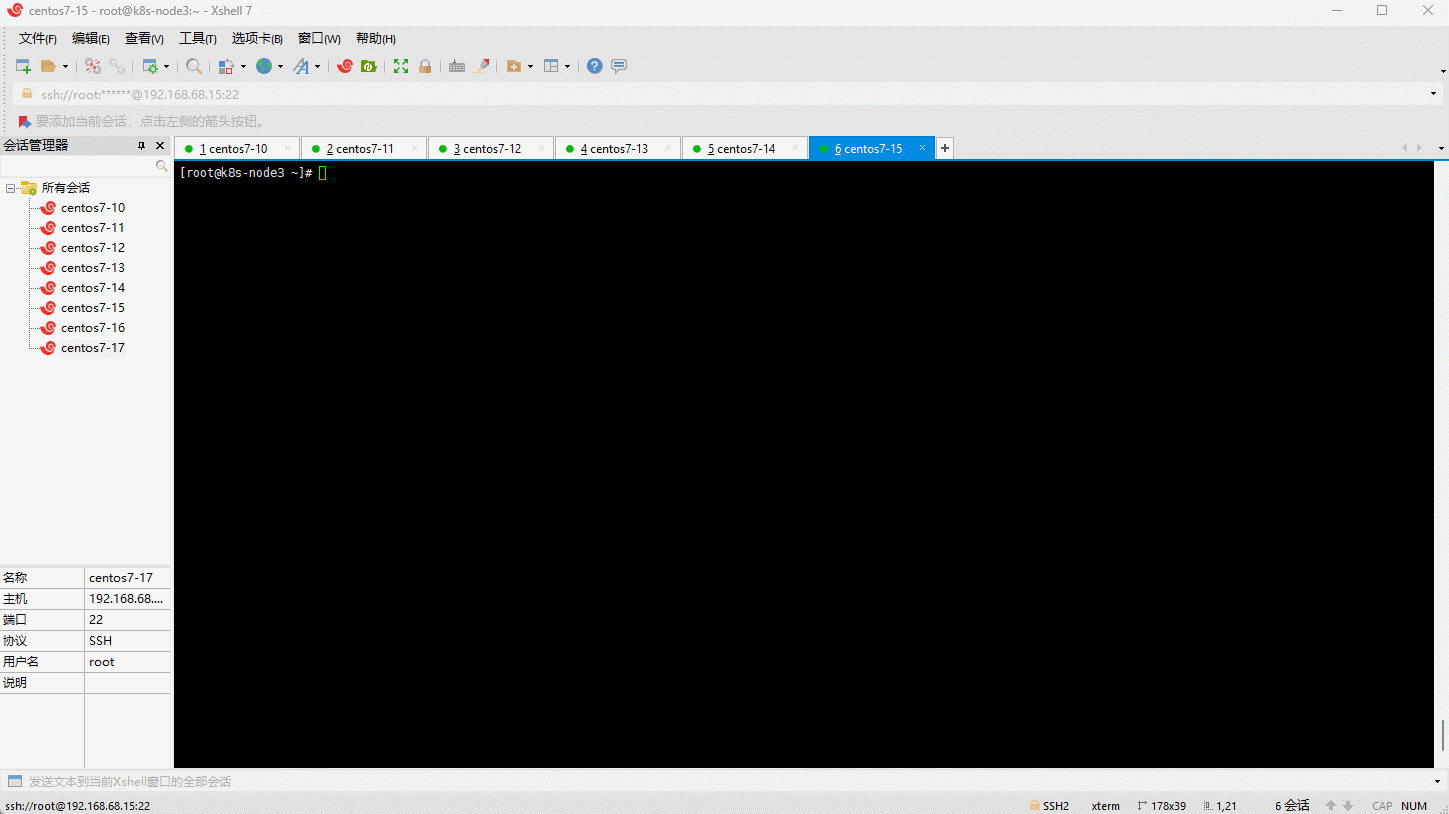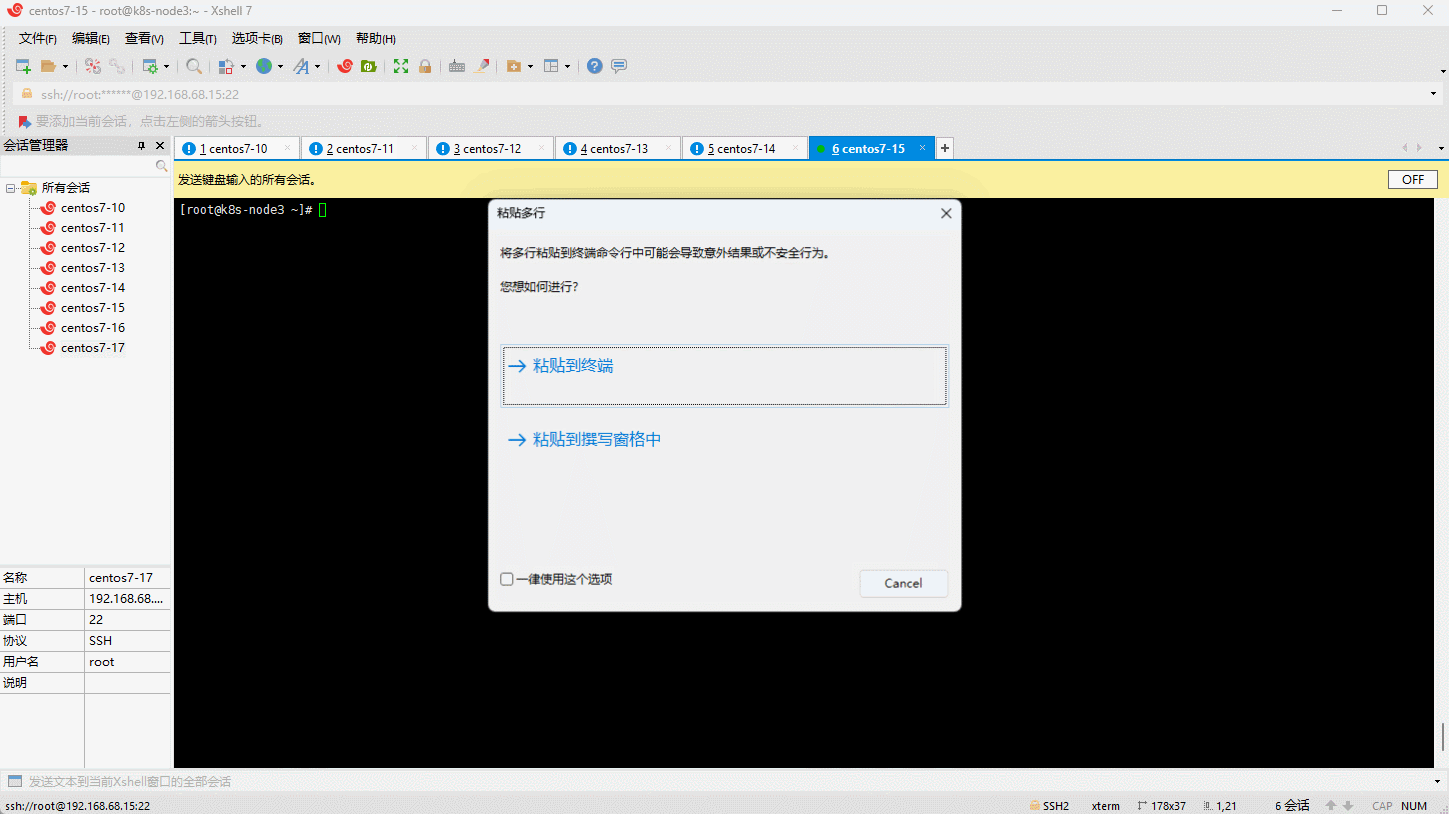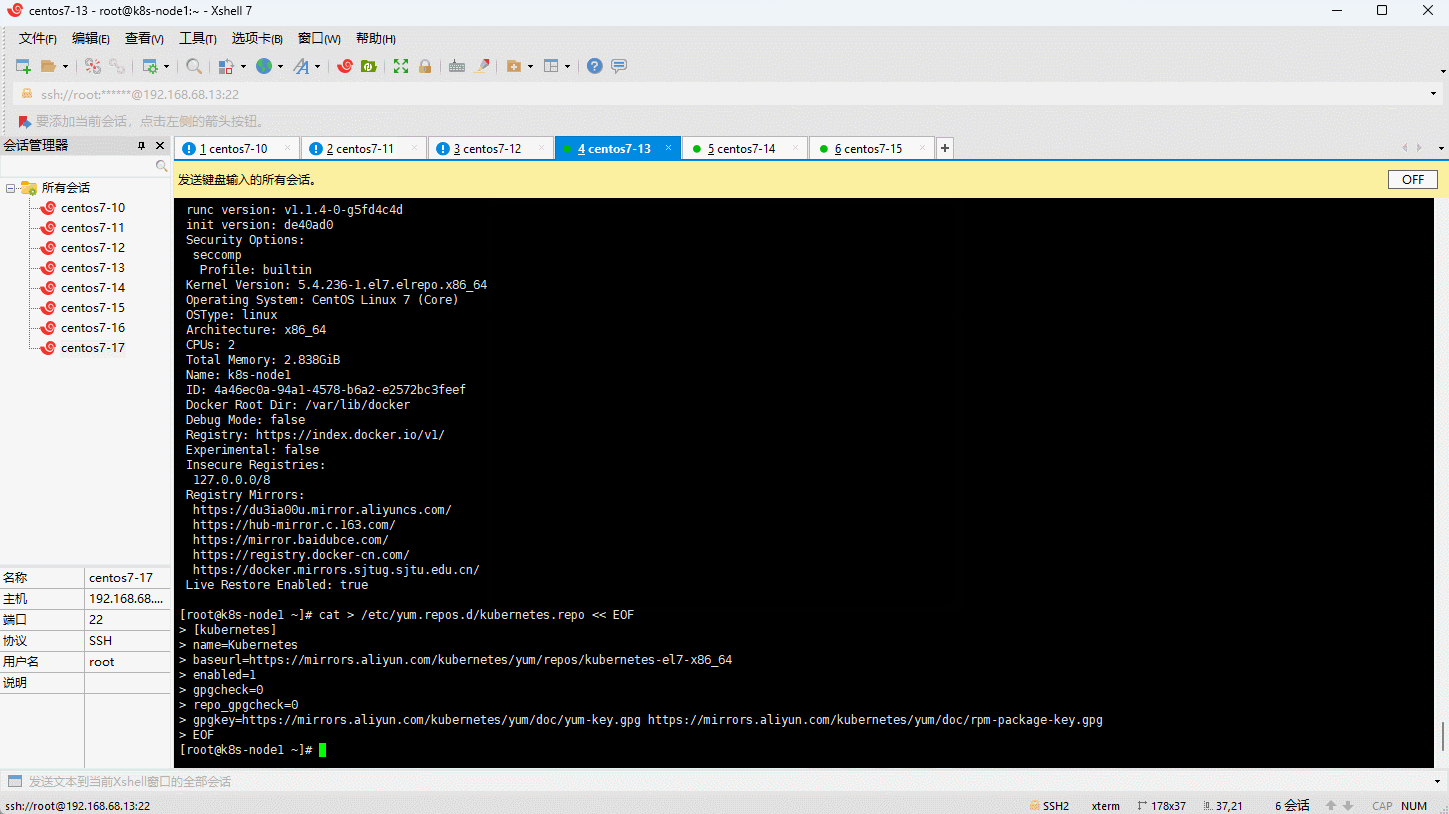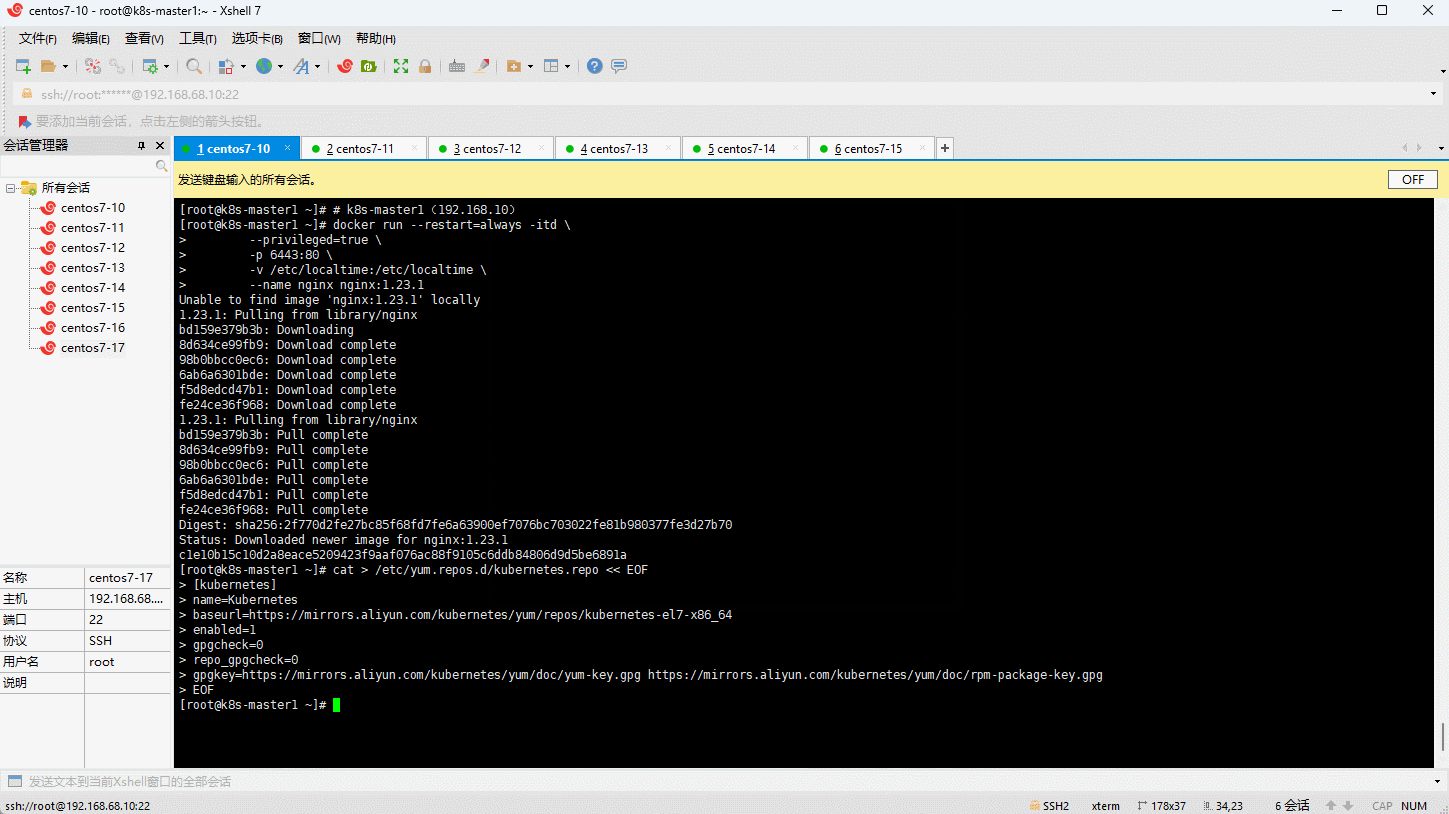
6.2 安装 kubelet 、kubeadm 和 kubectl
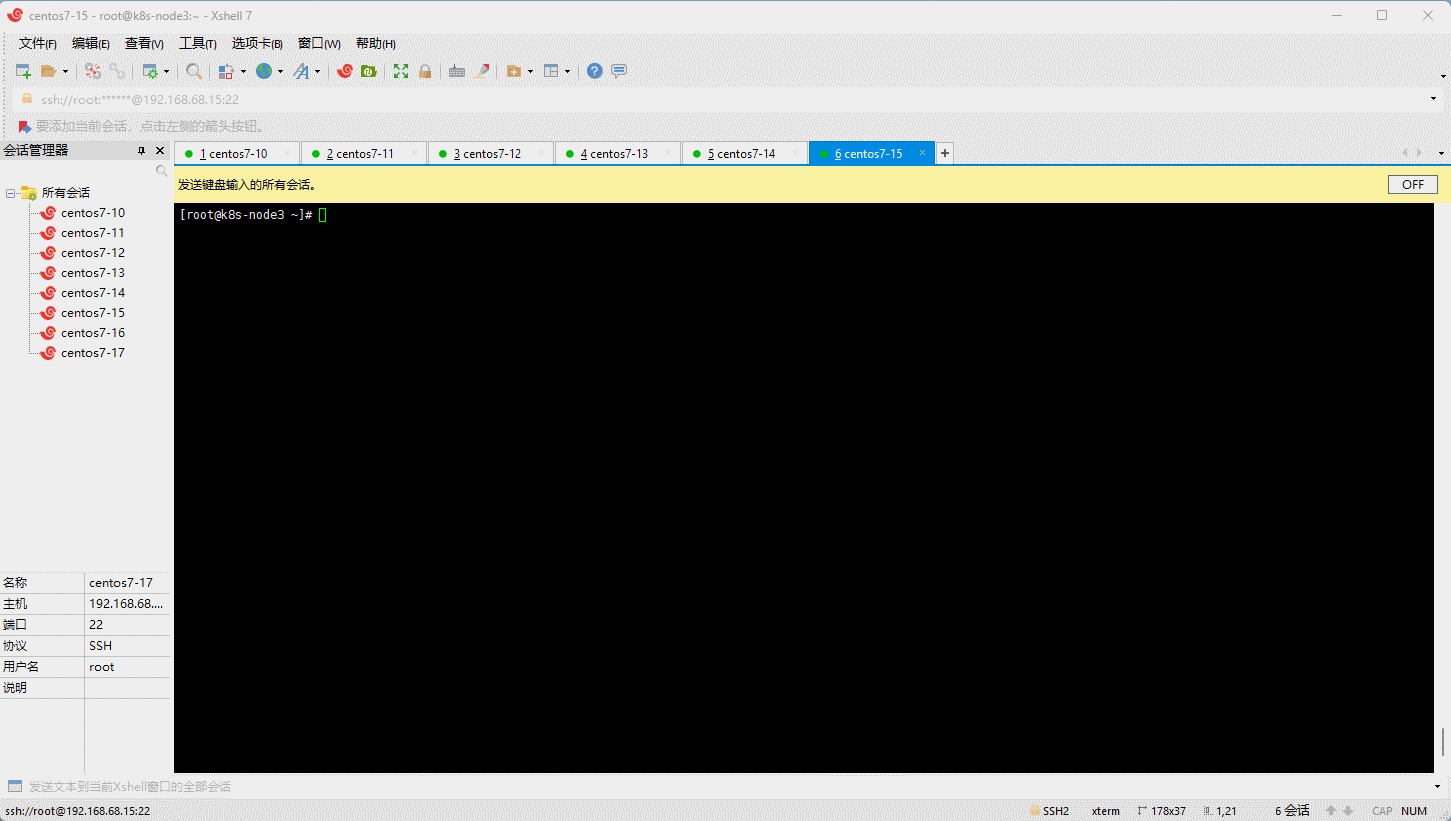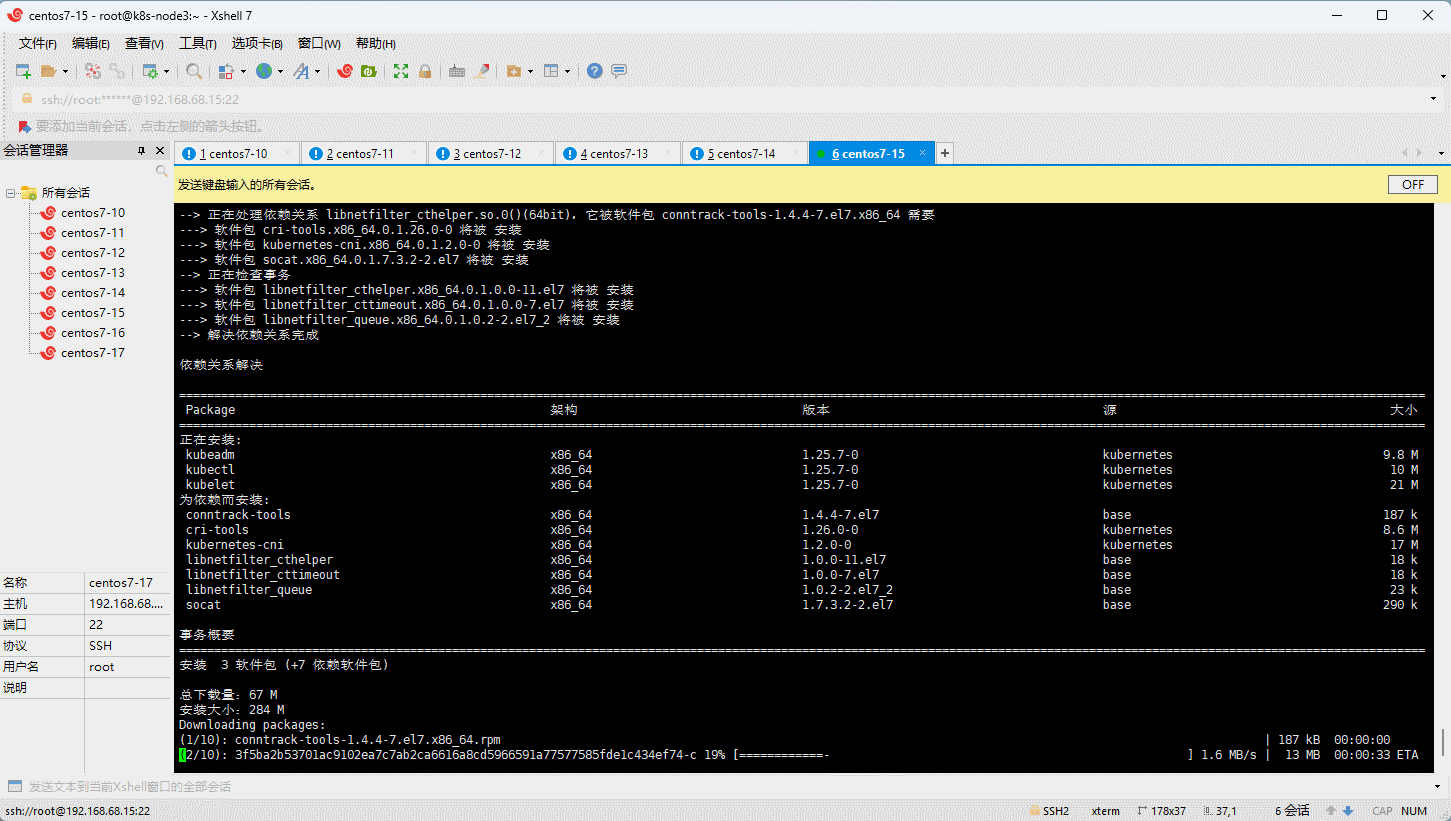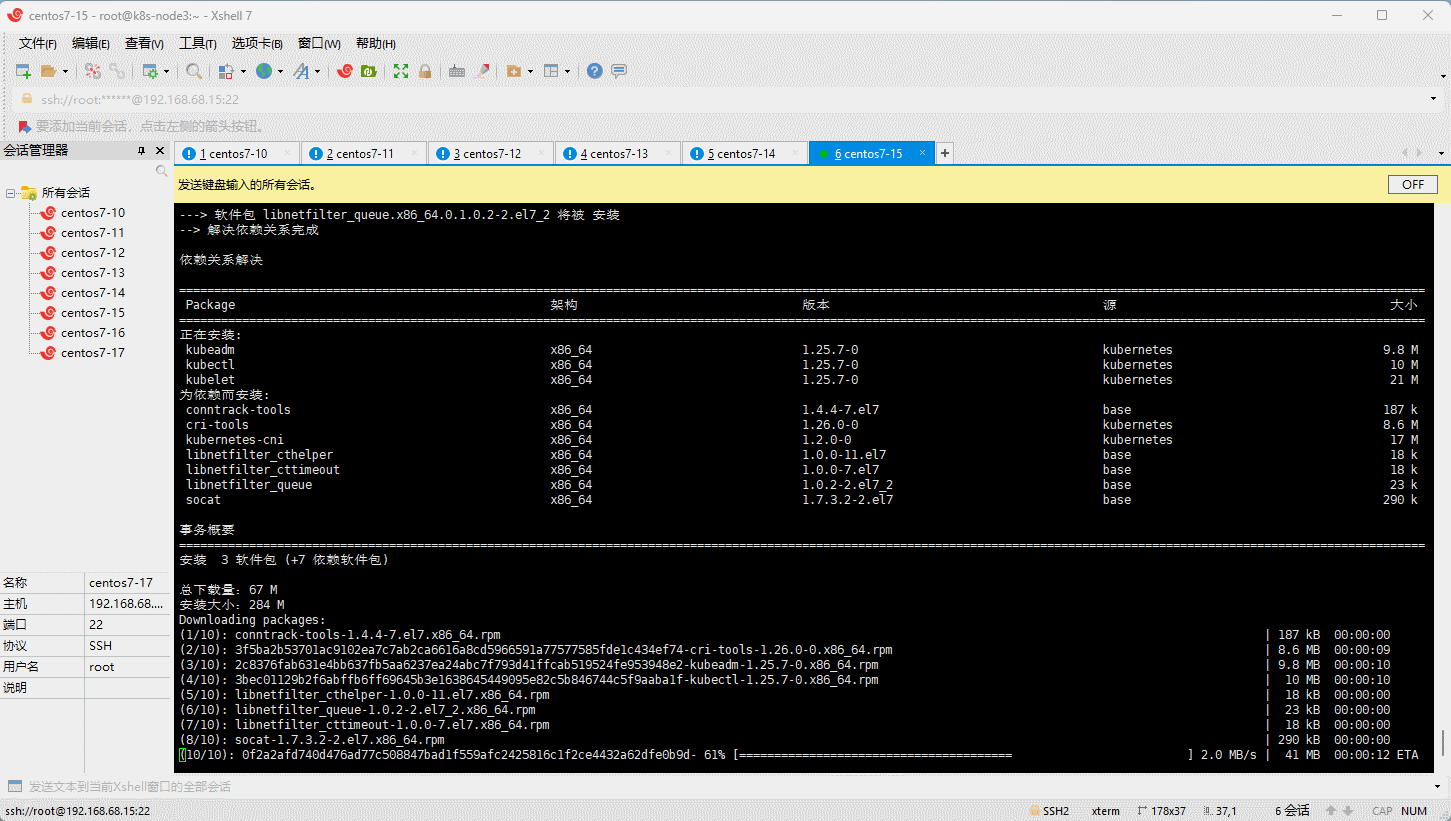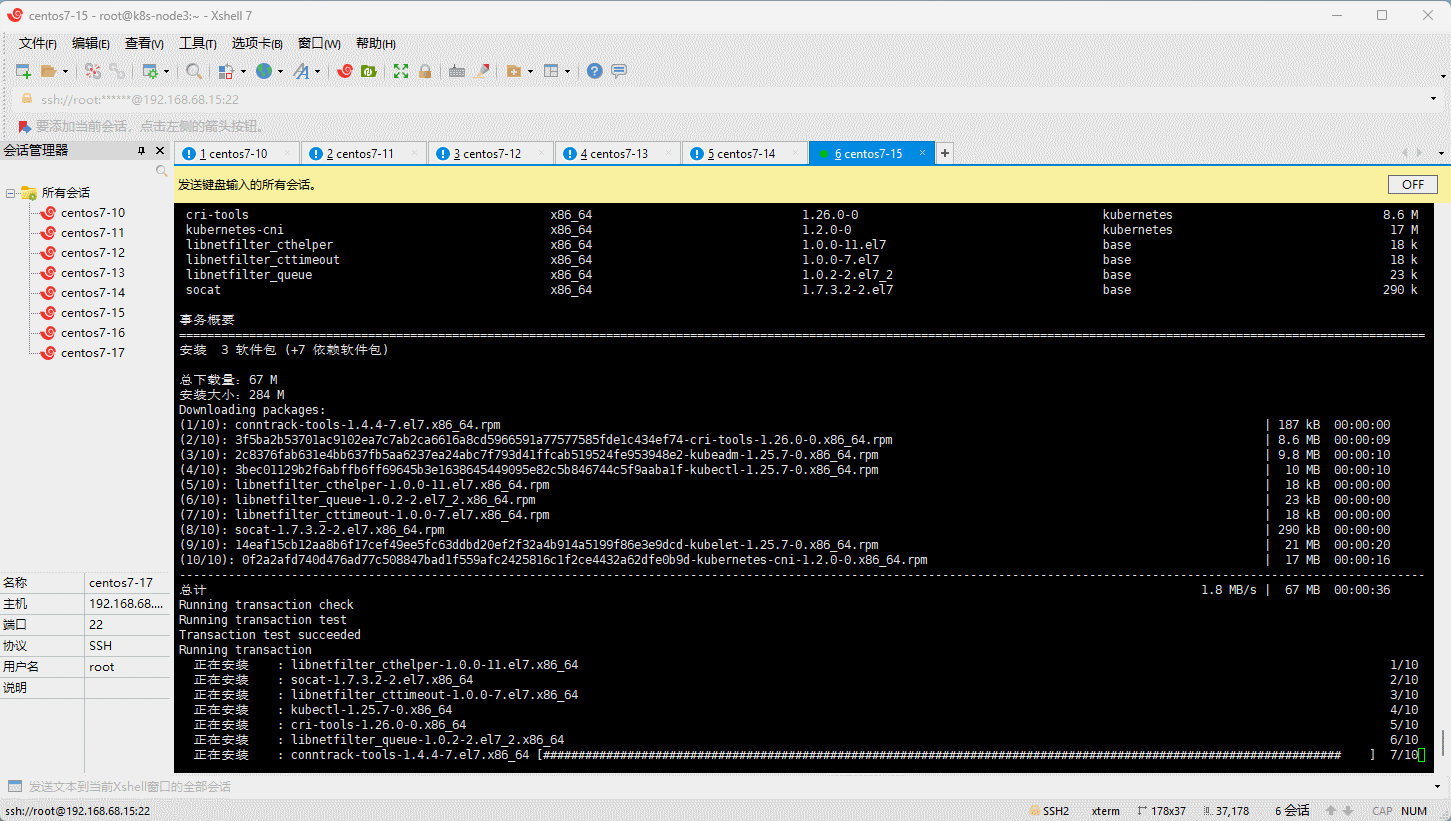
- 所有节点(三主三从机器)均需要安装 kubelet 、kubeadm 和 kubectl:

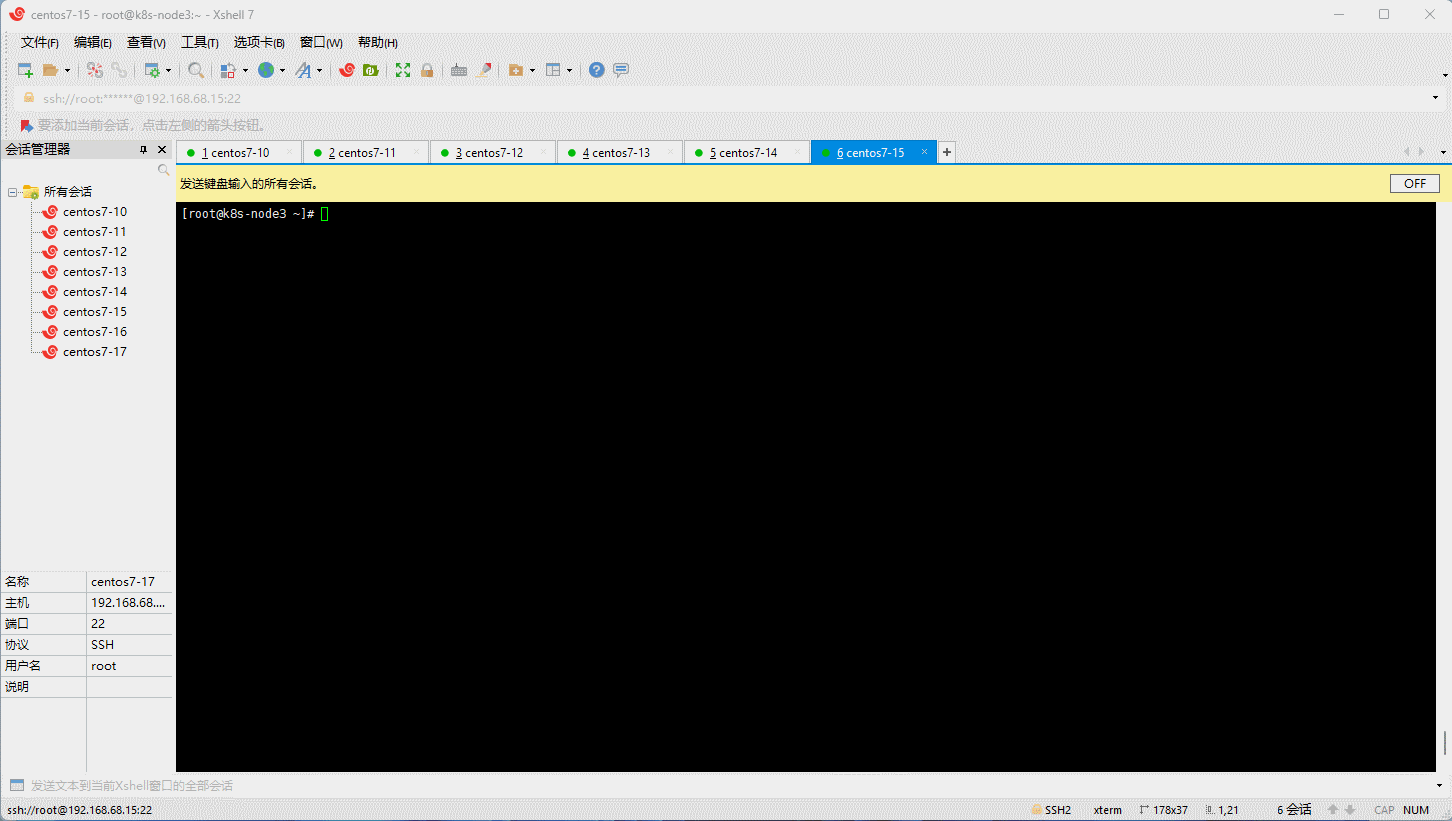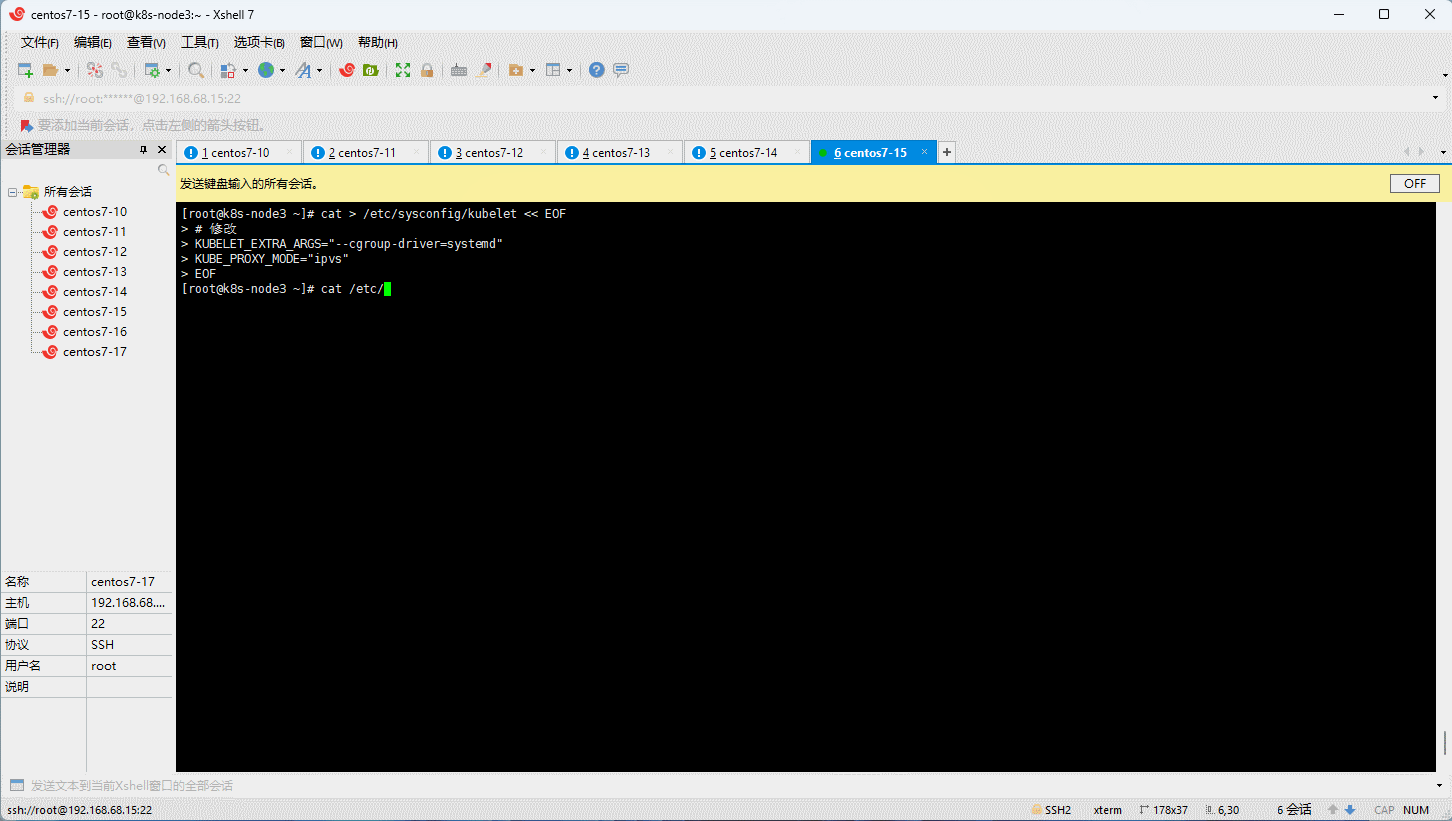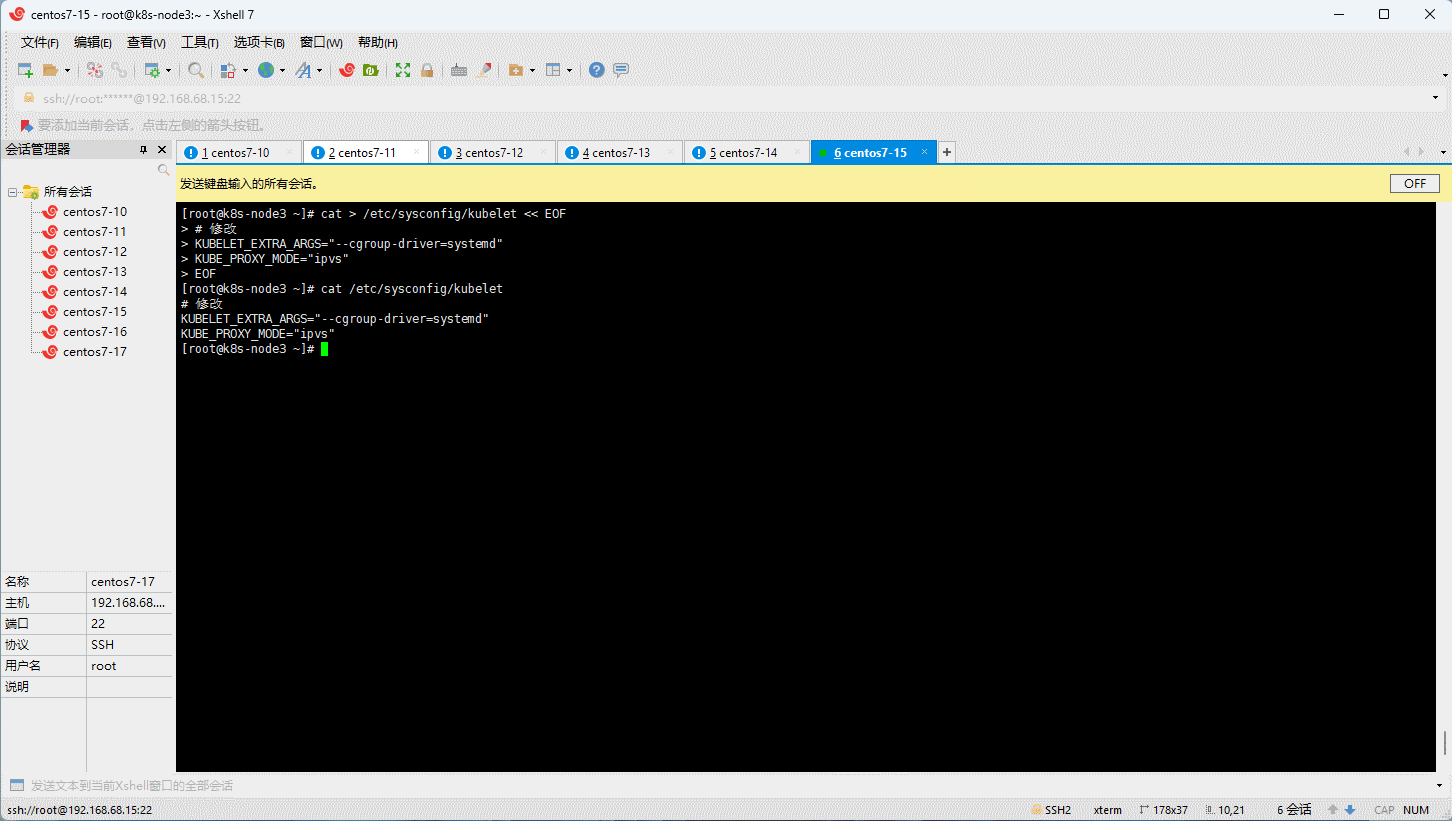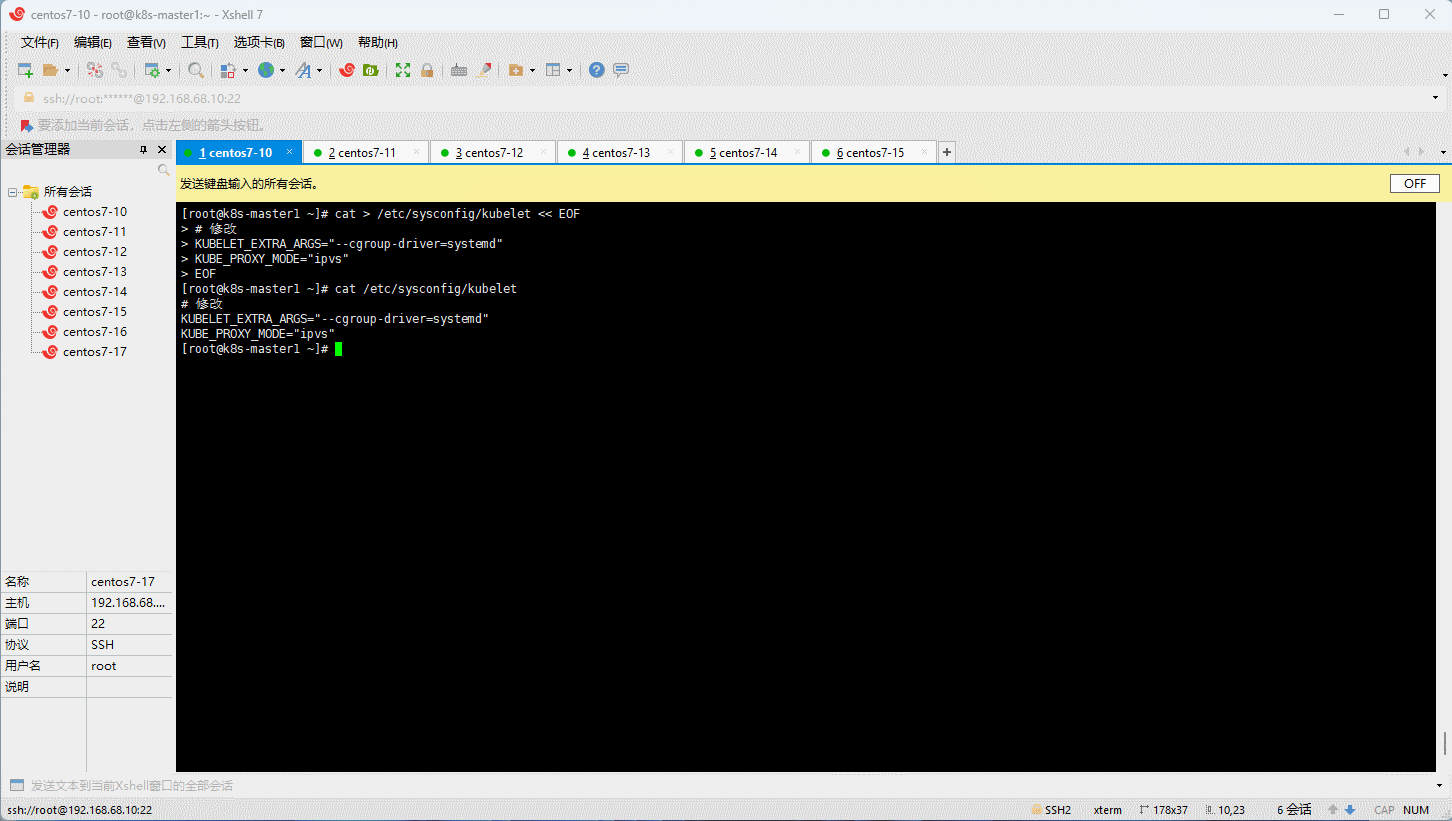
- 为了实现 Docker 使用的 cgroup drvier 和 kubelet 使用的 cgroup drver 一致,建议修改
/etc/sysconfig/kubelet文件的内容:
cat > /etc/sysconfig/kubelet << EOF
# 修改
KUBELET_EXTRA_ARGS="--cgroup-driver=systemd"
KUBE_PROXY_MODE="ipvs"
EOF

- 设置为开机自启动即可,由于没有生成配置文件,集群初始化后自动启动:

6.3 查看 Kubernetes 安装所需镜像(可选)
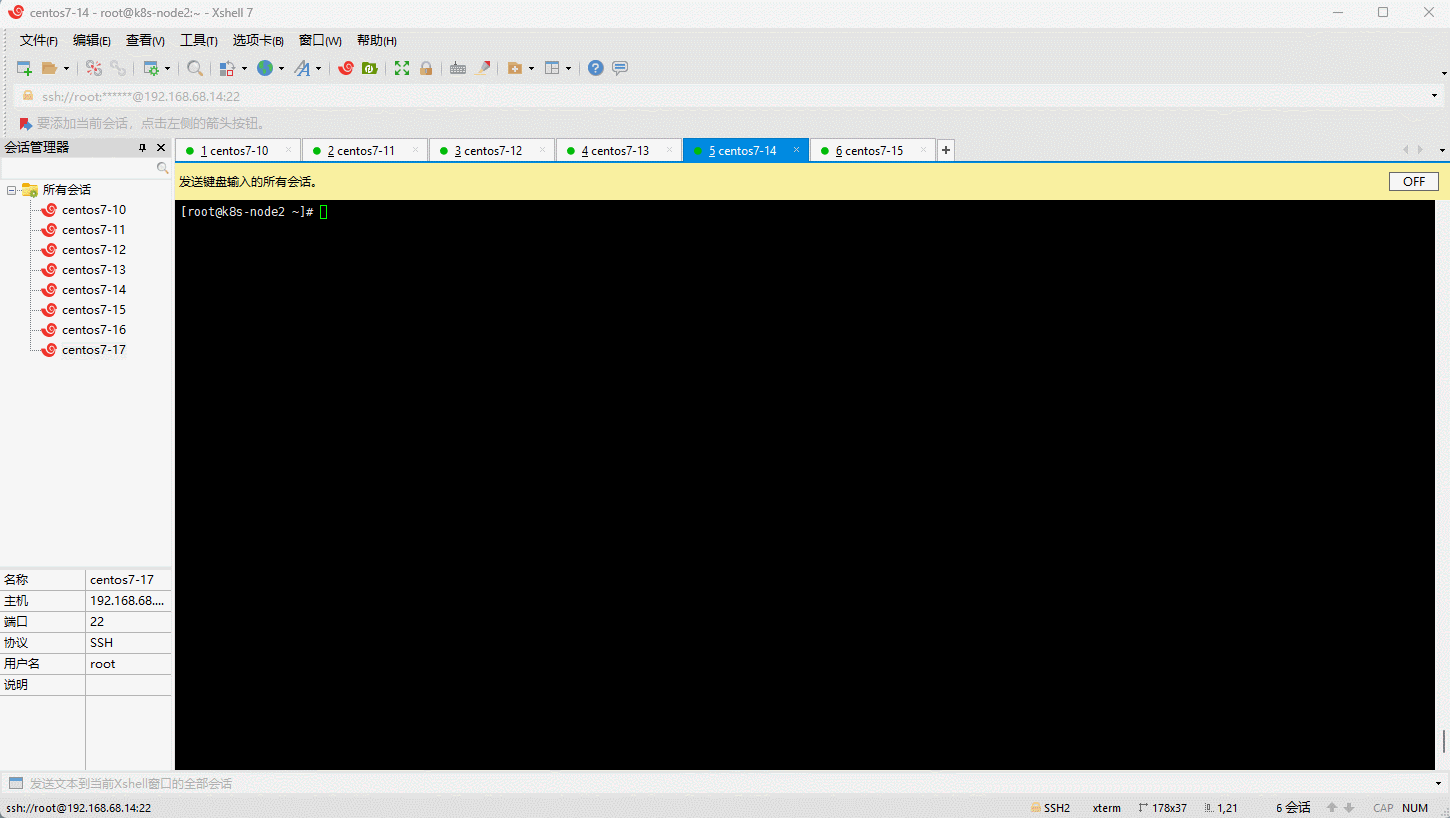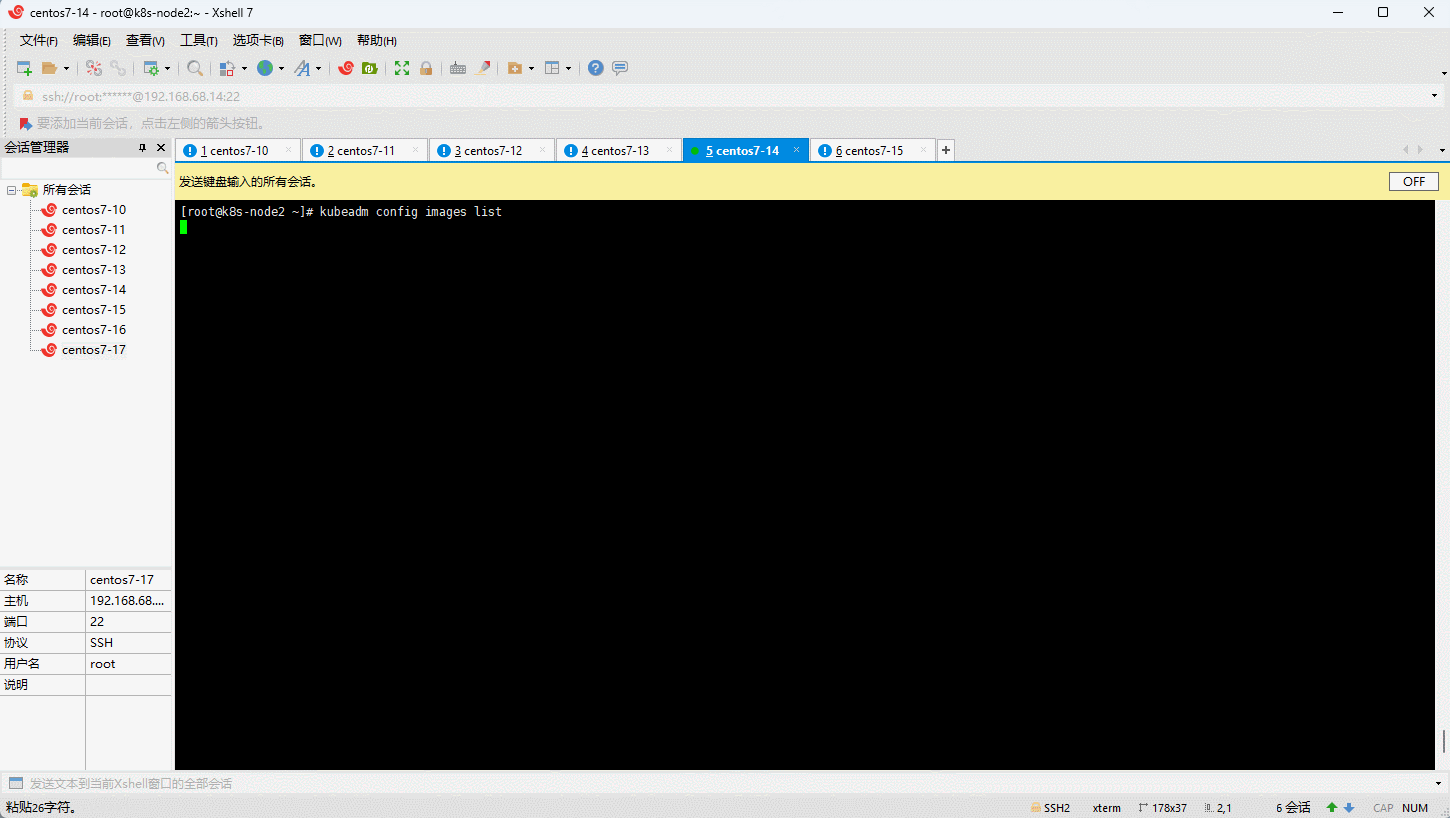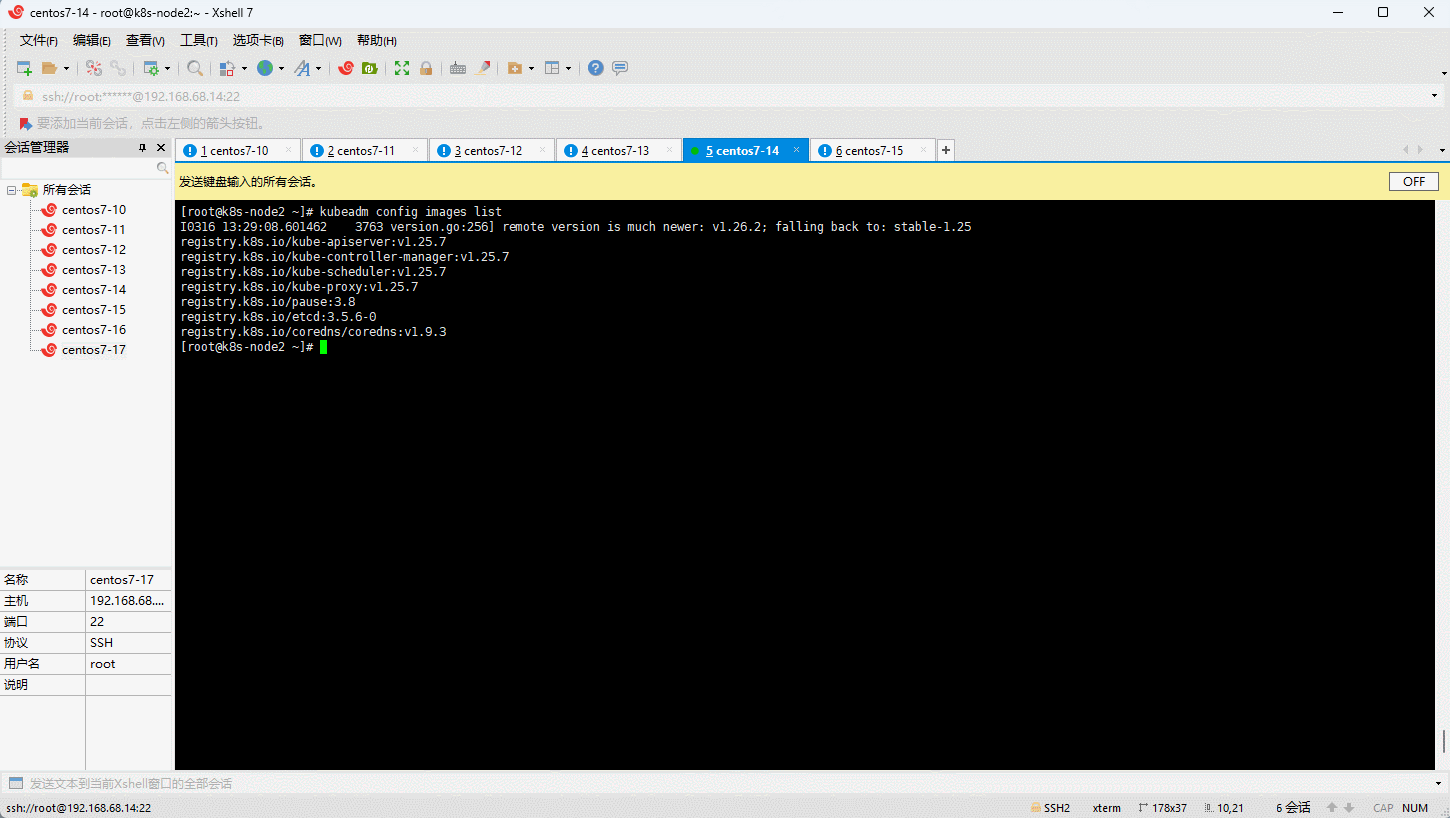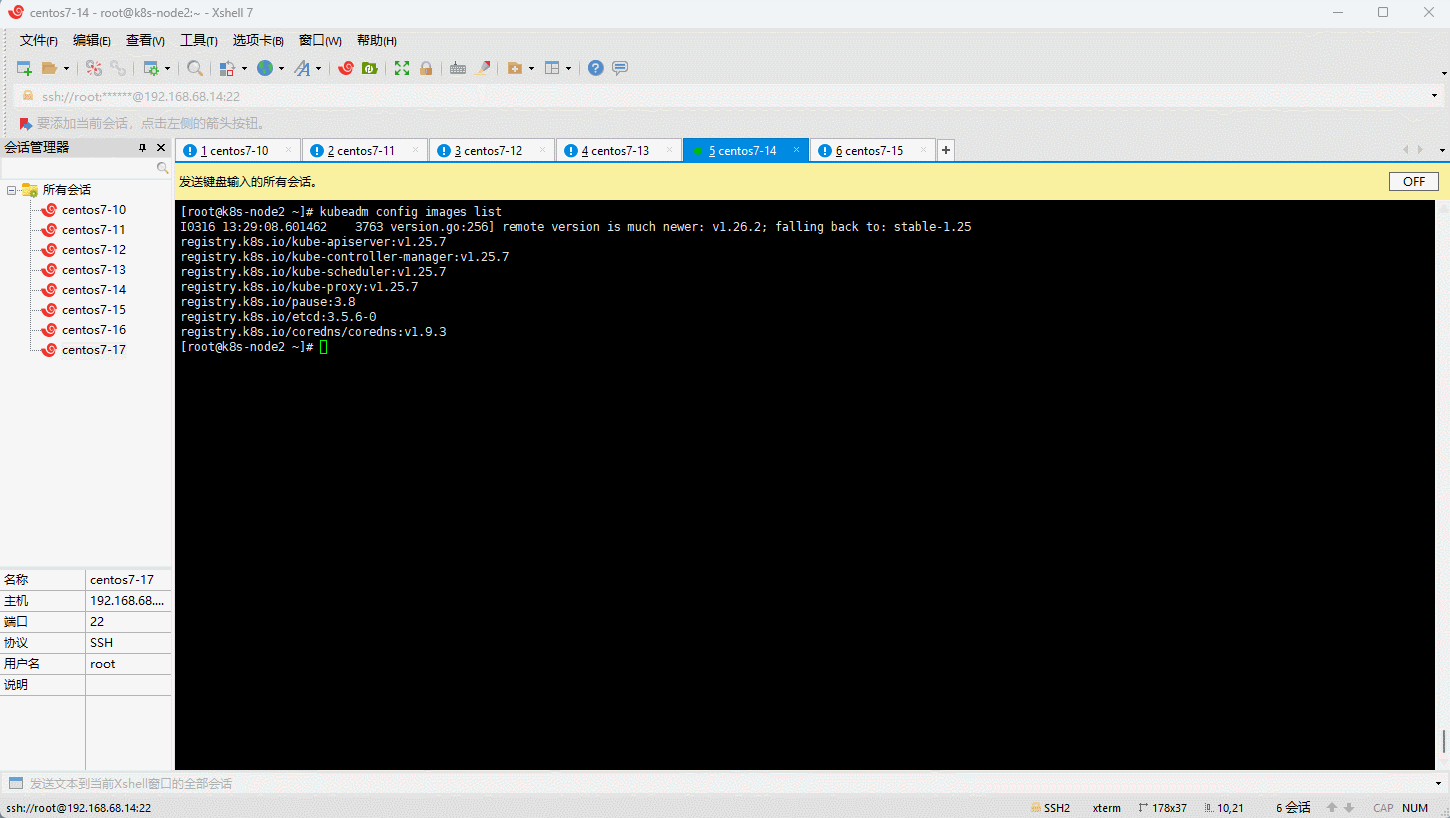
- 查看 Kubernetes 安装所需镜像:

6.4 安装 cri-dockerd
- Kubernetes 自 v1.24 移除了对 docker-shim 的支持,而 Docker Engine 默认又不支持 CRI 规范,因而二者将无法直接完成整合。为此,Mirantis 和 Docker 联合创建了cri-dockerd 项目,用于为 Docker Engine 提供一个能够支持到 CRI 规范的垫片,从而能够让 Kubernetes 基于 CRI 控制 Docker 。
- 所有节点(三主三从机器)均需要安装 cri-dockerd:
wget https://github.com/Mirantis/cri-dockerd/releases/download/v0.3.1/cri-dockerd-0.3.1-3.el7.x86_64.rpm
rpm -ivh cri-dockerd-0.3.1-3.el7.x86_64.rpm

6.5 配置 cri-dockerd
- 国内无法下载 Kubernetes 的镜像,所以需要修改 cri-dockerd ,以便使用国内镜像。
- 所有节点(三主三从机器)均需要配置 cri-dockerd :
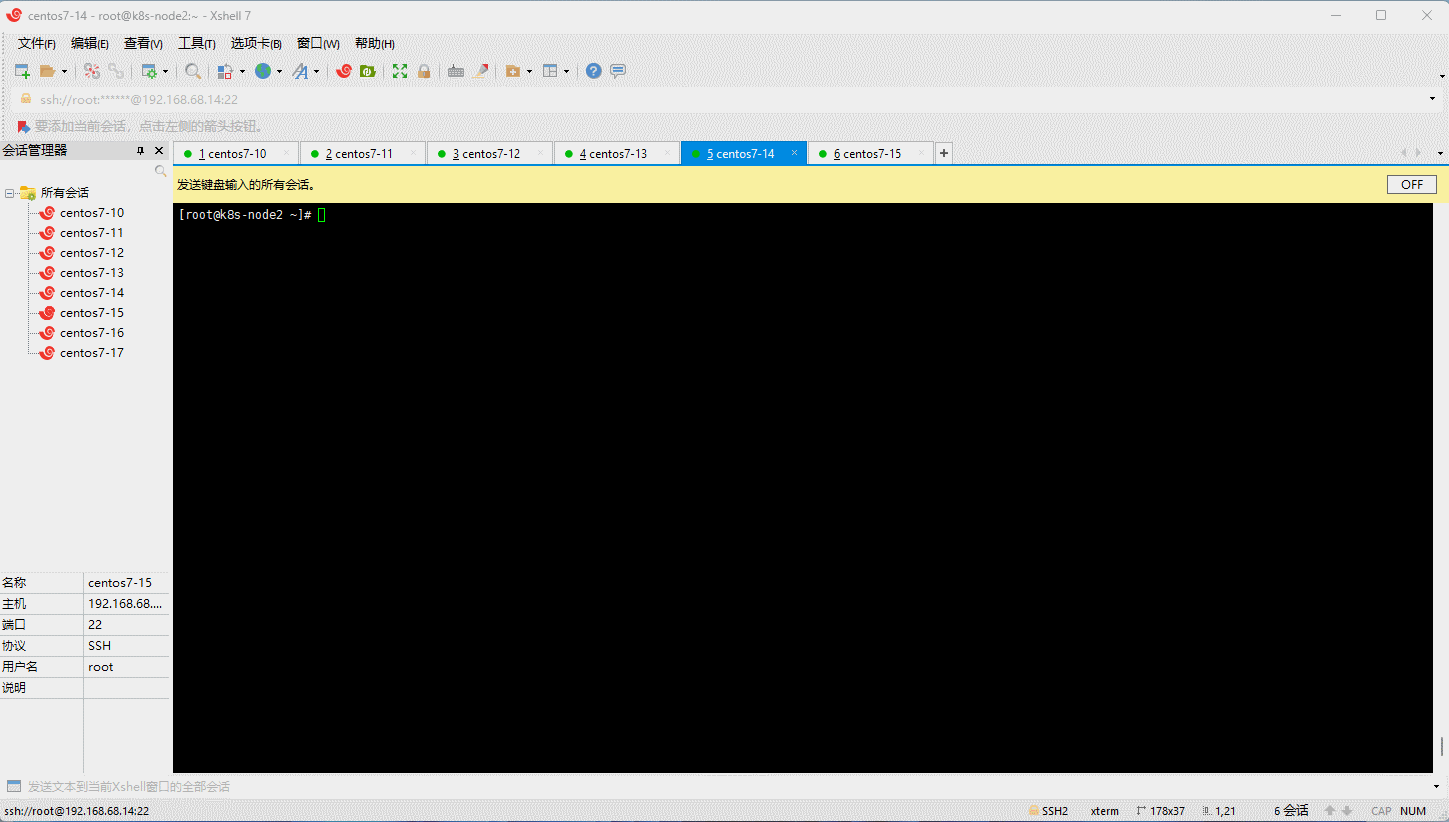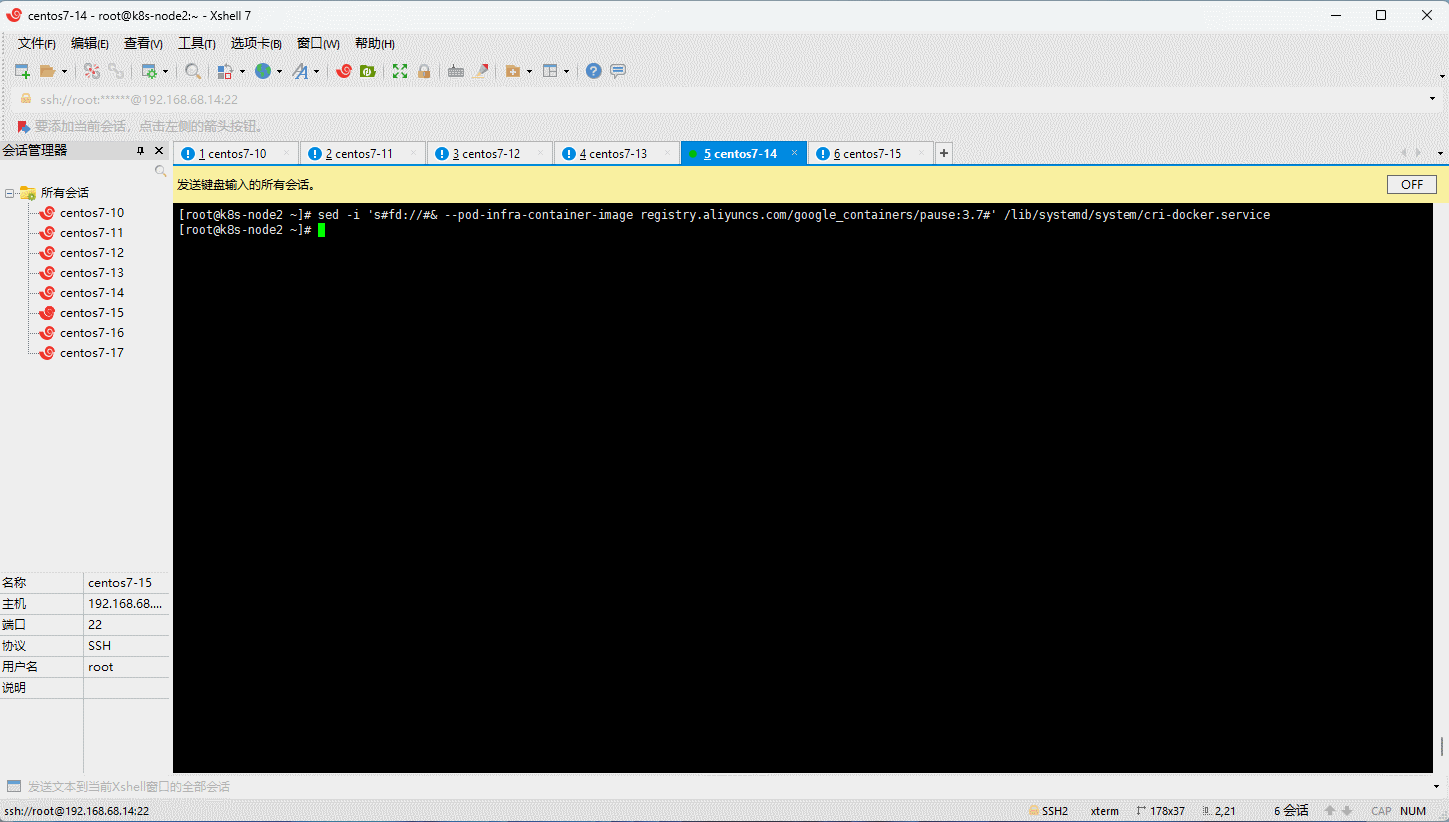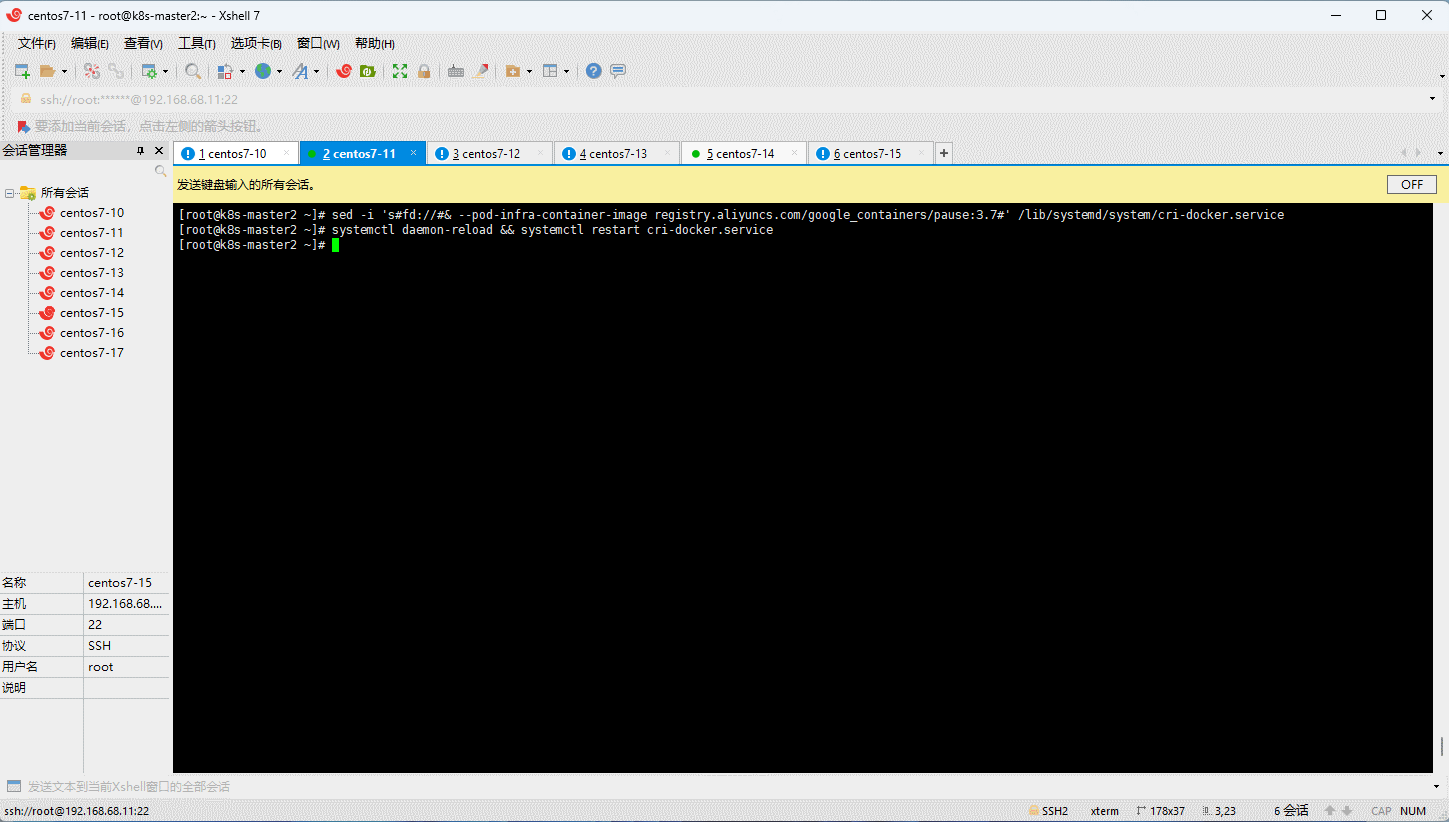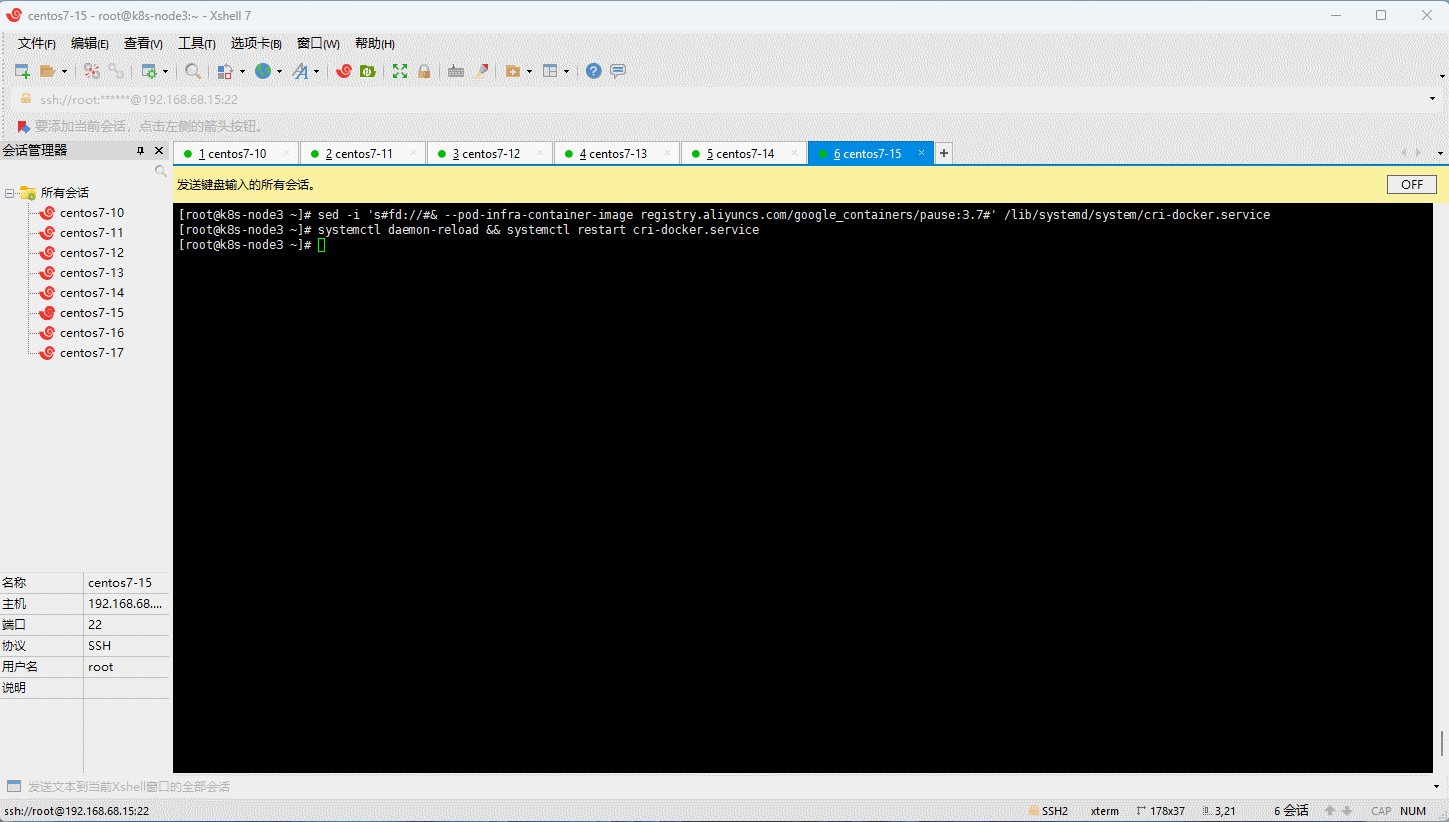
sed -i 's%^\(ExecStart=/usr/bin/cri-dockerd --container-runtime-endpoint fd://\)$%\1 --pod-infra-container-image registry.aliyuncs.com/google_containers/pause:3.7%' \
/lib/systemd/system/cri-docker.service

6.6 下载 Kubernetes 安装所需镜像(可选)
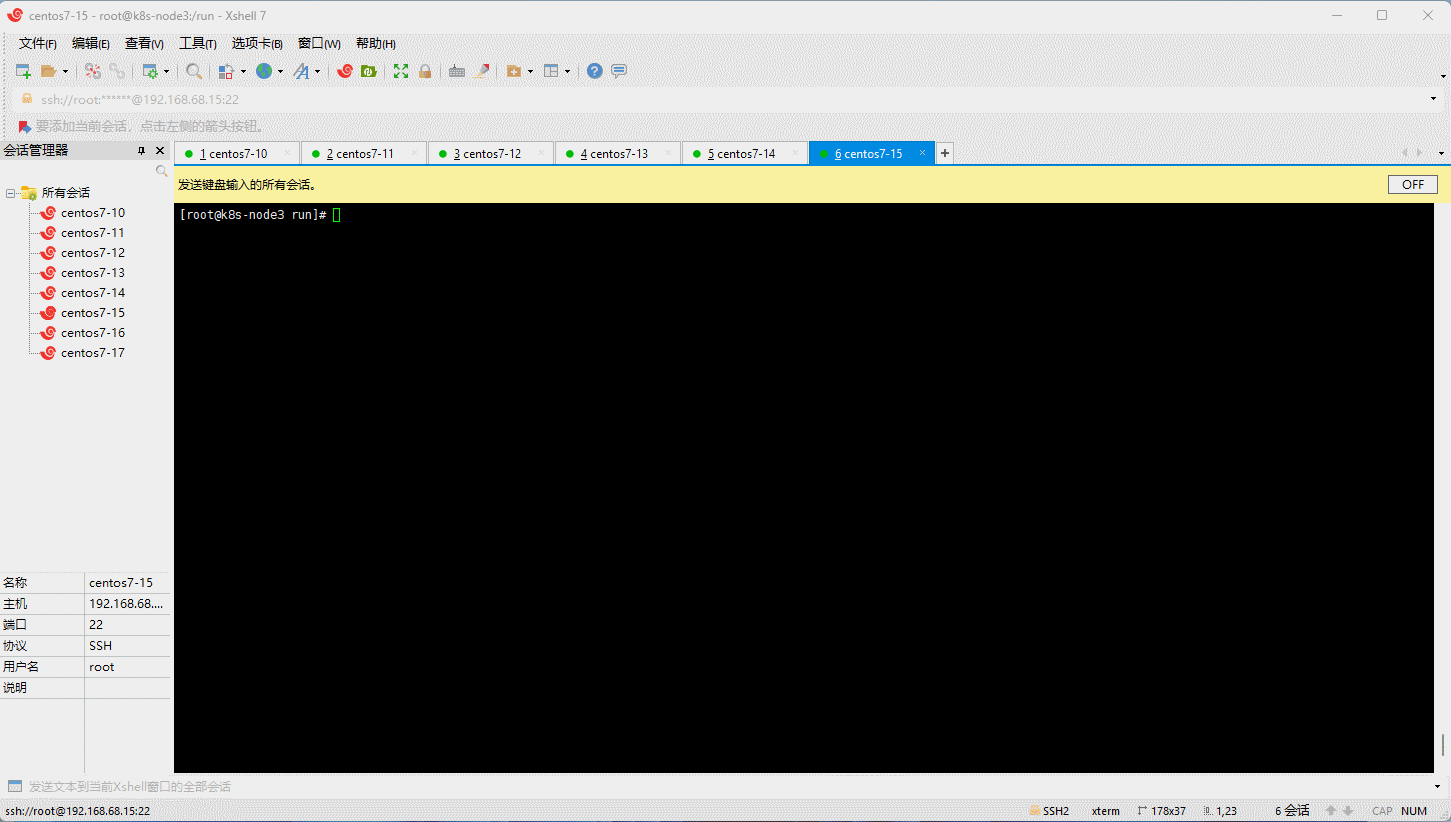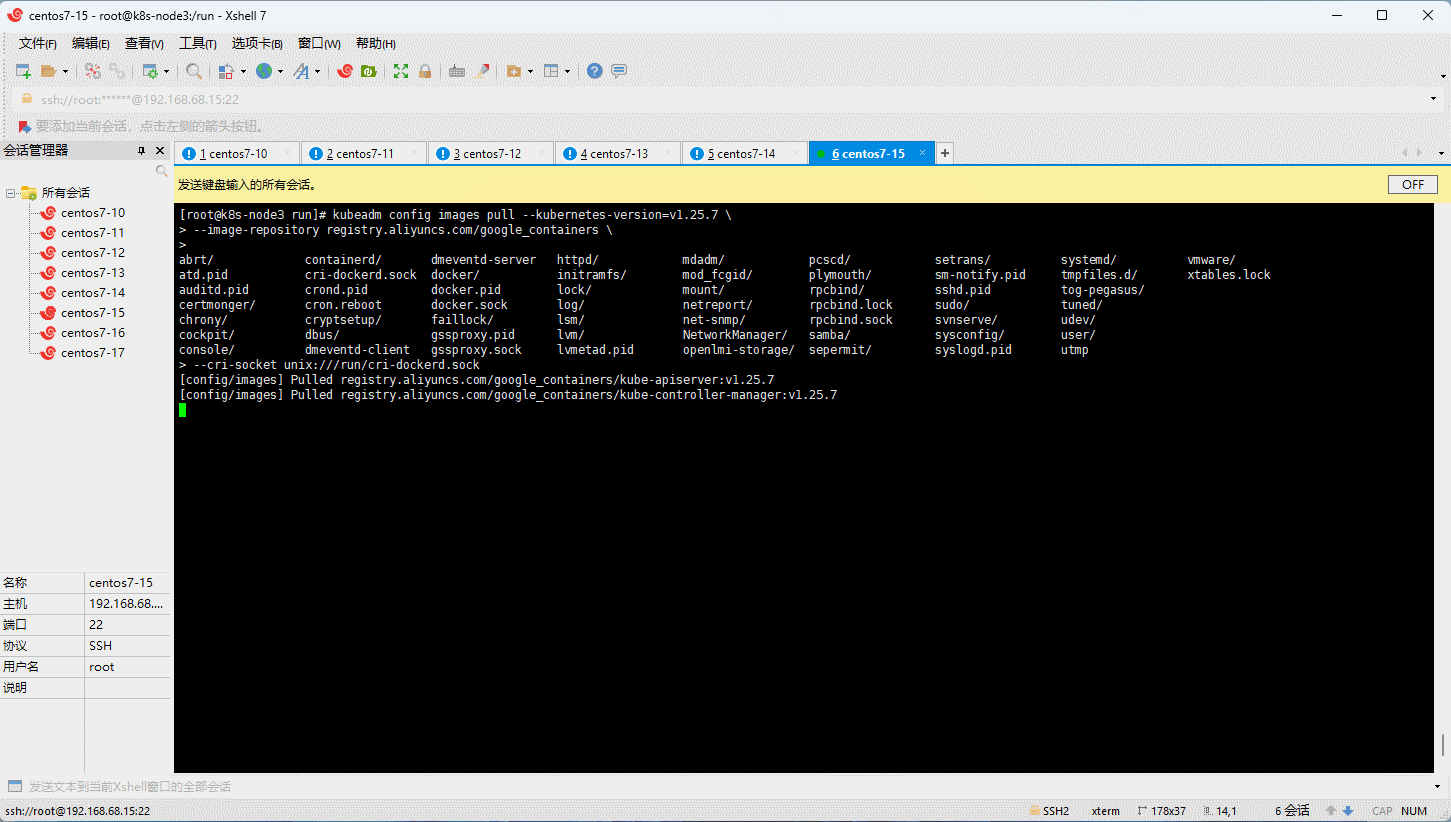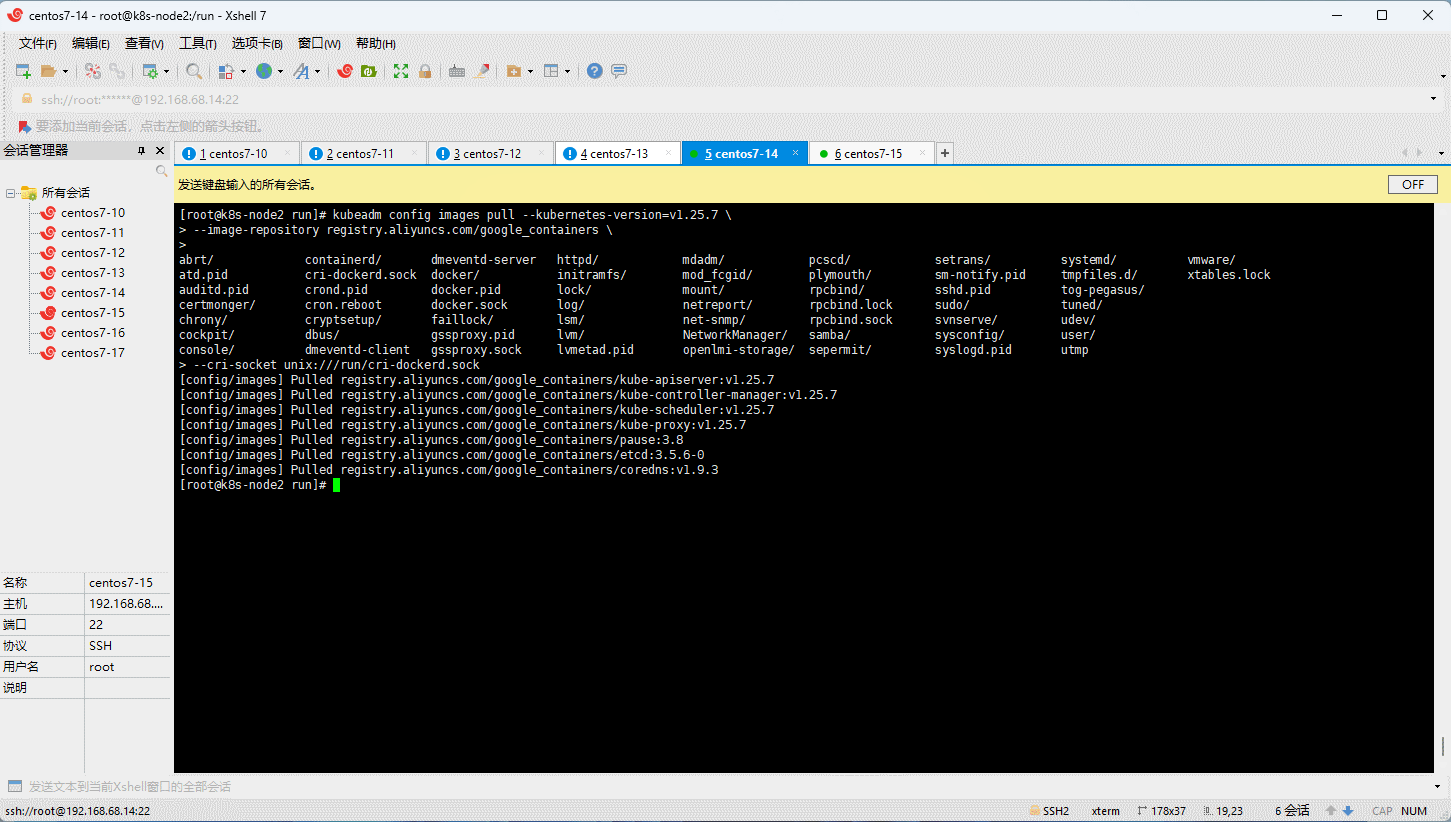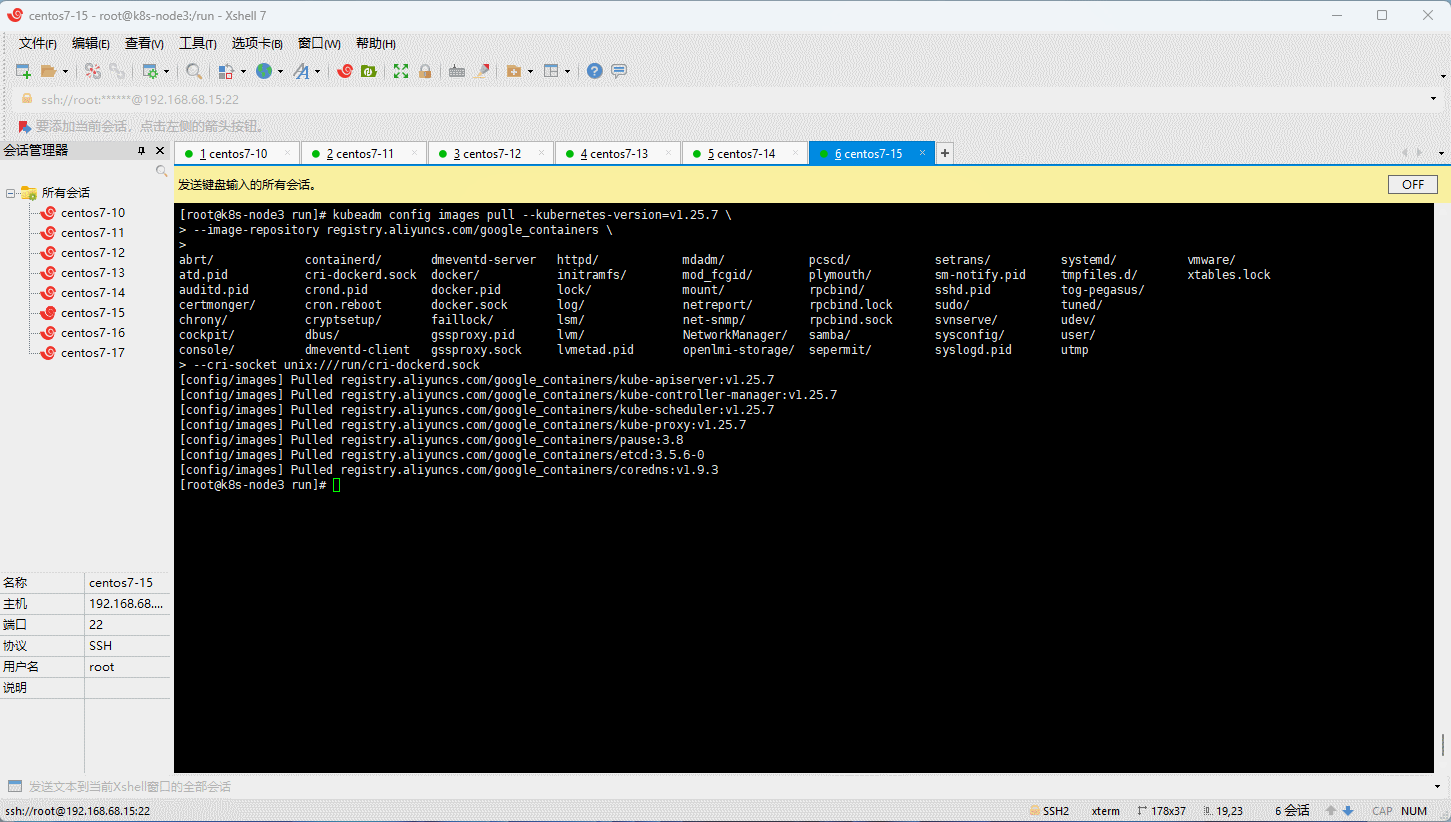
- 所有节点(三主三从机器)均需要执行如下的命令 :
kubeadm config images pull --kubernetes-version=v1.25.7 \
--image-repository registry.aliyuncs.com/google_containers \
--cri-socket unix:///run/cri-dockerd.sock

6.7 部署 Kubernetes 的第一个 Master 节点
- 在 k8s-master1 节点初始化 Kubernetes 集群:
kubeadm init \
--apiserver-advertise-address=192.168.68.10 \
--image-repository registry.aliyuncs.com/google_containers \
--control-plane-endpoint="192.168.68.20" \
--kubernetes-version=v1.25.7 \
--pod-network-cidr=10.244.0.0/16 \
--service-cidr=10.96.0.0/12 \
--token-ttl=0 \
--cri-socket unix:///run/cri-dockerd.sock \
--upload-certs
- 参数说明:
apiserver-advertise-address:API 服务器所公布的其正在监听的 IP 地址。如果未设置,则使用默认网络接口。apiserver 通告给其他组件的 IP 地址,一般应该为 Master 节点的用于集群内部通信的IP地 址,0.0.0.0 表示此节点上所有可用地址,非必选项。image-repository:镜像仓库地址。control-plane-endpoint:多主节点必选项,用于指定控制平面的固定访问地址,可以是 IP 地址或 DNS 域名,如果是单主节点则不需要该选项。kubernetes-version:Kubernetes 的版本。pod-network-cidr:Pod 网络的地址范围。service-cidr:Service 网络的地址范围。token-ttl:共享令牌的过期时间,默认为 24 小时;如果设置为 0 ,表示永不过期。当 token 过期后,如果希望再向集群中增加其他节点,可以使用kubeadm token create -- print-join-command来重新生成 token ,并加入集群。upload-certs:将控制平面证书上传到 kubeadm-certs Secret。cri-socket:在 v1.24 版本之后指定链接 cri 的 socket 文件路径。如果是 CRI 是 containerd,则使用--cri-socket unix:///run/containerd/containerd.sock。如果是CRI 是 docker,则使用--cri-socket unix:///var/run/cri-dockerd.sock。如果是 CRI 是 CRI-o,则使用--cri-socket unix:///var/run/crio/crio.sock。


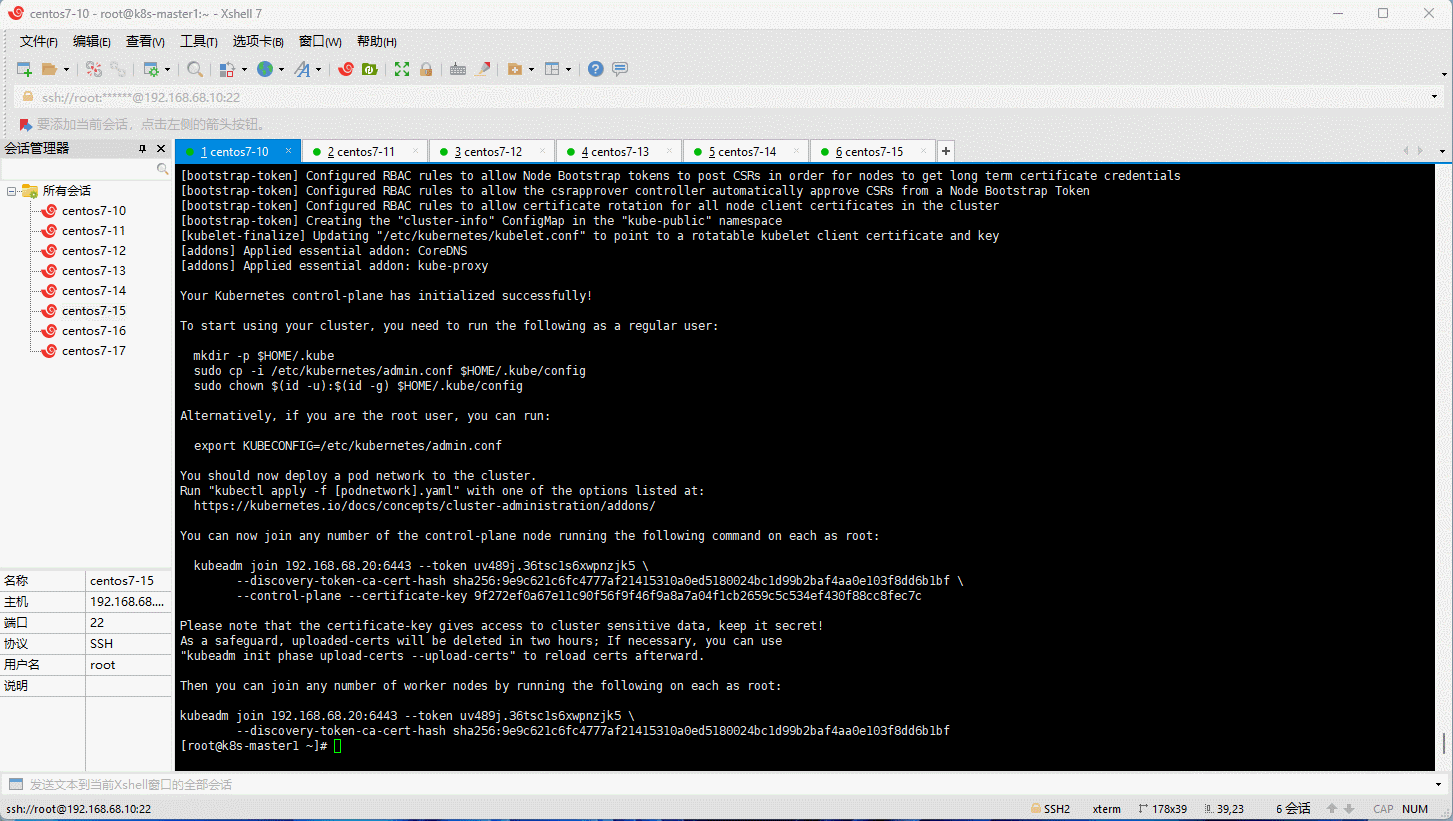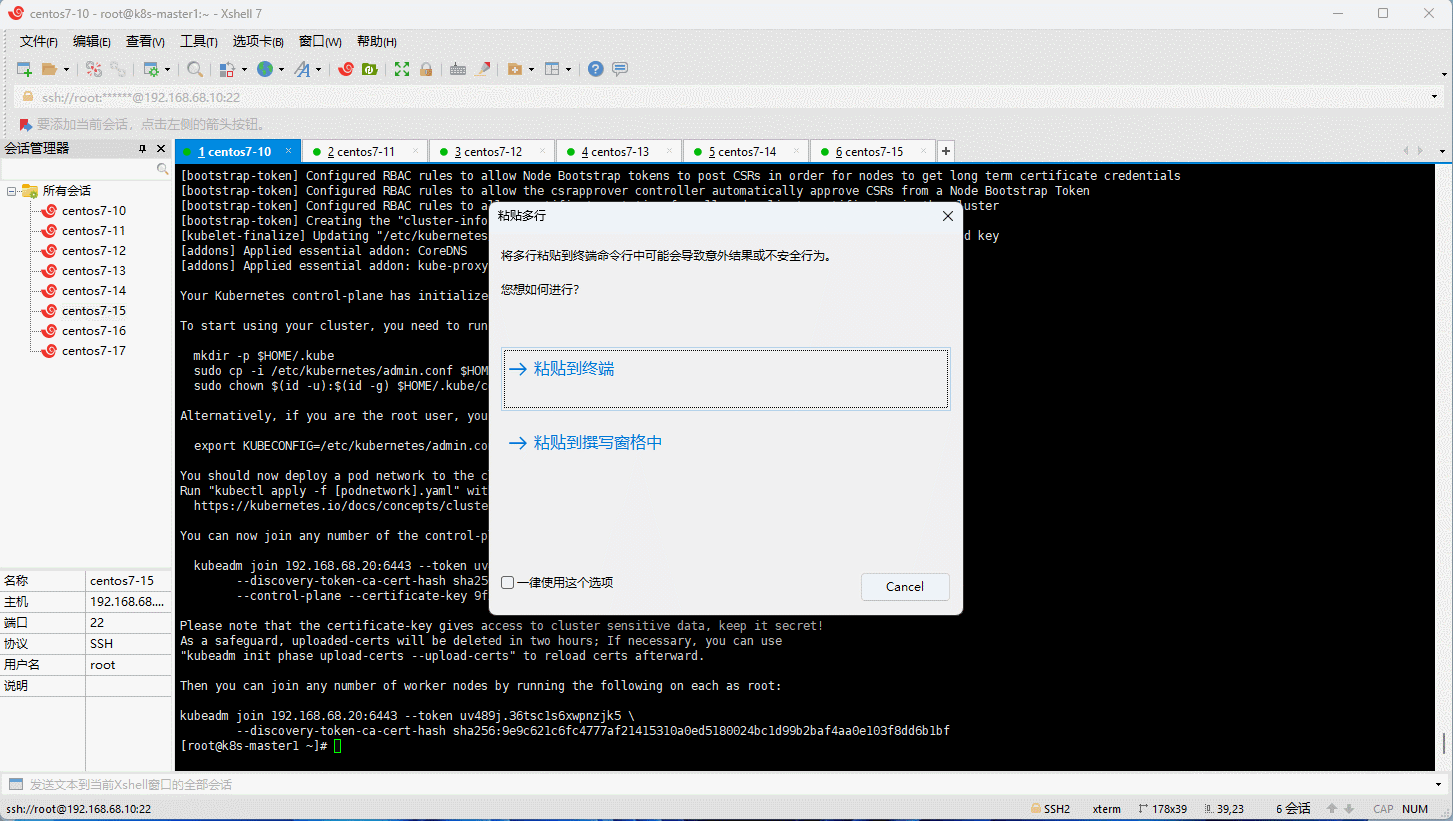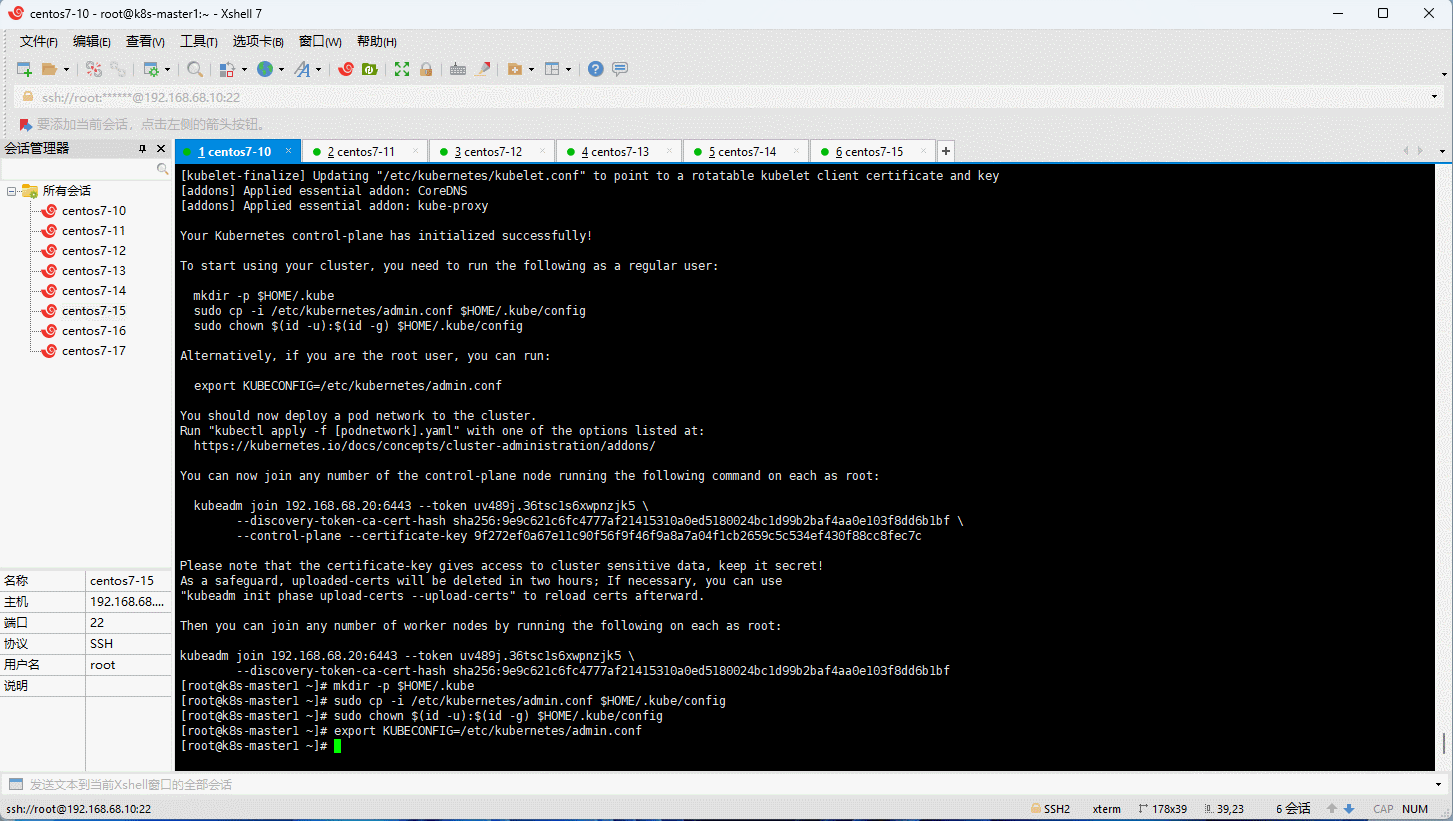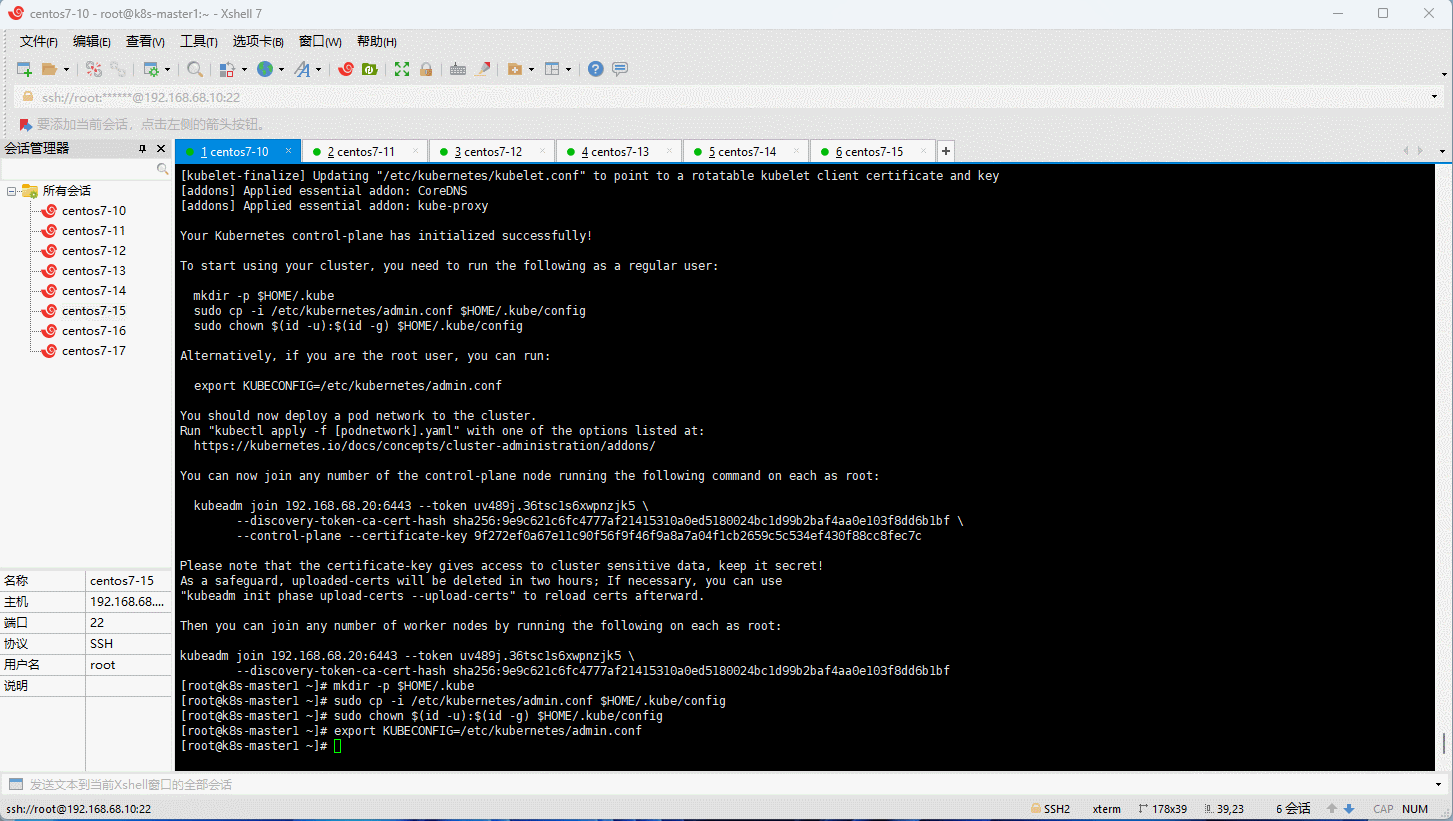
- 日志信息如下:
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of the control-plane node running the following command on each as root:
kubeadm join 192.168.68.20:6443 --token uv489j.36tsc1s6xwpnzjk5 \
--discovery-token-ca-cert-hash sha256:9e9c621c6fc4777af21415310a0ed5180024bc1d99b2baf4aa0e103f8dd6b1bf \
--control-plane --certificate-key 9f272ef0a67e11c90f56f9f46f9a8a7a04f1cb2659c5c534ef430f88cc8fec7c
Please note that the certificate-key gives access to cluster sensitive data, keep it secret!
As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use
"kubeadm init phase upload-certs --upload-certs" to reload certs afterward.
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.68.20:6443 --token uv489j.36tsc1s6xwpnzjk5 \
--discovery-token-ca-cert-hash sha256:9e9c621c6fc4777af21415310a0ed5180024bc1d99b2baf4aa0e103f8dd6b1bf
- 根据日志提示,在 k8s-maseter1 节点生成 kubectl 命令的授权文件:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
export KUBECONFIG=/etc/kubernetes/admin.conf

- 实现 kubectl 命令补全:
# 安装
yum -y install bash-completion
# 自动补全
echo 'source <(kubectl completion bash)' >>~/.bashrc
kubectl completion bash >/etc/bash_completion.d/kubectl
# 全局
kubectl completion bash | sudo tee /etc/bash_completion.d/kubectl > /dev/null
source /usr/share/bash-completion/bash_completion
- 如果是单节点集群,则可以执行下面的命令:
kubeadm init \
--apiserver-advertise-address=192.168.68.10 \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version=v1.25.7 \
--pod-network-cidr=10.244.0.0/16 \
--service-cidr=10.96.0.0/12 \
--token-ttl=0 \
--cri-socket unix:///run/cri-dockerd.sock \
- 如果想重新初始化,则可以执行下面的命令:
# 如果有工作节点,先在工作节点执行,再在 control 节点执行下面操作
kubeadm reset -f --cri-socket unix:///run/cri-dockerd.sock
rm -rf /etc/cni/net.d/ $HOME/.kube/config
reboot
6.8 将所有 node 节点加入到 Kubernetes 集群中
- 根据日志提示,将所有 node (k8s-node1、k8s-node2、k8s-node3)节点加入到 Kubernetes 集群中,但是需要添加
--cri-socket参数:
kubeadm join 192.168.68.20:6443 --token uv489j.36tsc1s6xwpnzjk5 \
--discovery-token-ca-cert-hash sha256:9e9c621c6fc4777af21415310a0ed5180024bc1d99b2baf4aa0e103f8dd6b1bf \
--cri-socket unix:///run/cri-dockerd.sock

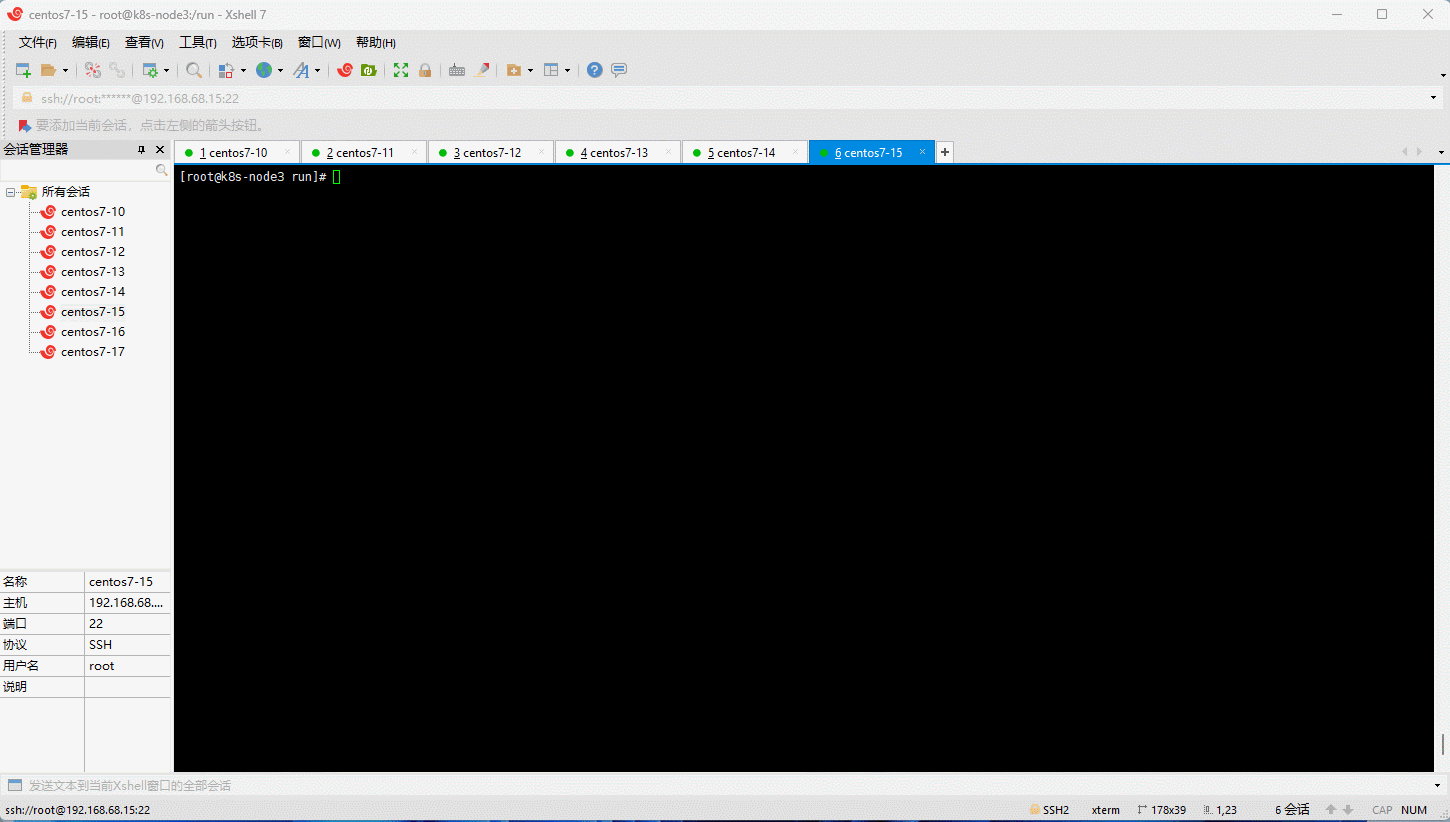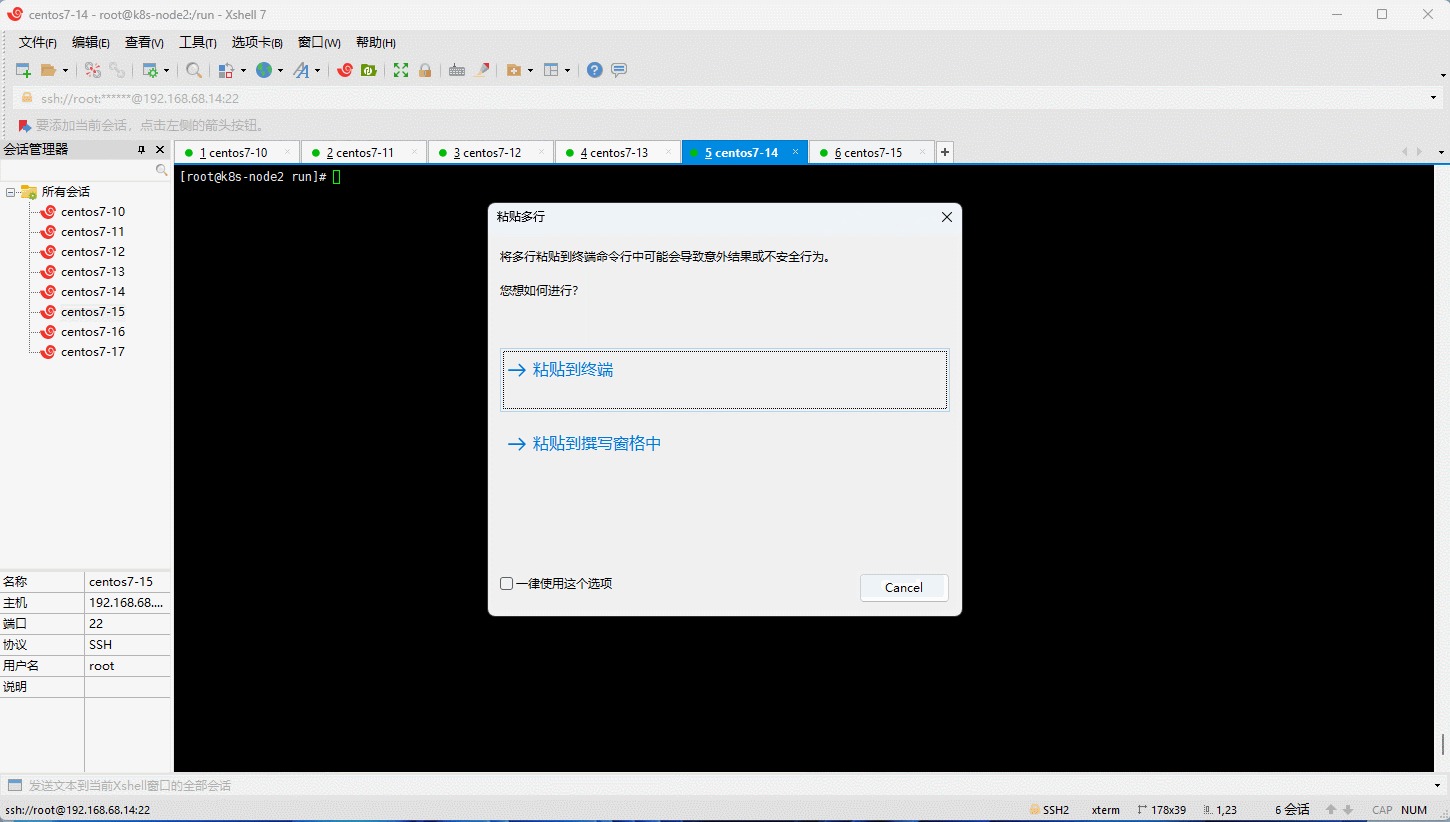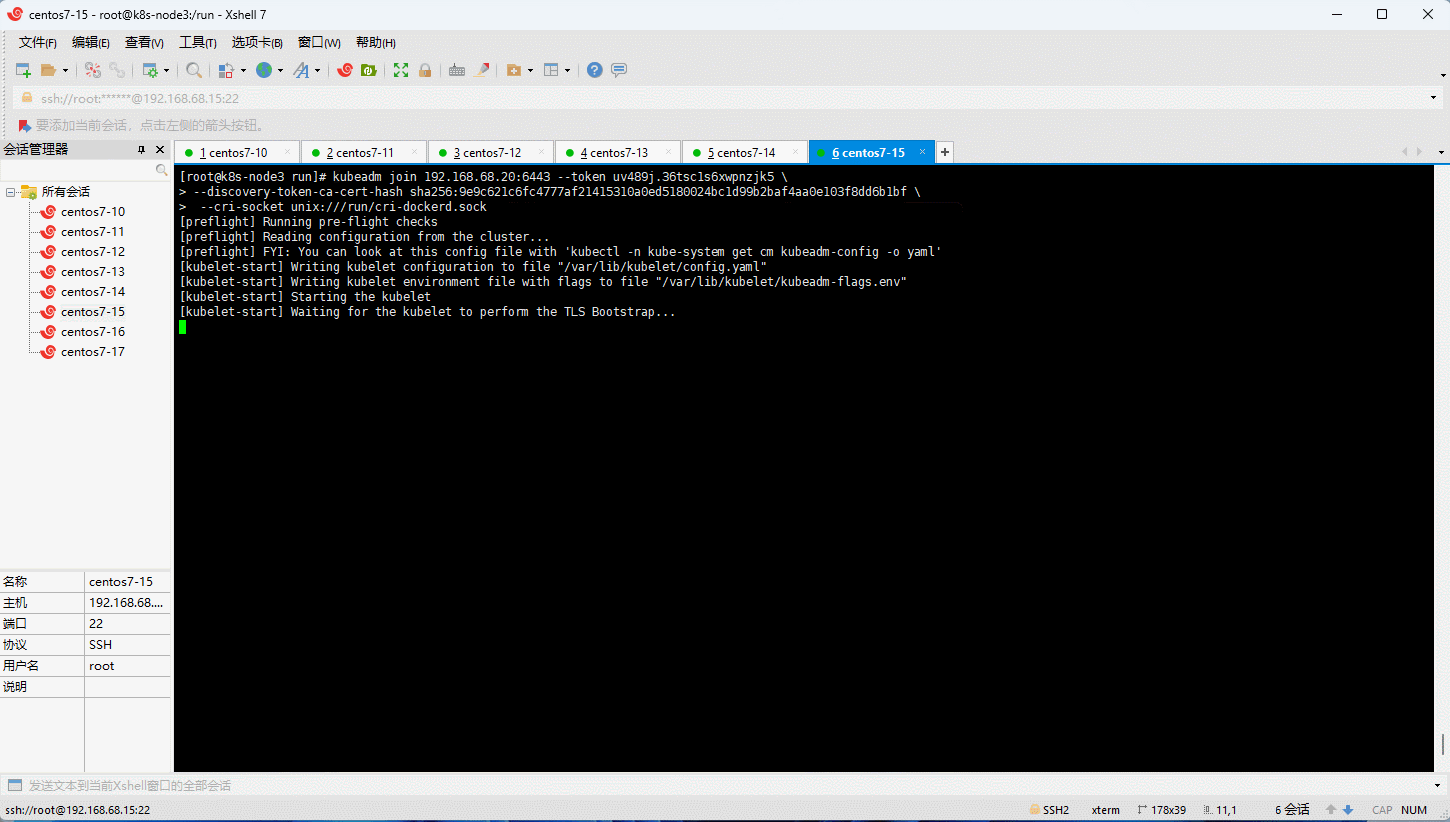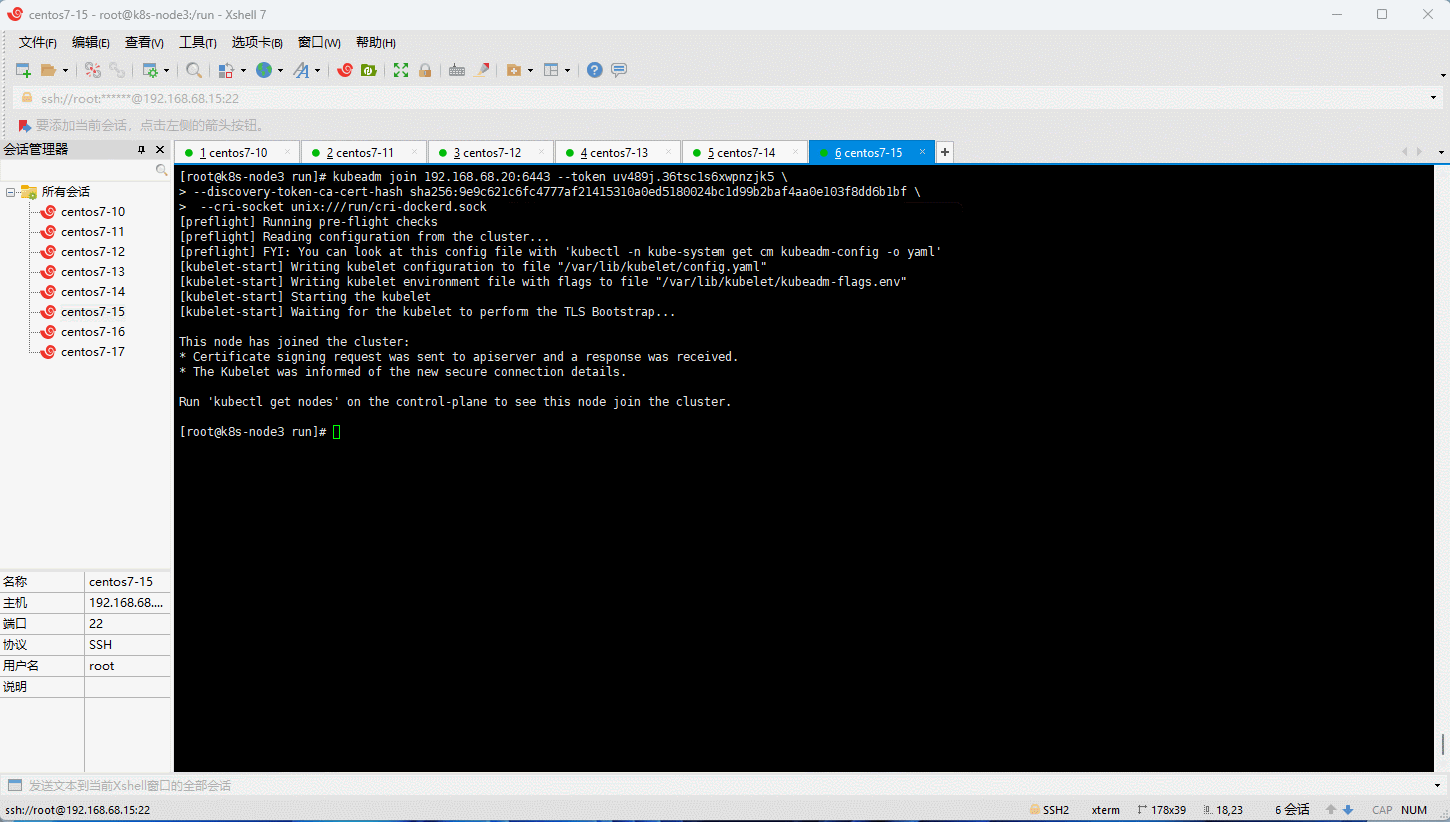
6.9 部署网络插件
- Kubernetes 支持多种网络插件,比如 flannel、calico、canal 等,任选一种即可,本次选择 calico ,只需要在 k8s-master1 节点安装即可。
注意:Kubernetes 和 Calico 的版本对应关系,在这里。

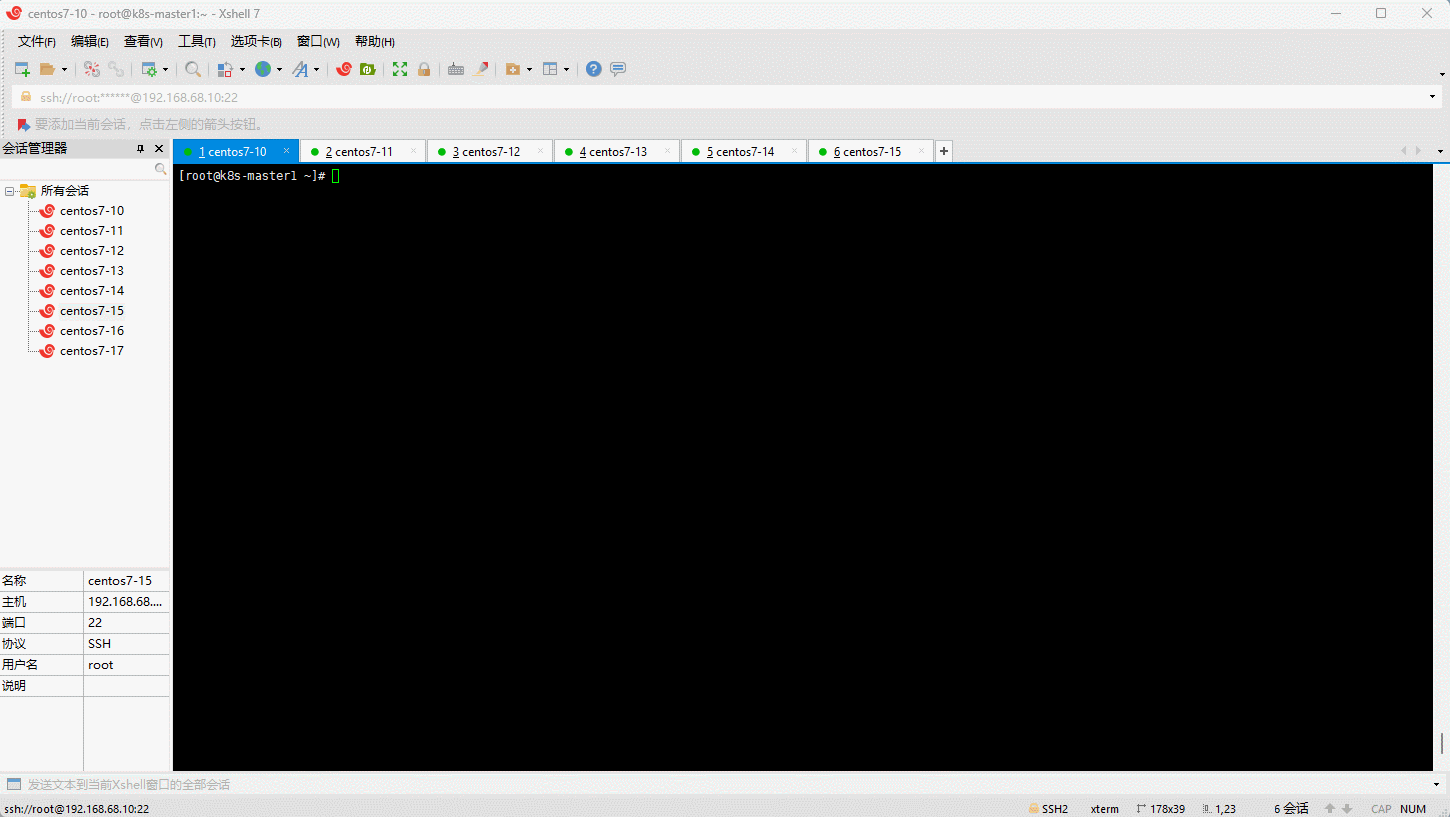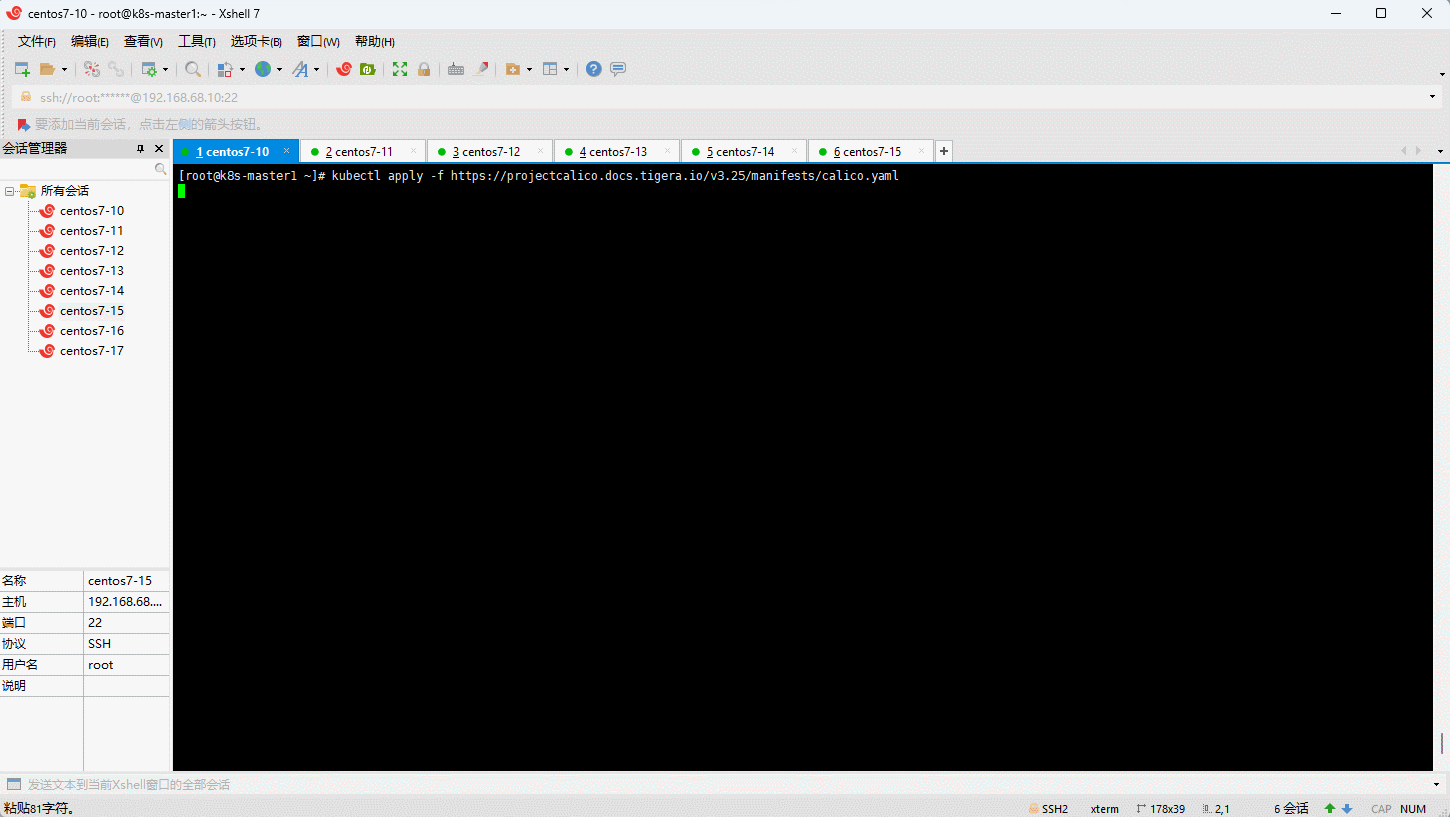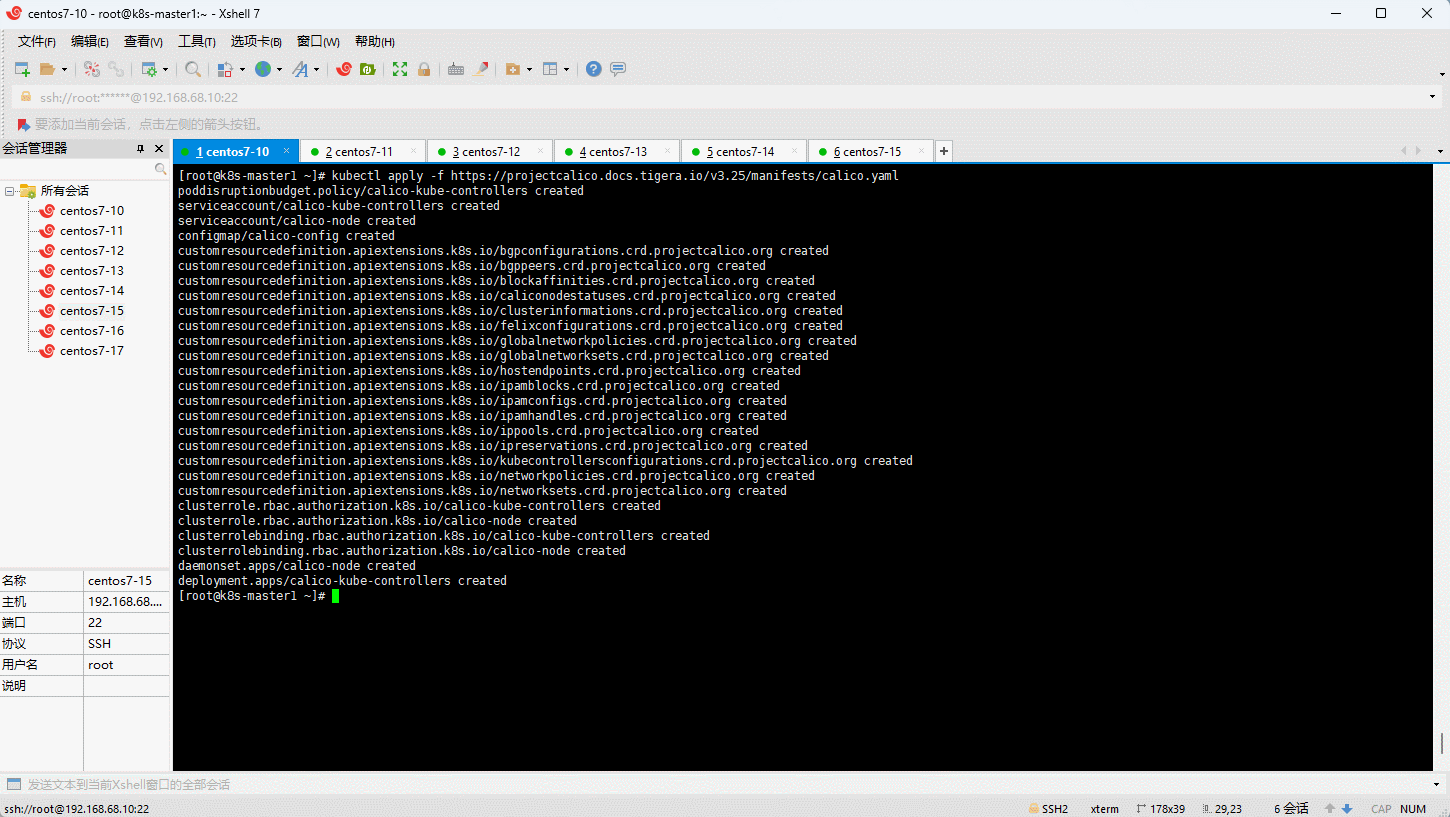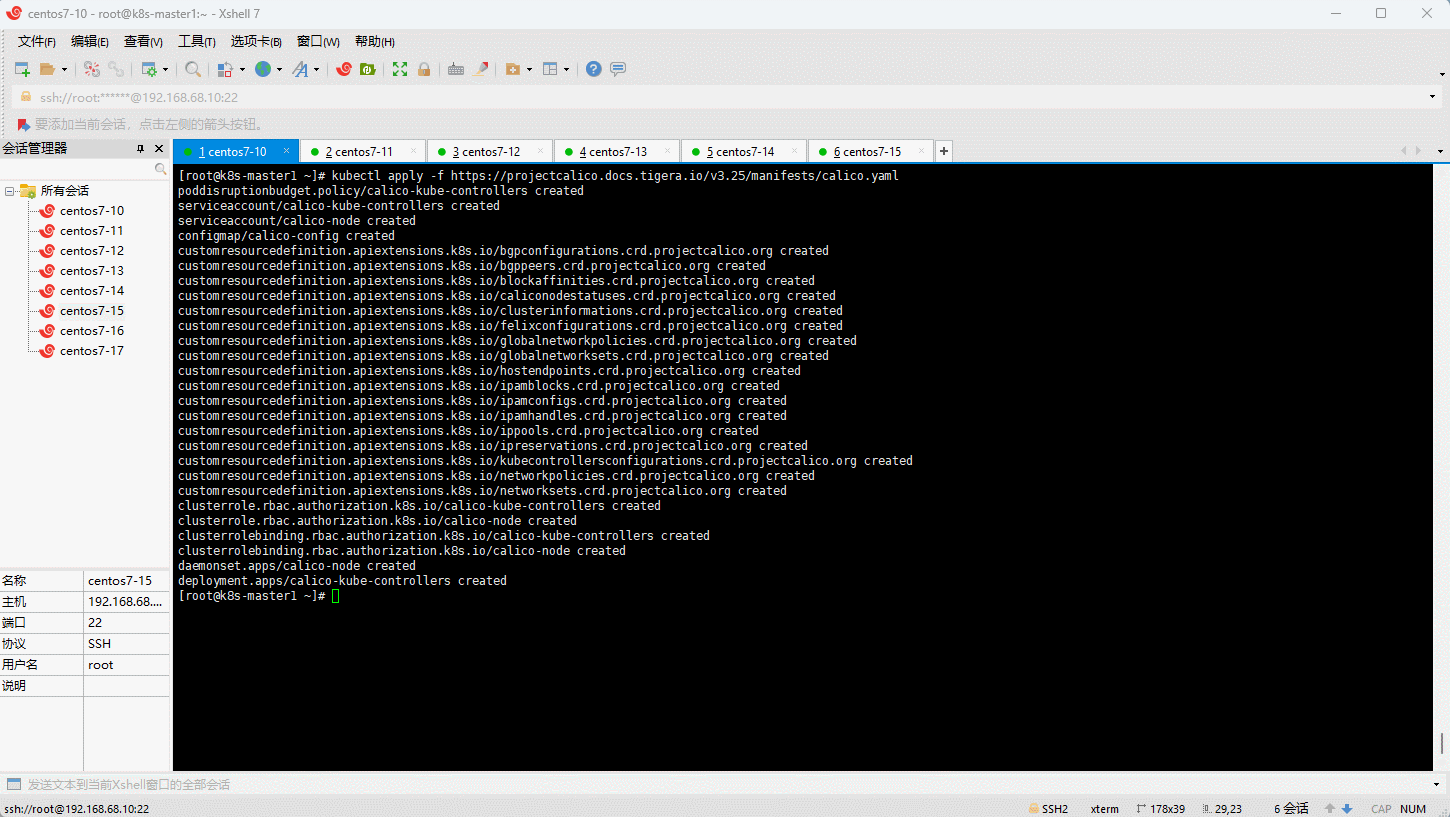
- 查看是否部署成功:

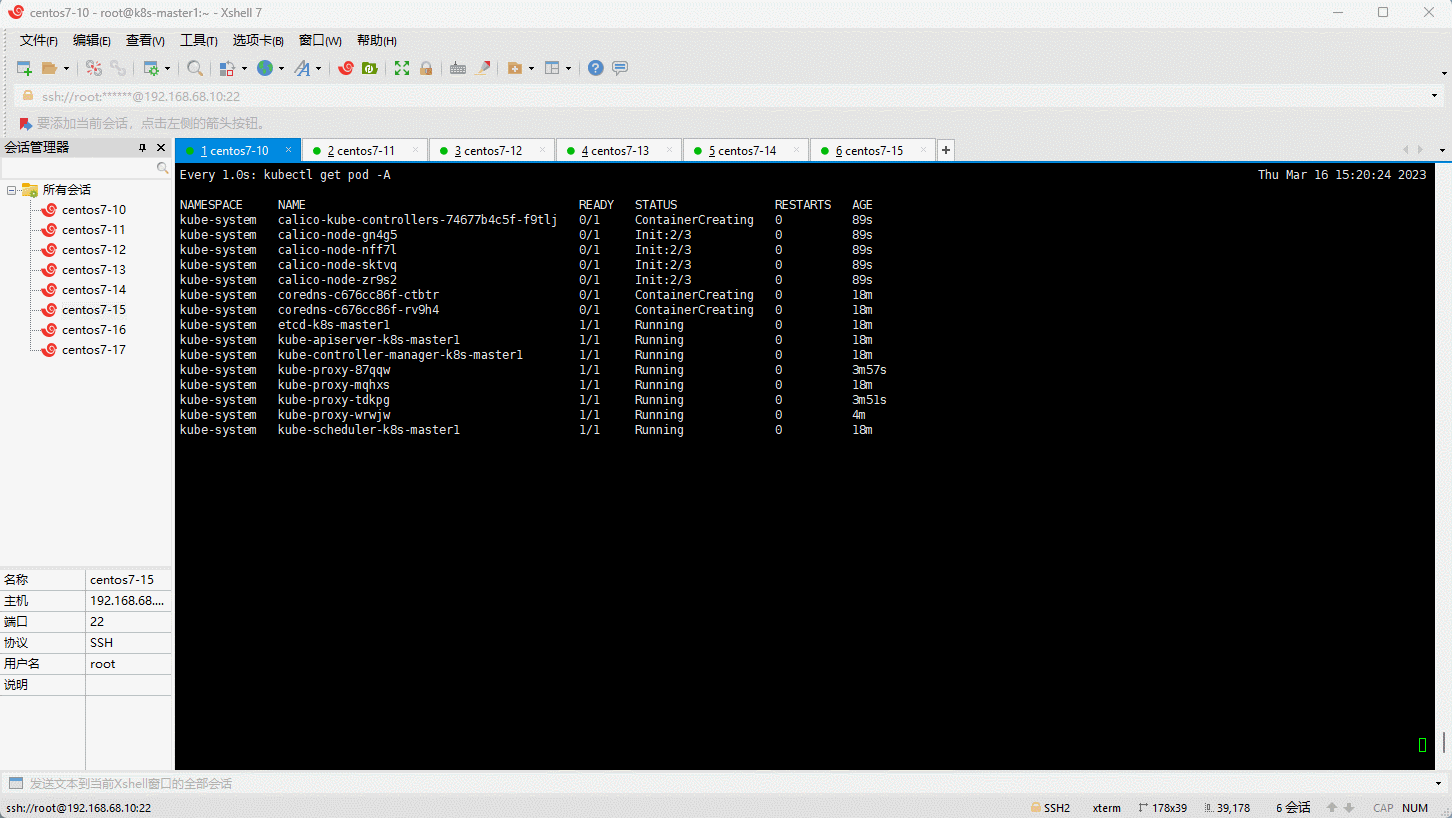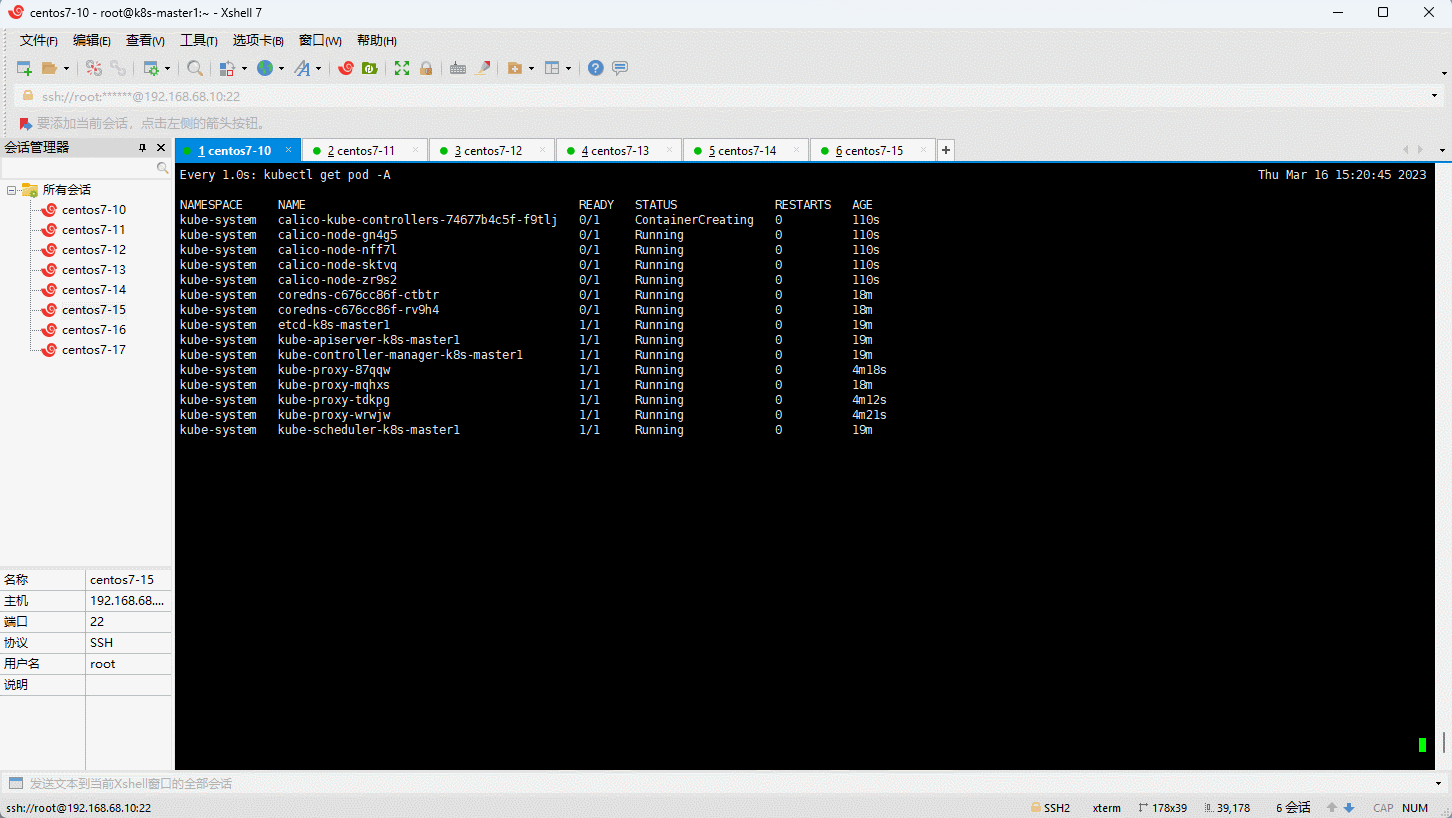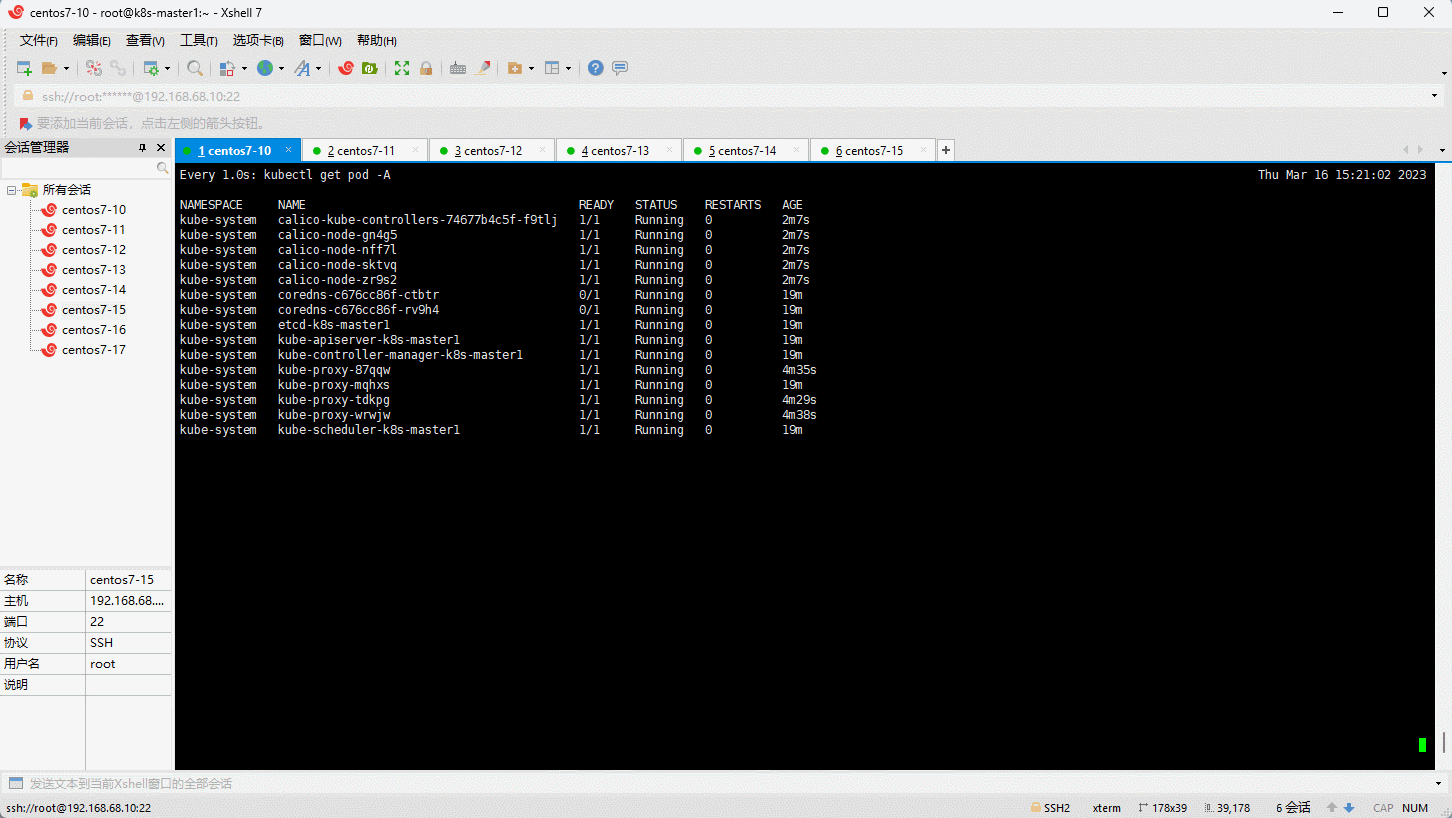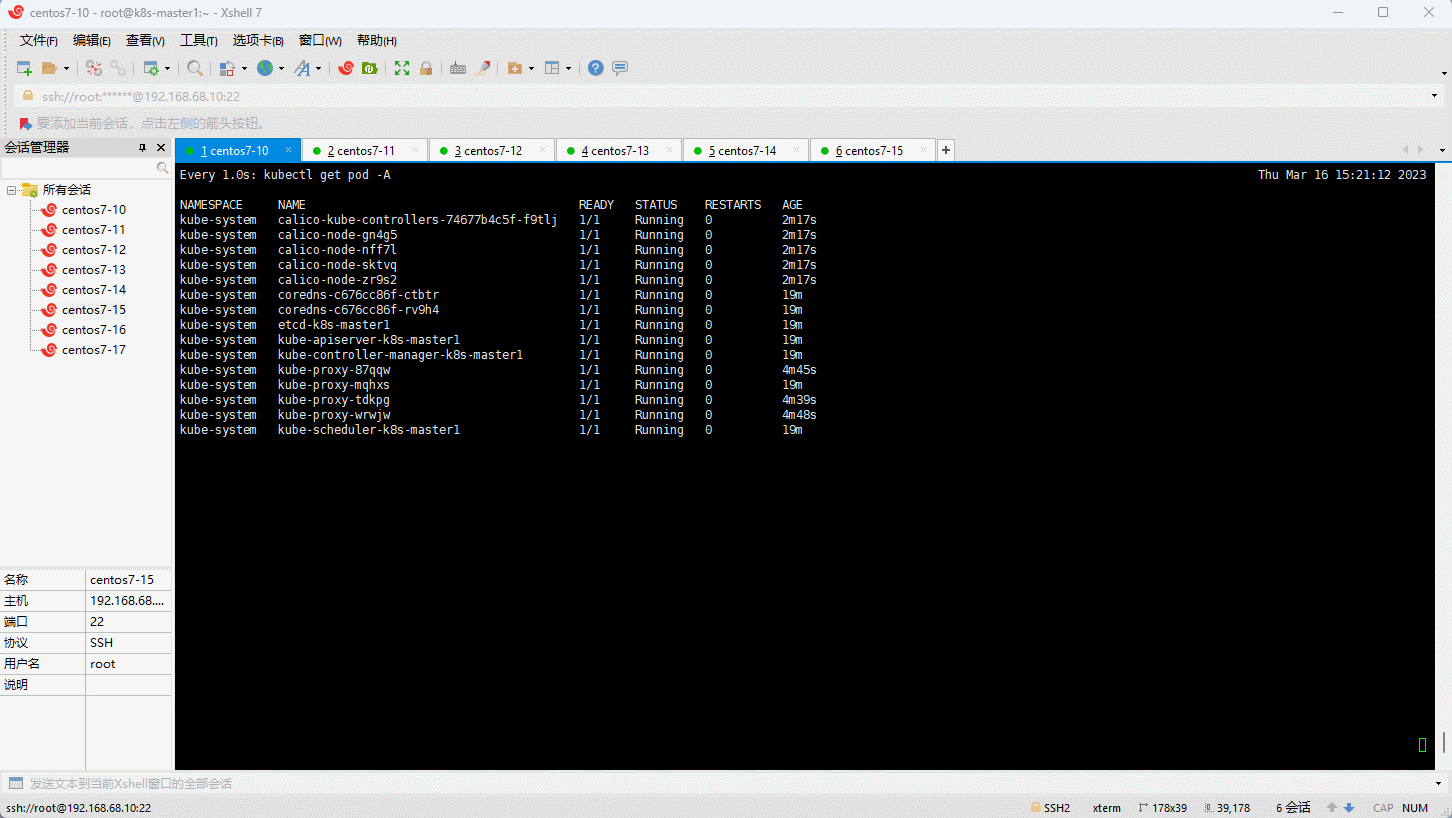
6.10 将其余的 master 节点加入到集群中
- 根据日志提示,将其余的 master 节点加入到集群中,组成高可用集群,但是需要添加
--cri-socket参数:
kubeadm join 192.168.68.20:6443 --token uv489j.36tsc1s6xwpnzjk5 \
--discovery-token-ca-cert-hash sha256:9e9c621c6fc4777af21415310a0ed5180024bc1d99b2baf4aa0e103f8dd6b1bf \
--control-plane --certificate-key 9f272ef0a67e11c90f56f9f46f9a8a7a04f1cb2659c5c534ef430f88cc8fec7c \
--cri-socket unix:///run/cri-dockerd.sock

- 日志信息如下:
* Certificate signing request was sent to apiserver and approval was received.
* The Kubelet was informed of the new secure connection details.
* Control plane label and taint were applied to the new node.
* The Kubernetes control plane instances scaled up.
* A new etcd member was added to the local/stacked etcd cluster.
To start administering your cluster from this node, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Run 'kubectl get nodes' to see this node join the cluster.
- 根据日志提示操作即可:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config

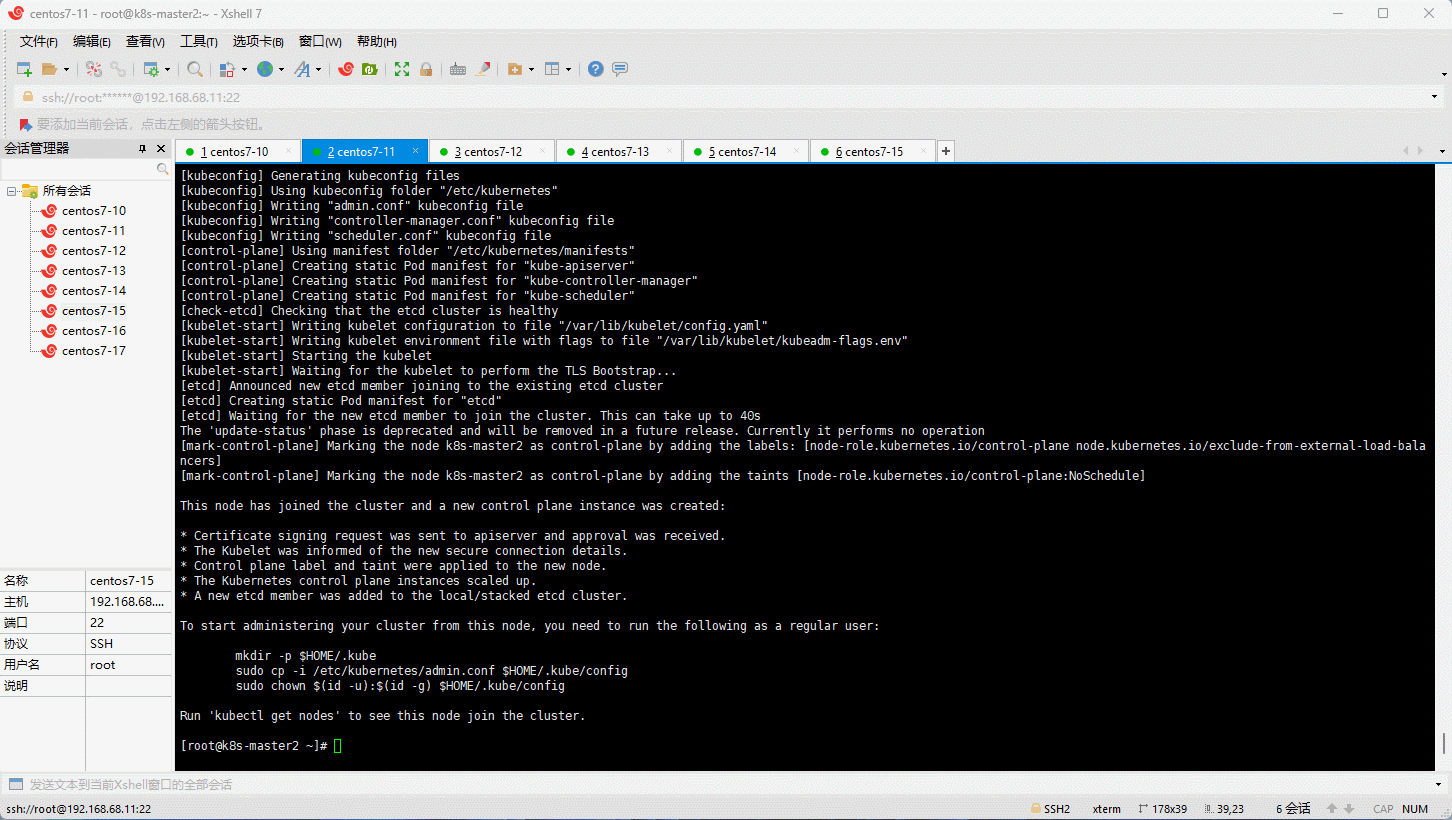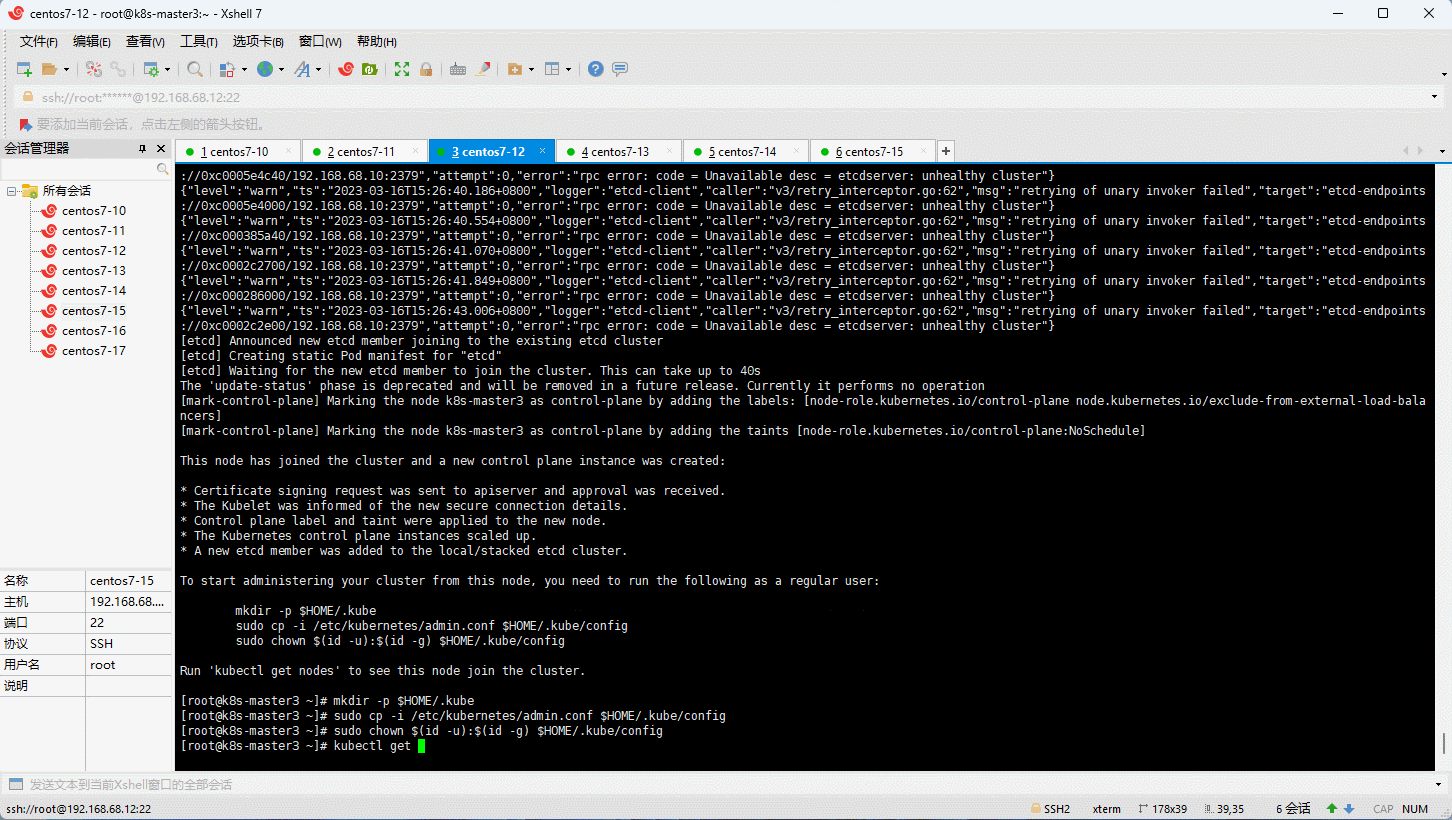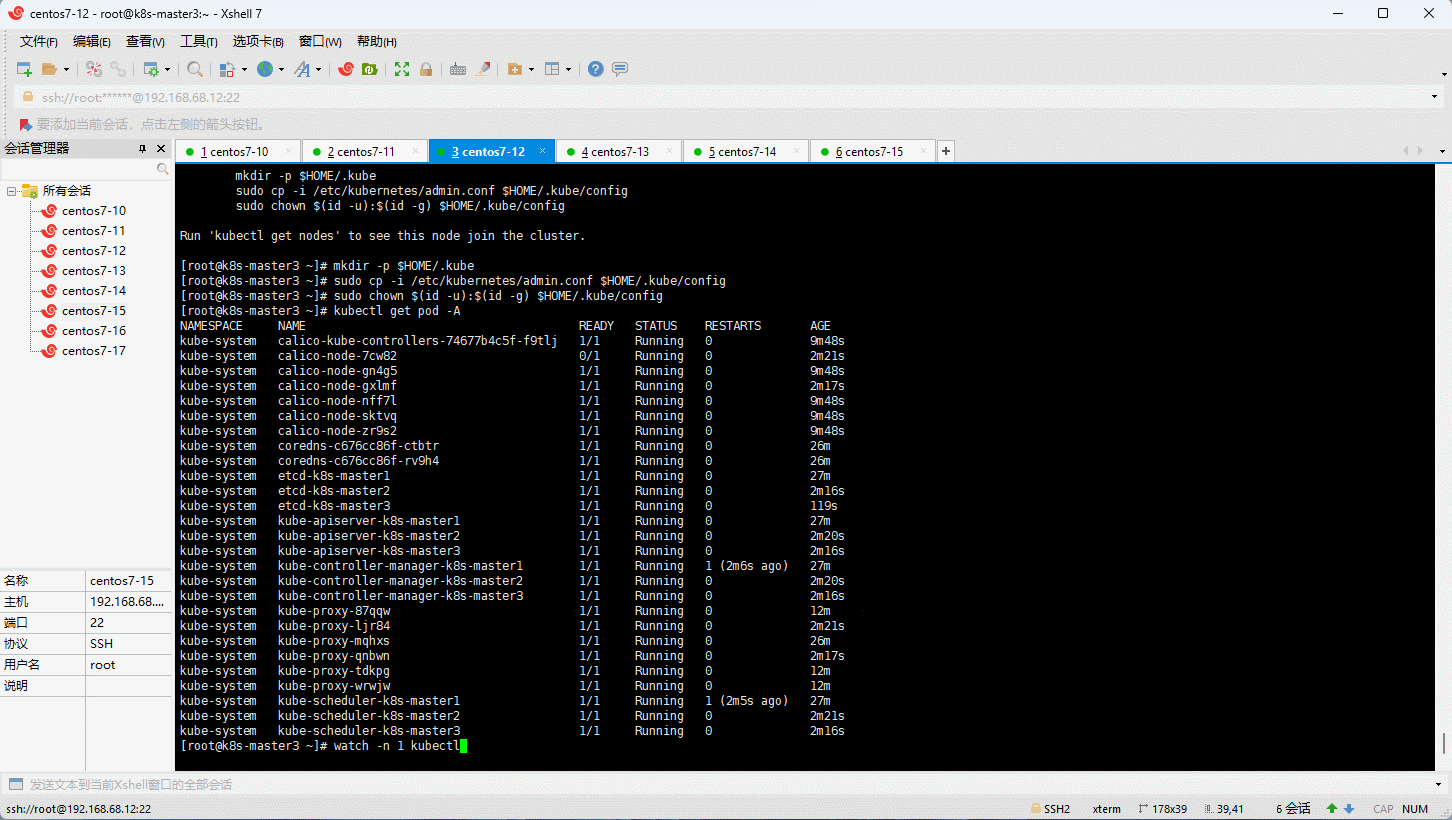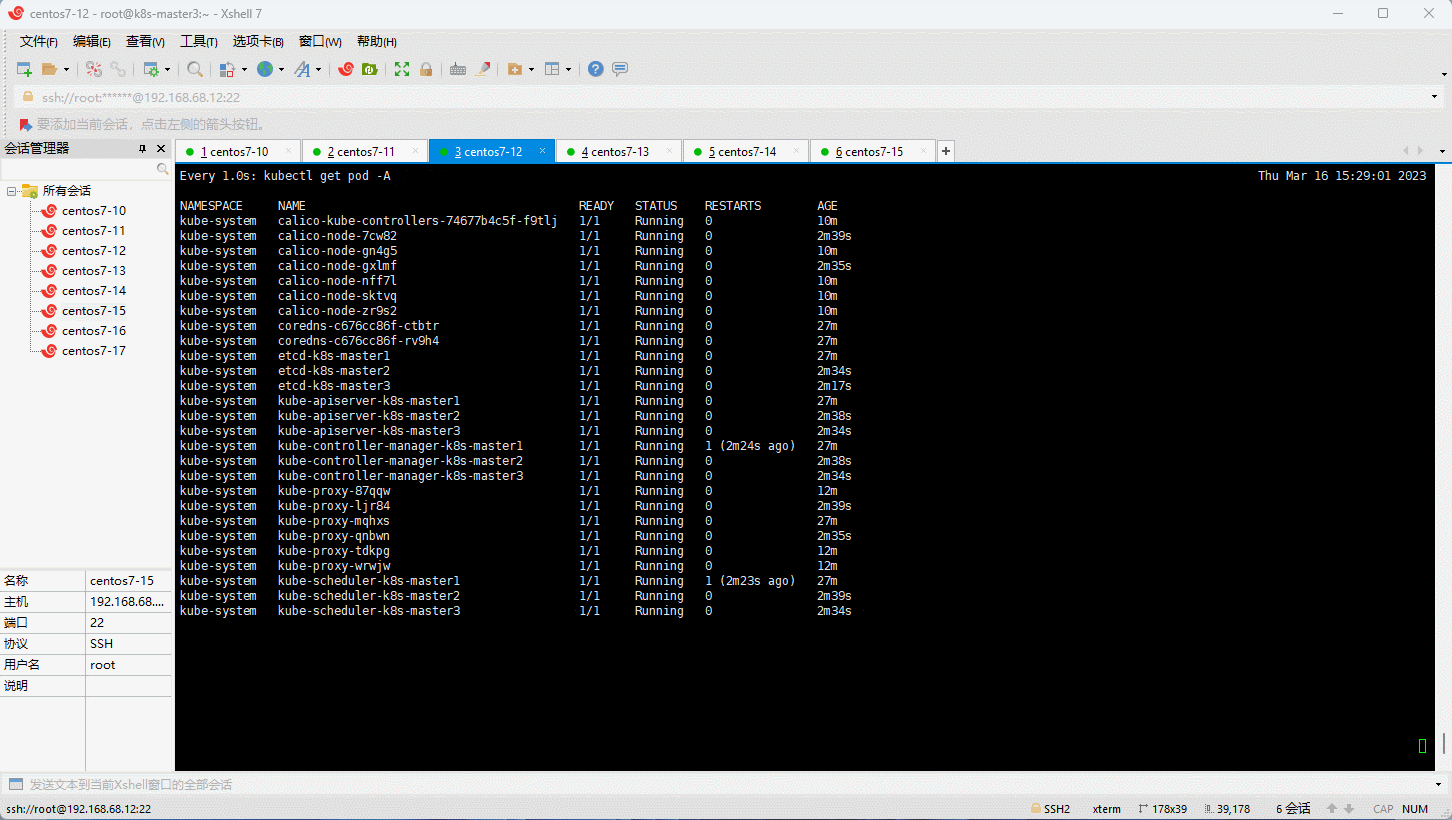
- 通过浏览器查看集群的状态:

6.11 设置 kube-proxy 的 ipvs 模式
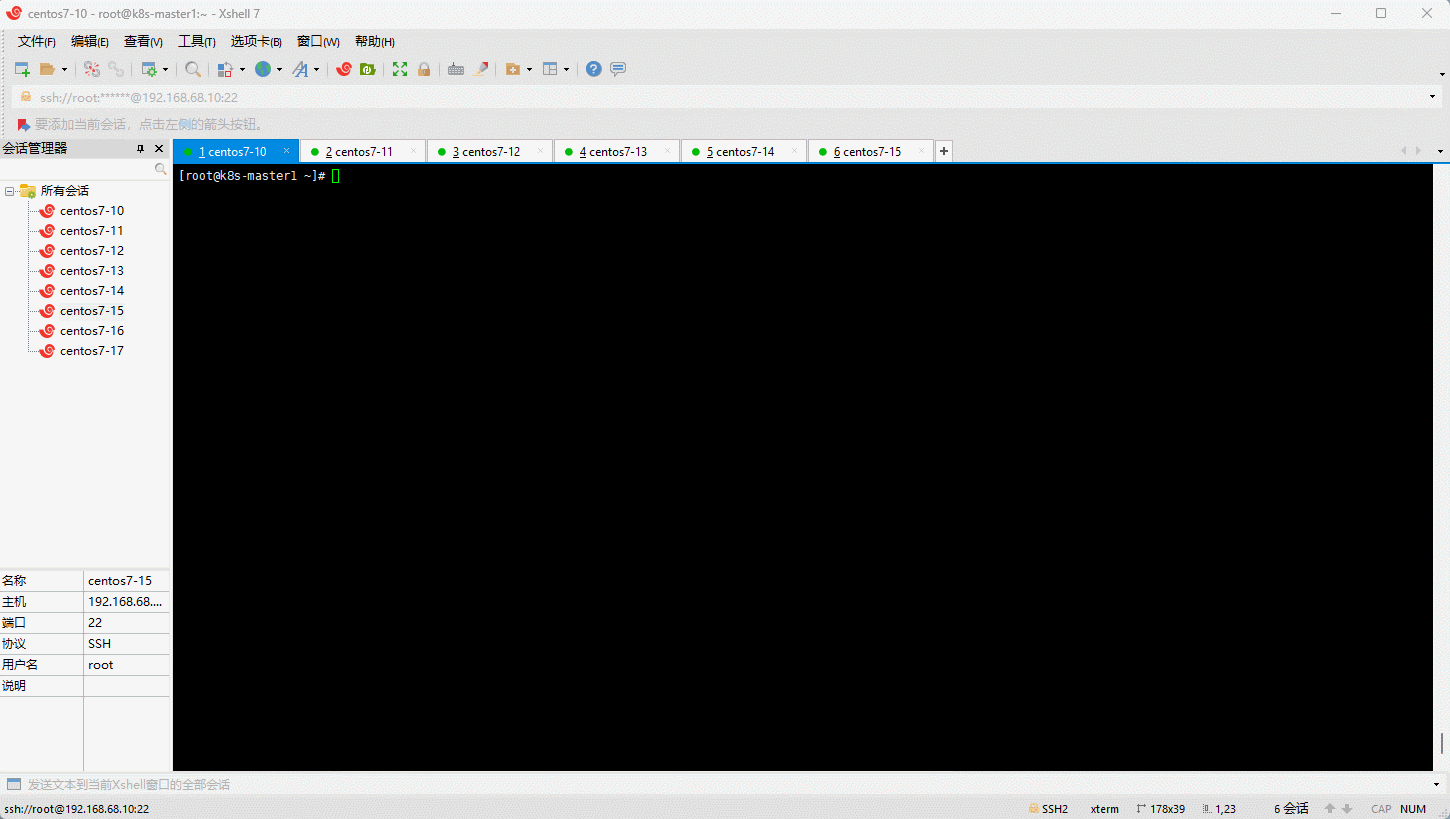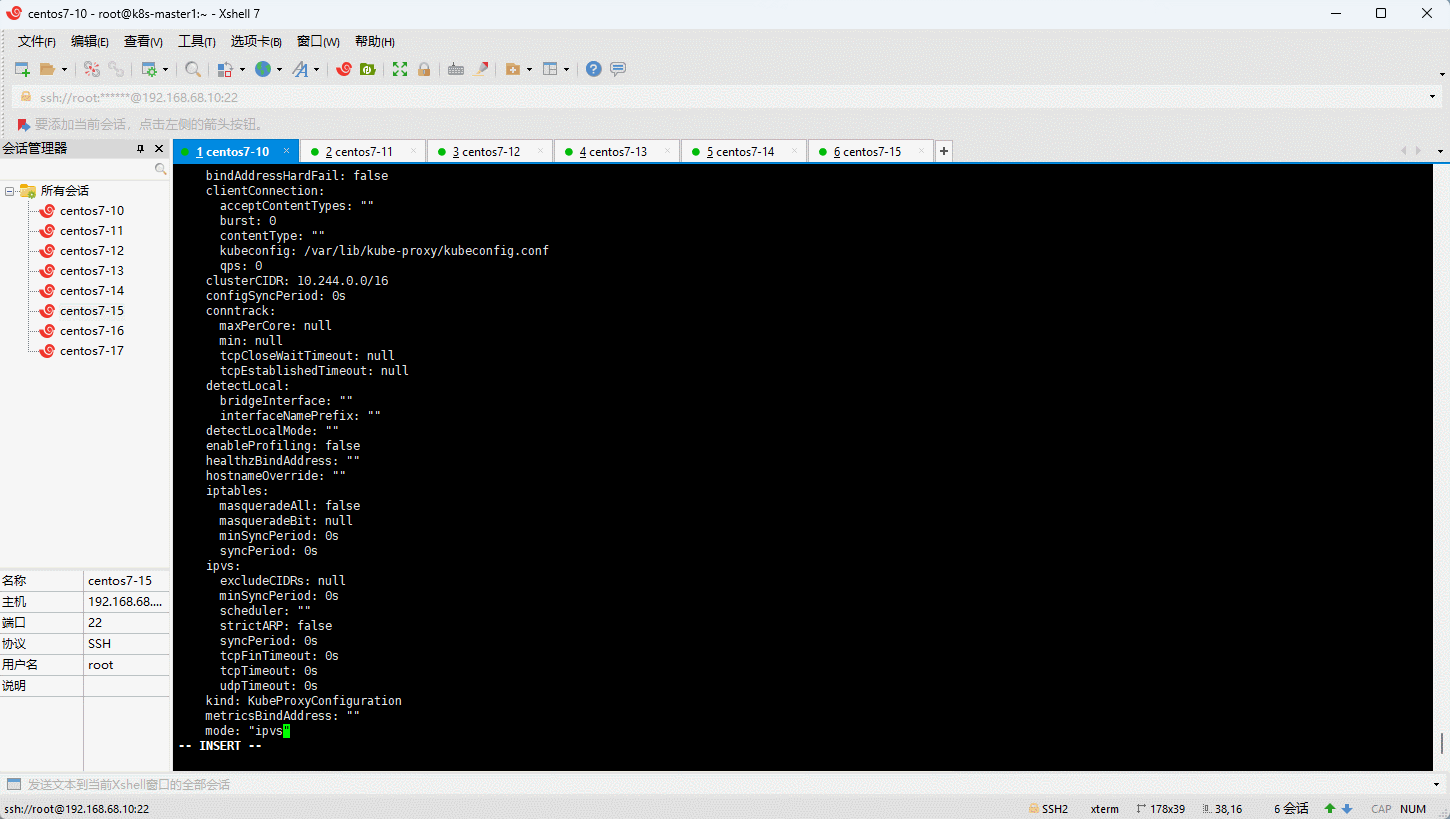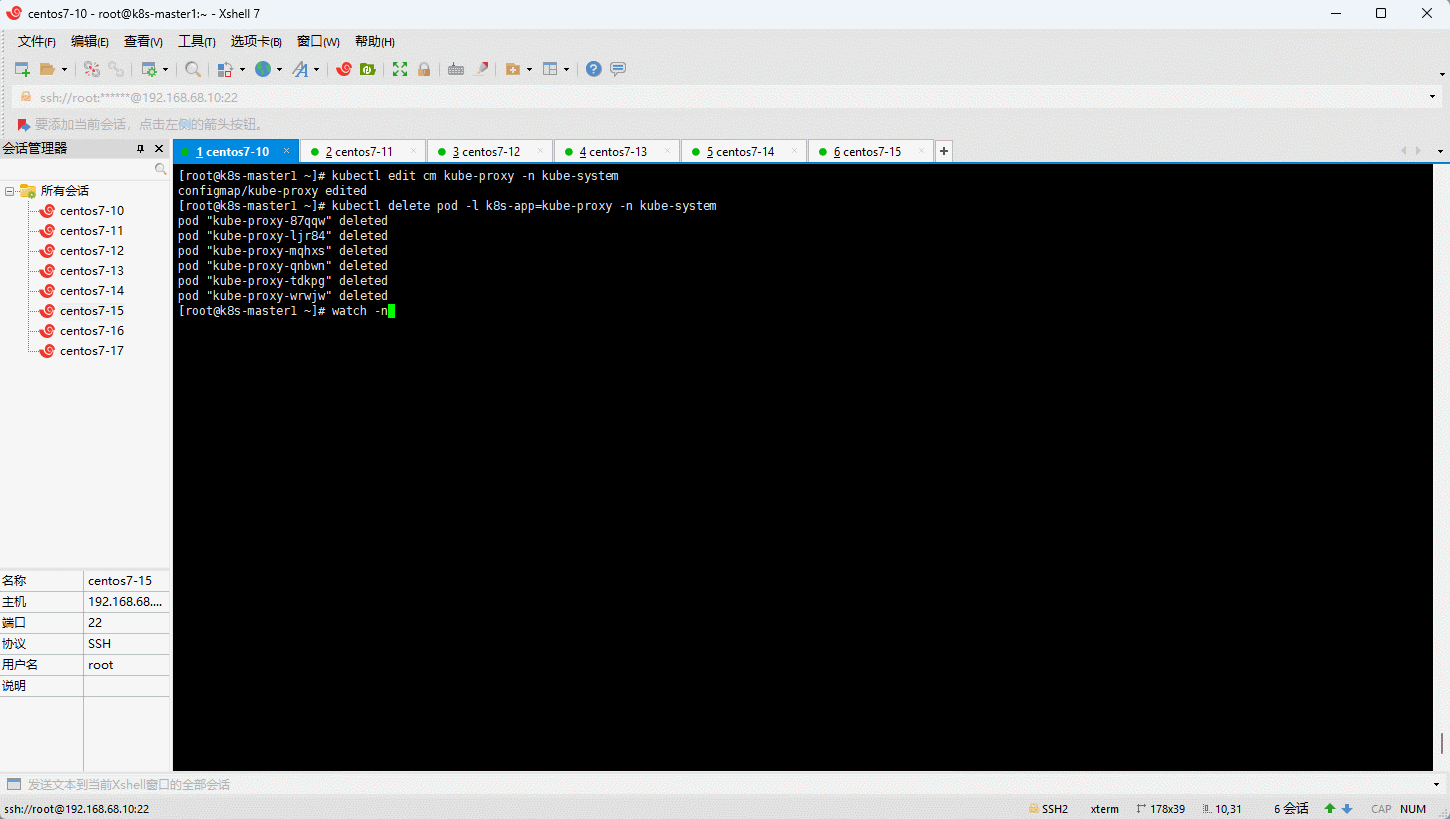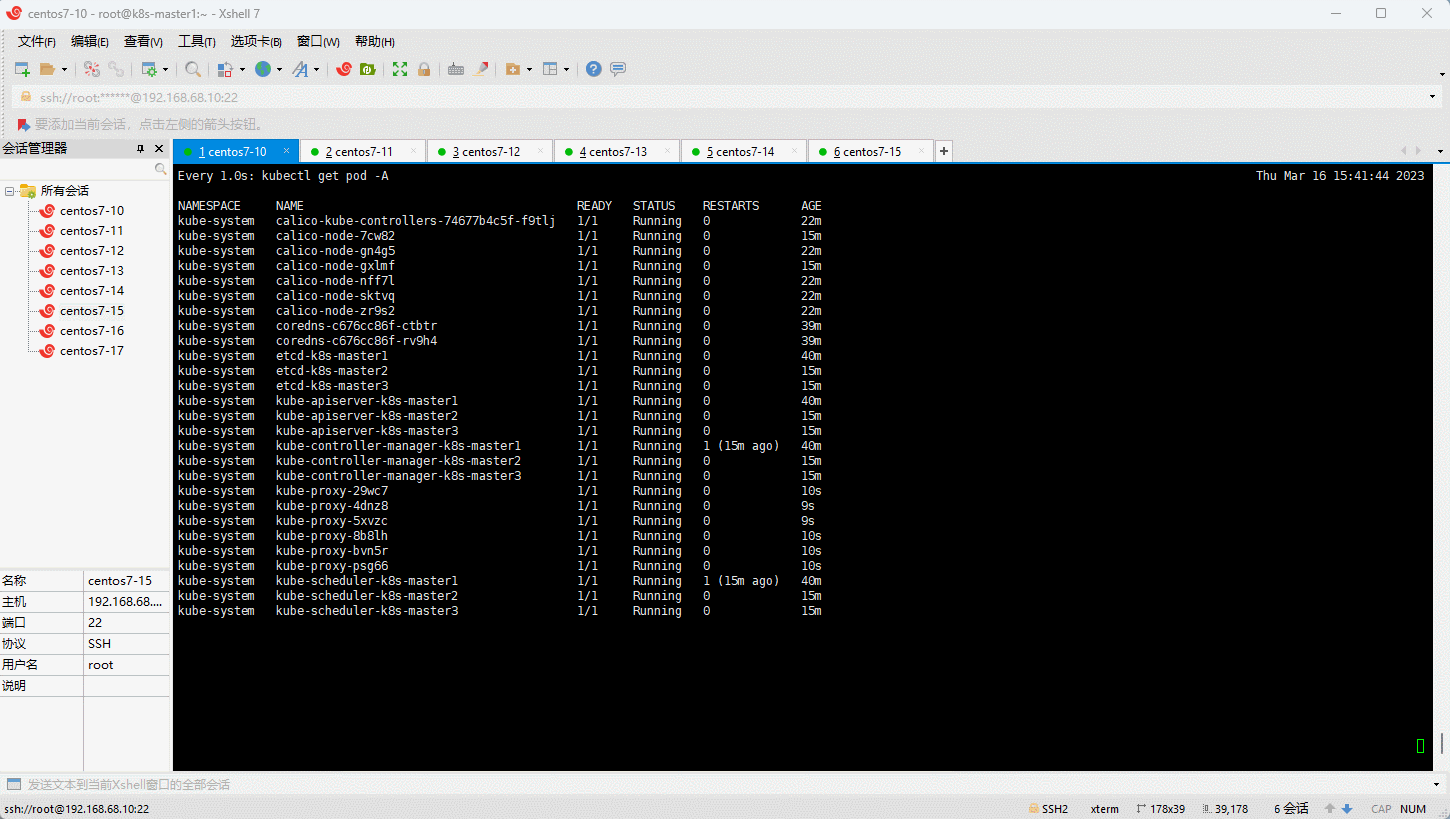
- 在任意 master 节点执行如下的命令即可:
# Please edit the object below. Lines beginning with a '#' will be ignored,
# and an empty file will abort the edit. If an error occurs while saving this file will be
# reopened with the relevant failures.
#
apiVersion: v1
data:
config.conf: |-
apiVersion: kubeproxy.config.k8s.io/v1alpha1
bindAddress: 0.0.0.0
bindAddressHardFail: false
clientConnection:
acceptContentTypes: ""
burst: 0
contentType: ""
kubeconfig: /var/lib/kube-proxy/kubeconfig.conf
qps: 0
clusterCIDR: 10.244.0.0/16
configSyncPeriod: 0s
conntrack:
maxPerCore: null
min: null
tcpCloseWaitTimeout: null
tcpEstablishedTimeout: null
detectLocal:
bridgeInterface: ""
interfaceNamePrefix: ""
detectLocalMode: ""
enableProfiling: false
healthzBindAddress: ""
hostnameOverride: ""
iptables:
masqueradeAll: false
masqueradeBit: null
minSyncPeriod: 0s
syncPeriod: 0s
ipvs:
excludeCIDRs: null
minSyncPeriod: 0s
scheduler: ""
strictARP: false
syncPeriod: 0s
tcpFinTimeout: 0s
tcpTimeout: 0s
udpTimeout: 0s
kind: KubeProxyConfiguration
metricsBindAddress: ""
mode: ""
nodePortAddresses: null
oomScoreAdj: null
portRange: ""
excludeCIDRs: null
minSyncPeriod: 0s
scheduler: ""
strictARP: false
syncPeriod: 0s
tcpFinTimeout: 0s
tcpTimeout: 0s
udpTimeout: 0s
kind: KubeProxyConfiguration
metricsBindAddress: ""
mode: ""
nodePortAddresses: null
oomScoreAdj: null
portRange: ""
bindAddressHardFail: false
clientConnection:
acceptContentTypes: ""
burst: 0
contentType: ""
kubeconfig: /var/lib/kube-proxy/kubeconfig.conf
qps: 0
clusterCIDR: 10.244.0.0/16
configSyncPeriod: 0s
conntrack:
maxPerCore: null
min: null
tcpCloseWaitTimeout: null
tcpEstablishedTimeout: null
detectLocal:
bridgeInterface: ""
interfaceNamePrefix: ""
detectLocalMode: ""
enableProfiling: false
healthzBindAddress: ""
hostnameOverride: ""
iptables:
masqueradeAll: false
masqueradeBit: null
minSyncPeriod: 0s
syncPeriod: 0s
ipvs:
excludeCIDRs: null
minSyncPeriod: 0s
scheduler: ""
strictARP: false
syncPeriod: 0s
tcpFinTimeout: 0s
tcpTimeout: 0s
udpTimeout: 0s
kind: KubeProxyConfiguration
metricsBindAddress: ""
mode: "ipvs" # 修改此处
....

6.12 Master 节点去污
- 默认情况下,使用 kubeadm 安装 Kubernetes 集群的时候,Master 节点会带有污点,所以可以使用如下的命令进行去污:
6.13 测试
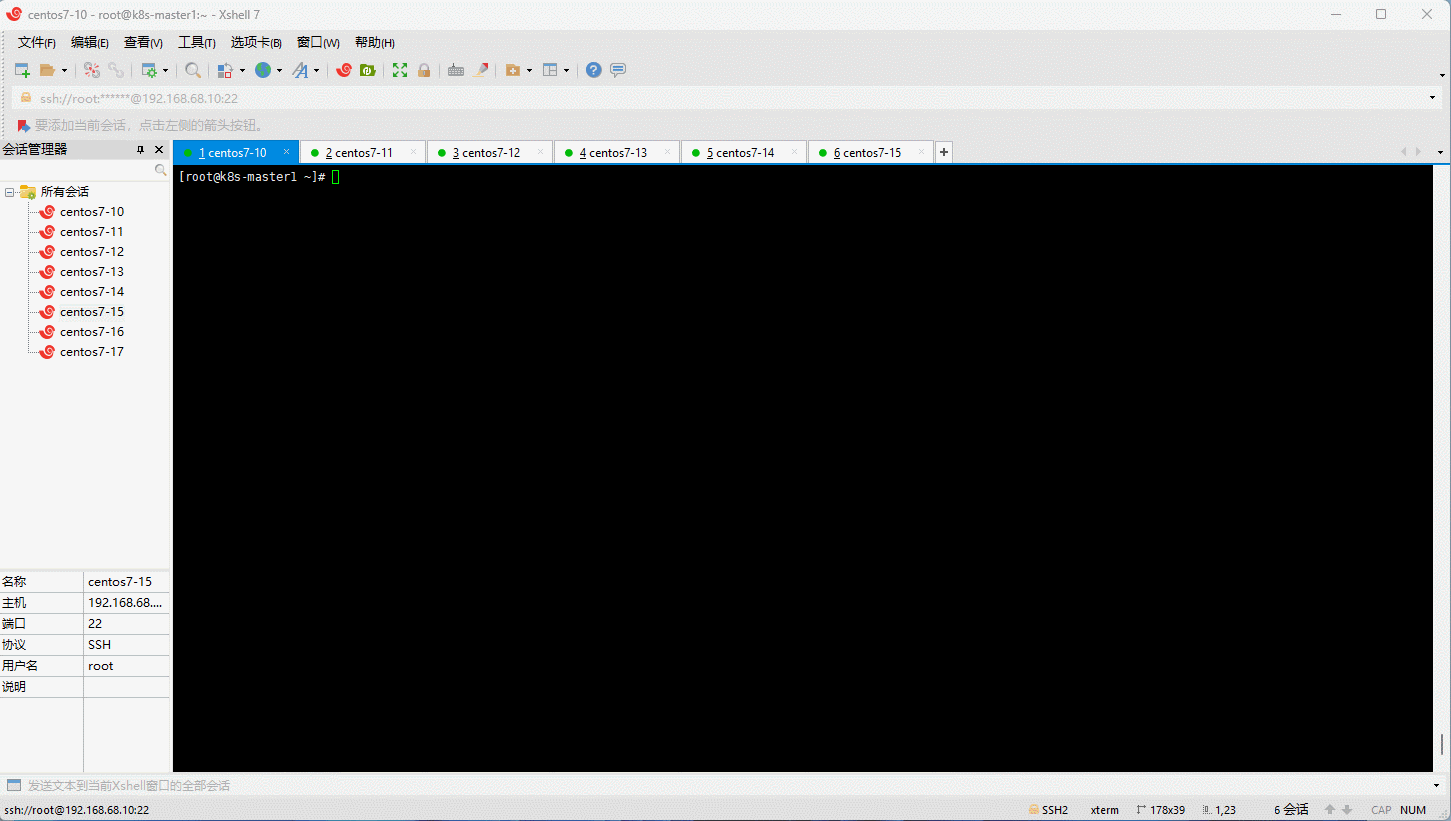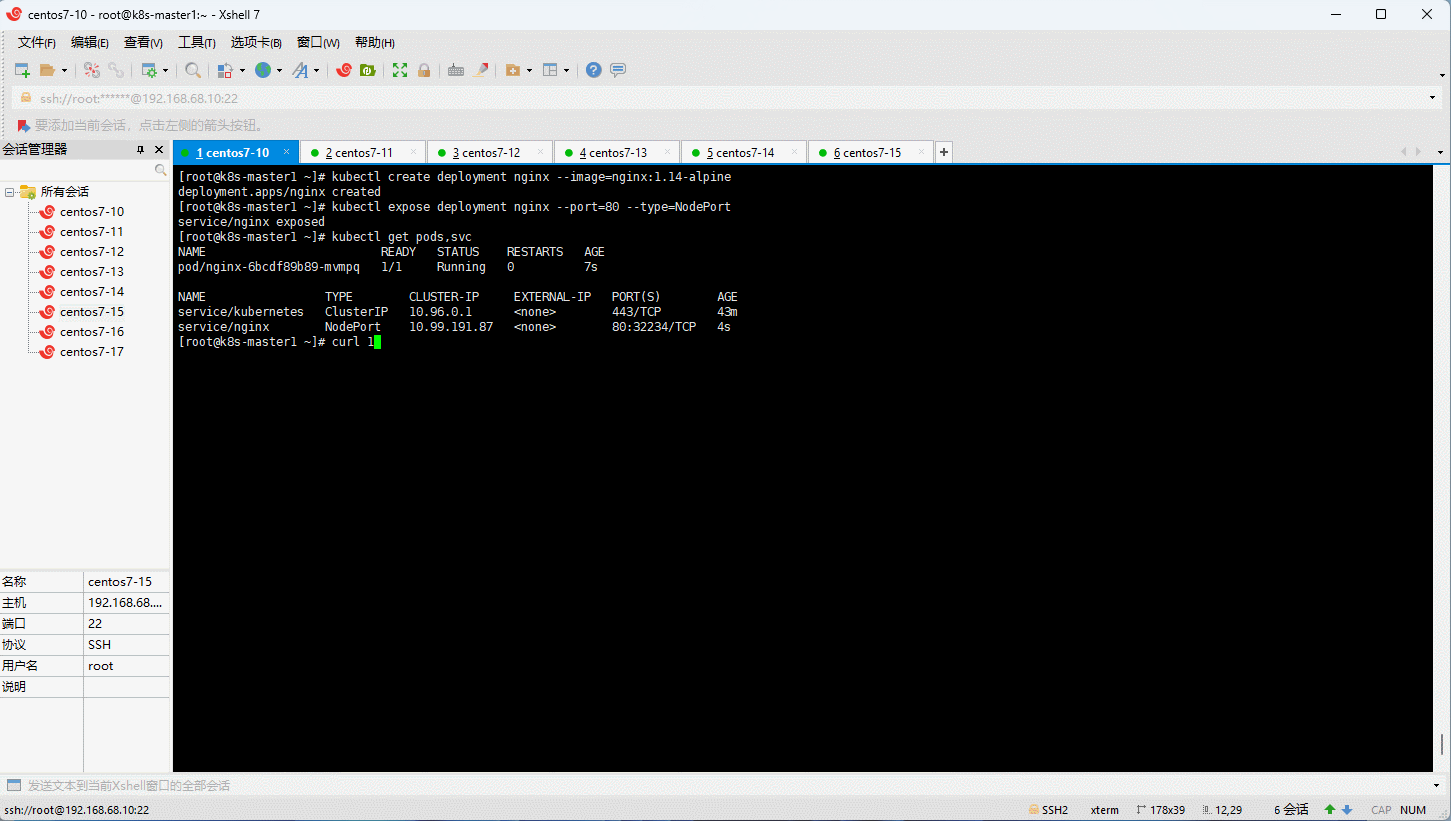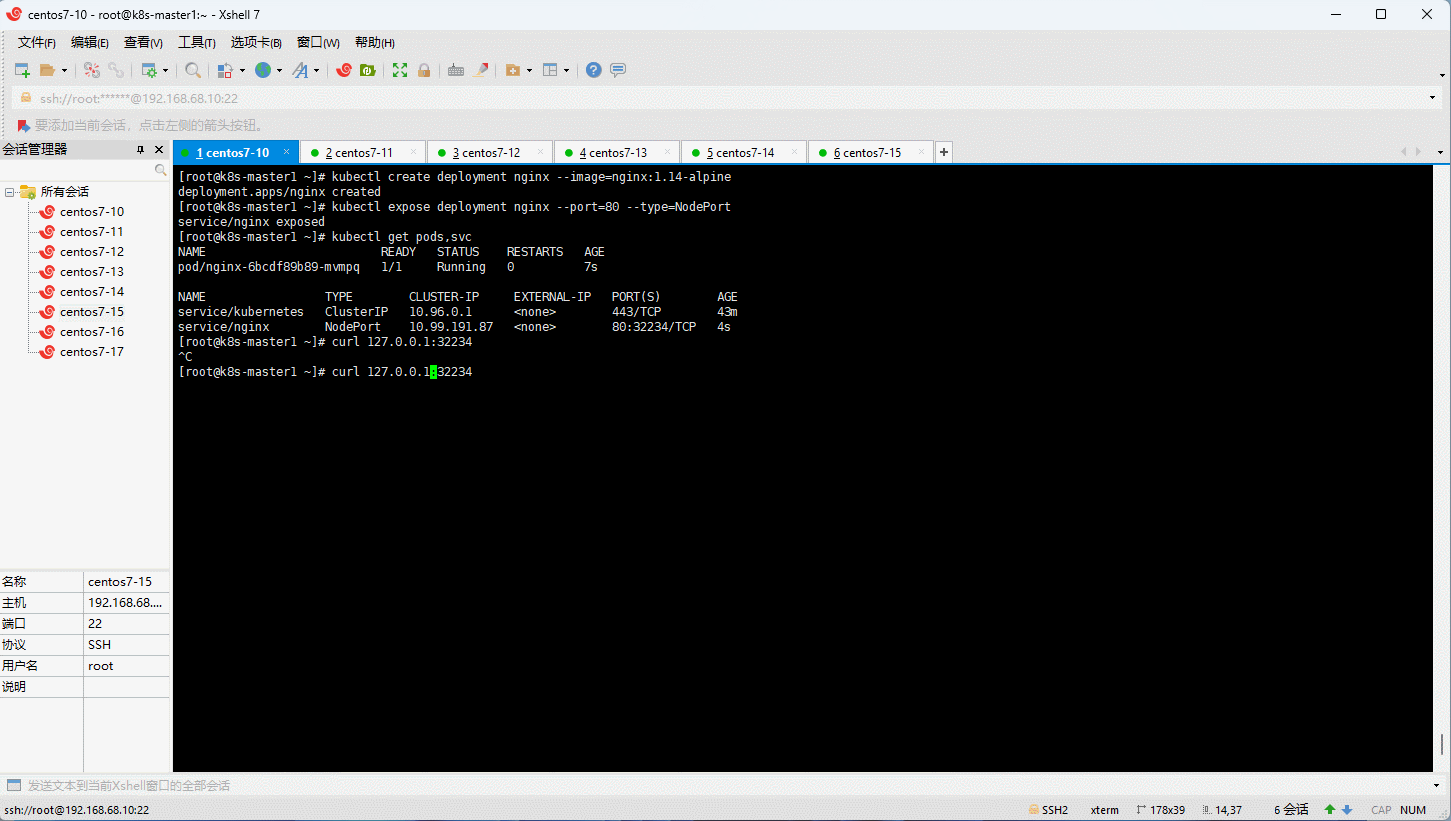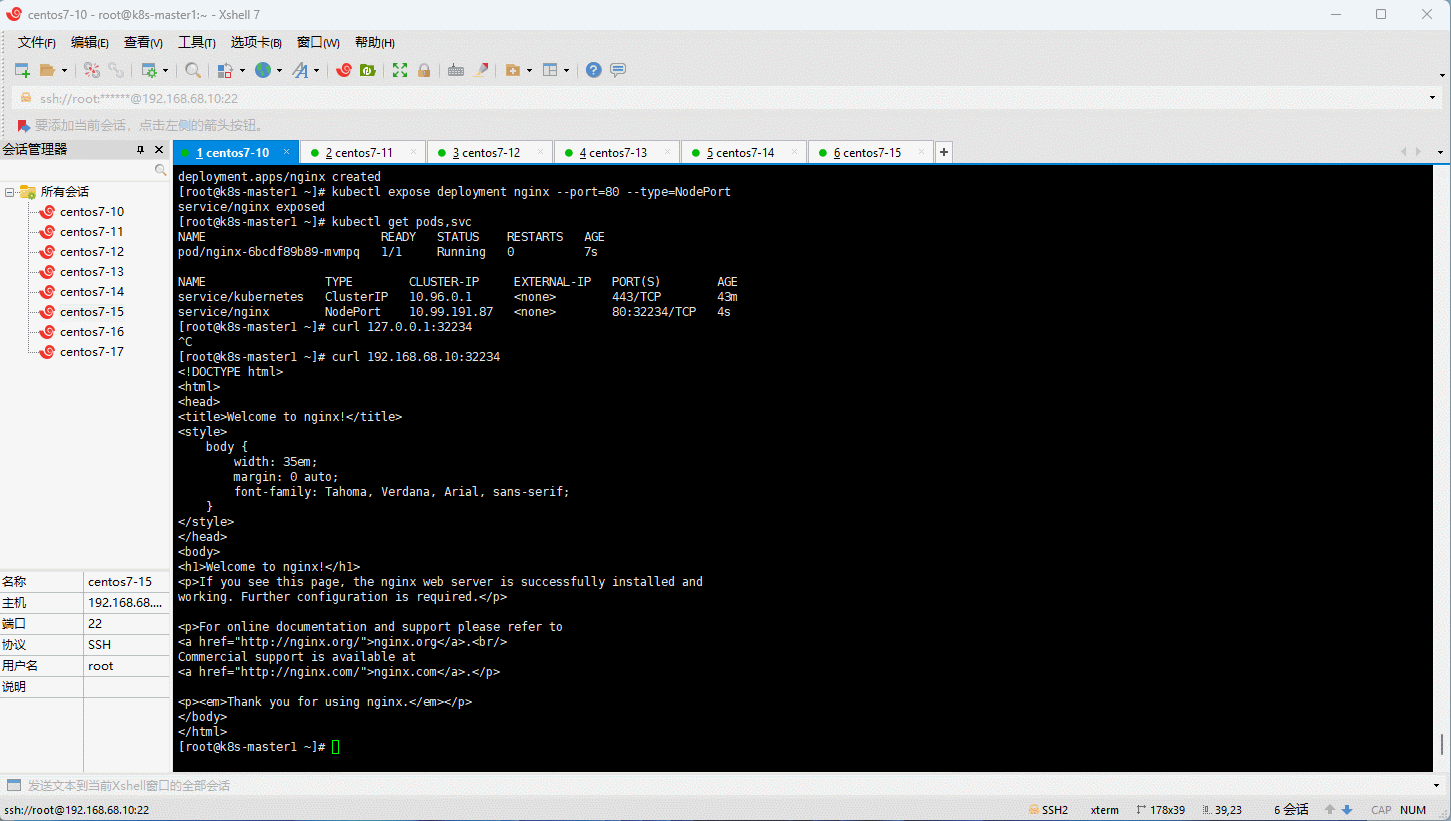
- 使用 Nginx 来测试一下是否安装成功:

更新: 2024-07-15 02:32:02
原文: https://www.yuque.com/fairy-era/yg511q/cbtgqqthm6m4nk5v